「3Dで動作する魔法の筆:Blended-NeRFはニューラル放射場におけるゼロショットオブジェクト生成を行うAIモデルです」
AI model Blended-NeRF is a magical brush that works in 3D to generate zero-shot object creation in the neural radiance field.


ここ数年は、さまざまな分野でユーレカの瞬間が続いています。私たちは、革新的な手法が登場し、巨大な進歩がもたらされるのを目にしてきました。言語モデルにおけるChatGPT、生成モデルにおける安定拡散、コンピュータグラフィックスとビジョンにおけるニューラル放射場(NeRF)など、その中でも特に注目されたものです。
NeRFは、私たちが3Dシーンを表現し、描画する方法を革新しました。NeRFは、連続的な3Dボリュームとしてシーンを表現し、ジオメトリと外観情報をエンコードします。従来の明示的な表現とは異なり、NeRFはニューラルネットワークを通じてシーンの特性を捉え、新しい視点の合成や複雑なシーンの正確な再構築を可能にします。シーン内の各点のボリューメトリック密度と色をモデリングすることにより、NeRFは印象的な写真のようなリアリズムと詳細な再現性を実現しています。
NeRFの多様性とポテンシャルは、その能力を向上させ、制約を解消するために広範な研究が行われています。NeRFの推論の高速化や動的シーンの処理、シーンの編集を可能にするための技術が提案され、この新しい表現の適用範囲と影響力がさらに拡大しています。
- 「MosaicMLは、AIユーザーが精度を向上し、コストを削減し、時間を節約するのを支援します」
- 「自然界がコンピュータビジョンの未来を支える」
- ダブルマシンラーニングの簡略化:パート1 – 基本的な因果推論の応用
しかし、これらの努力にもかかわらず、NeRFには実用的なシナリオでの適応性を妨げる制約がまだ存在します。シーンの編集はその中でも特に重要な例です。これは、NeRFの暗黙的な性質と異なるシーンコンポーネントの明示的な区別の欠如により、困難です。
他のメッシュなどの明示的な表現を提供する方法とは異なり、NeRFは形状、色、材料の明確な区別を提供しません。さらに、NeRFシーンに新しいオブジェクトをブレンドするには、複数のビュー間での一貫性が必要であり、編集プロセスがさらに複雑になります。
3Dシーンをキャプチャする能力は、方程式の一部にすぎません。出力を編集できる能力も同様に重要です。デジタル画像やビデオは編集が比較的容易であるため、最近のテキストからXへのAIモデルによって特に簡単に編集できます。では、それと同じ力をNeRFシーンにもたらす方法は何でしょうか?それがBlended-NeRFです。
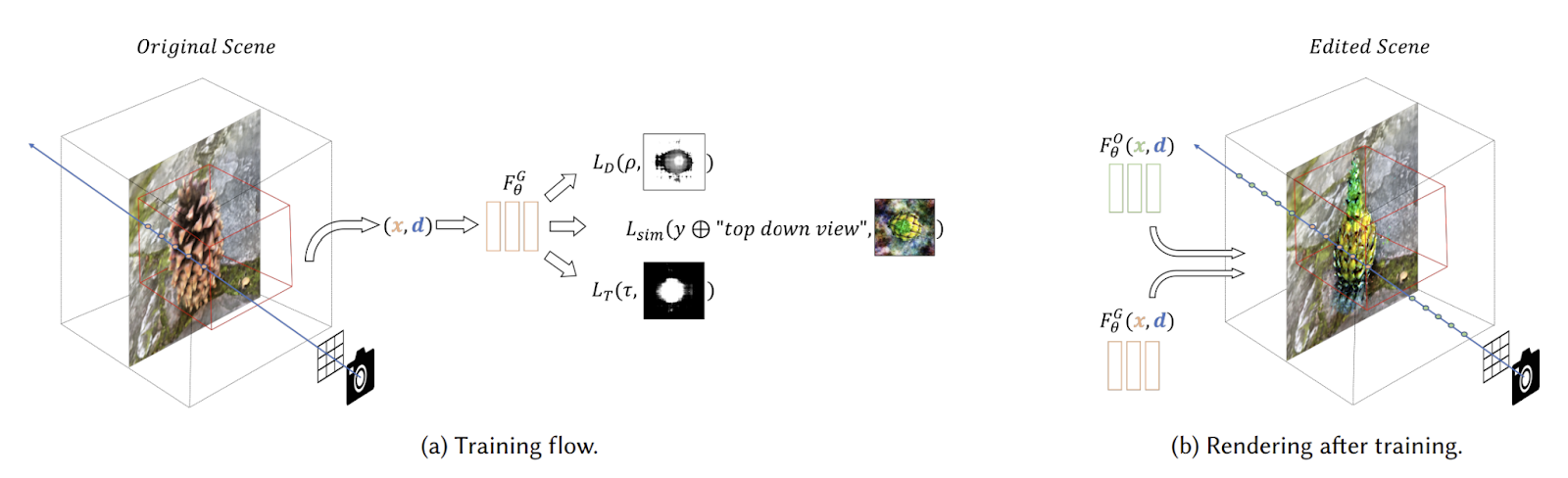
Blended-NeRFは、テキストプロンプトや画像パッチによって誘導されるNeRFシーンのROIベースの編集手法です。既存の特徴空間や2次元マスクのセットを必要とせずに、実世界のシーンの任意の領域を編集することができます。
この手法の目標は、既存のシーンとシームレスにブレンドする自然な見た目とビューの一貫性を生成することです。さらに重要なことに、Blended-NeRFは特定のクラスやドメインに制約されず、物体の挿入/置換、オブジェクトのブレンド、テクスチャの変換など、複雑なテキストによる操作を可能にします。
これらの機能をすべて実現することは簡単ではありません。そのため、Blended-NeRFは、CLIPなどの事前学習された言語-画像モデルと、既存のNeRFシーン上に初期化されたNeRFモデルを利用して、シーンの関心領域(ROI)に新しいオブジェクトを合成およびブレンドするためのジェネレータとして機能します。
CLIPモデルは、ユーザーが提供したテキストプロンプトや画像パッチに基づいて生成プロセスを誘導し、シーンと自然にブレンドするさまざまな3Dオブジェクトの生成を可能にします。残りのシーンを保持しながら一般的な局所的な編集を可能にするために、ユーザーにはシンプルなGUIが提示され、直感的なフィードバックのために深度情報を利用してNeRFシーン内の3Dボックスをローカライズすることができます。シームレスなブレンドのために、新しい距離スムージング操作が提案されており、各カメラ光線に沿ってサンプリングされた3Dポイントをブレンドすることで、元の放射場と合成された放射場をマージします。
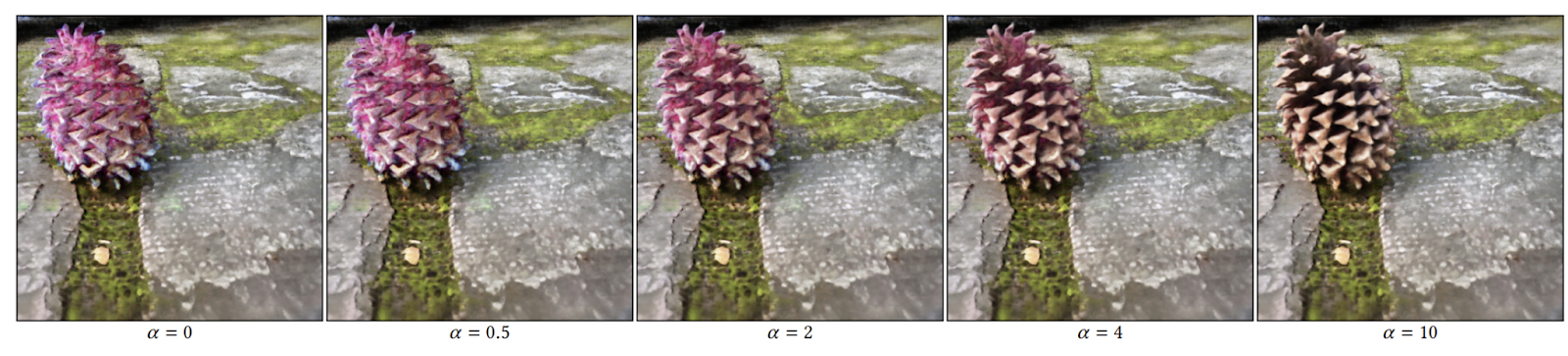
しかし、もう1つ問題がありました。このパイプラインを使用してNeRFシーンを編集すると、品質が低く、矛盾した結果が得られます。この問題に対処するために、Blended-NeRFの研究者たちは、深度正則化、ポーズサンプリング、方向依存のプロンプトなど、前の研究で提案された拡張と事前知識を取り入れ、より現実的で統一感のある結果を得ることを目指しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





