「AIがPowerPointと出会う」
AI meets PowerPoint
Streamlit、LangChain、およびYahoo Financeを使用した企業調査プレゼンテーションの自動化
この記事は、2023年8月2日にStreamlitブログで最初に公開されました。
はじめに
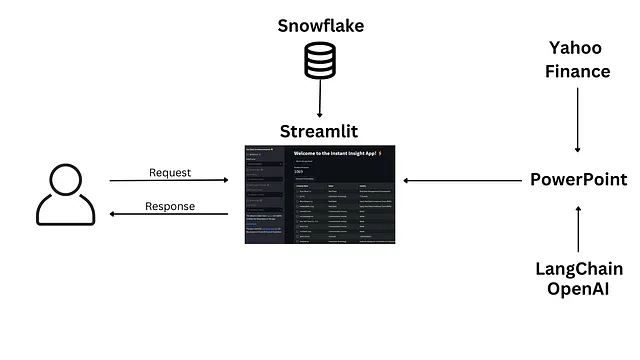
この記事では、2023年5月のSnowflake Summitで3位を獲得したオープンソースプロジェクトであるInstant Insightアプリのバックエンドの仕組みについて説明します。このWebアプリは、Yahoo FinanceとChatGPTのデータを使用して、企業の調査とバリュープロポジションのスライドを自動生成するように設計されています。
設定のために、B2B SaaS企業で営業を行い、数百の見込み客に以下の製品を提供していると想像してみましょう:会計および計画ソフトウェア、CRM、チャットボット、およびクラウドデータストレージ。見込み客の調査、財務およびSWOT分析、競争環境の調査、バリュープロポジションの作成、チームとのプレゼンテーションの共有など、タスクがあります。見込み客のデータはSnowflakeデータベースに格納され、CRMシステムに供給されます。Instant Insightアプリを使用して、さまざまなパラメータで見込み客を迅速にフィルタリングすることができます。次に、プレゼンテーションに含めたい見込み客を選択し、プレゼンテーションの生成ボタンをクリックします。1分以内に、調査を含むPowerPointプレゼンテーションがダウンロード用に準備されます。
アプリの高レベルのアーキテクチャは次のようになります:
- 腫瘍の起源の解読:MITとDana-Farber研究者が機械学習を活用して遺伝子配列を分析する方法
- AIは人間過ぎるようになったのでしょうか?Google AIの研究者は、LLMsがツールのドキュメントだけでMLモデルやAPIを利用できるようになったことを発見しました!
- 「UCLA研究者がGedankenNetを紹介:物理法則や思考実験から学ぶ自己教示AIモデルが計算機画像処理を進化させる」
目次
- StreamlitアプリをSnowflakeに接続する
- 動的なフィルタと対話型テーブルを持つUIを作成する
- Yahoo Financeから企業データを取得する
- Plotlyを使用してグラフを作成する
- Clearbit APIを使用して企業ロゴを取得する
- LangChainとGPT 3.5 LLMを使用してSWOT分析とバリュープロポジションを作成する
- GPTの応答から構造化データを抽出する
- python-pptxを使用してスライドを生成する
StreamlitアプリをSnowflakeに接続する
まず、データを取得します。これには、Snowflakeコネクタを使用します:
import snowflake.connector# StreamlitのシークレットからSnowflakeの認証情報を取得するSNOWFLAKE_ACCOUNT = st.secrets["snowflake_credentials"]["SNOWFLAKE_ACCOUNT"]SNOWFLAKE_USER = st.secrets["snowflake_credentials"]["SNOWFLAKE_USER"]SNOWFLAKE_PASSWORD = st.secrets["snowflake_credentials"]["SNOWFLAKE_PASSWORD"]SNOWFLAKE_DATABASE = st.secrets["snowflake_credentials"]["SNOWFLAKE_DATABASE"]SNOWFLAKE_SCHEMA = st.secrets["snowflake_credentials"]["SNOWFLAKE_SCHEMA"]@st.cache_resourcedef get_database_session(): """データベースセッションオブジェクトを返す。""" return snowflake.connector.connect( account=SNOWFLAKE_ACCOUNT, user=SNOWFLAKE_USER, password=SNOWFLAKE_PASSWORD, database=SNOWFLAKE_DATABASE, schema=SNOWFLAKE_SCHEMA, )@st.cache_datadef get_data(): """Snowflakeからデータを含むpandas DataFrameを返す。""" query = 'SELECT * FROM us_prospects;' cur = conn.cursor() cur.execute(query) # pandas DataFrameとして結果を取得 column_names = [col[0] for col in cur.description] data = cur.fetchall() df = pd.DataFrame(data, columns=column_names) # Snowflakeへの接続を閉じる cur.close() conn.close() return df# Snowflakeからデータを取得するconn = get_database_session()df = get_data(conn)Snowflakeアカウント、ユーザー名、パスワード、データベース名、およびスキーマなどの機密データは、シークレットに格納され、st.secretsを呼び出して取得されます(詳細はこちらを参照してください)。
次に、2つの関数を定義します:
get_database_session()は接続オブジェクトを初期化しますget_data()はSQLクエリを実行し、pandas DataFrameを返しますus_prospectsテーブルからすべてのデータを取得するために、単純なSELECT * クエリを使用します。
動的フィルターとインタラクティブなテーブルを使用してUIを作成する
では、いくつかのStreamlitの魔法を使ってアプリのフロントエンドを開発しましょう。動的な複数選択フィルターを含むサイドバーパネルを作成し、ユーザーがすべての値を選択するためのチェックボックスを追加します。
アプリ内のフィルターは順次動作します。ユーザーは上から下に個別に適用することが想定されています。最初のフィルターが適用されると、2番目のフィルターが利用可能になり、関連するラベルのみが含まれます。各フィルターが適用されると、基になるDataFrameが事前にフィルタリングされ、num_of_pros変数が選択された見込み客の数を反映するように更新されます。
フィルターの動作を確認してください:
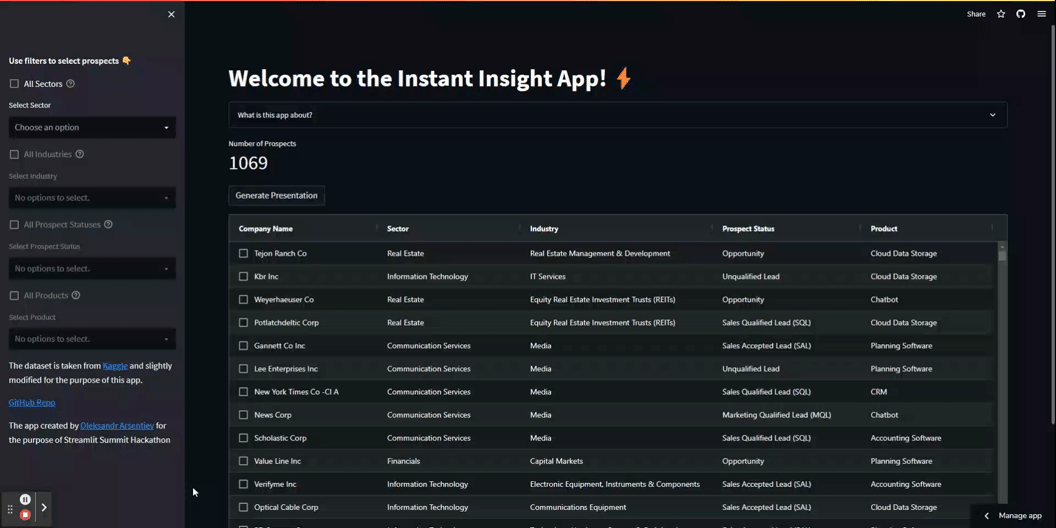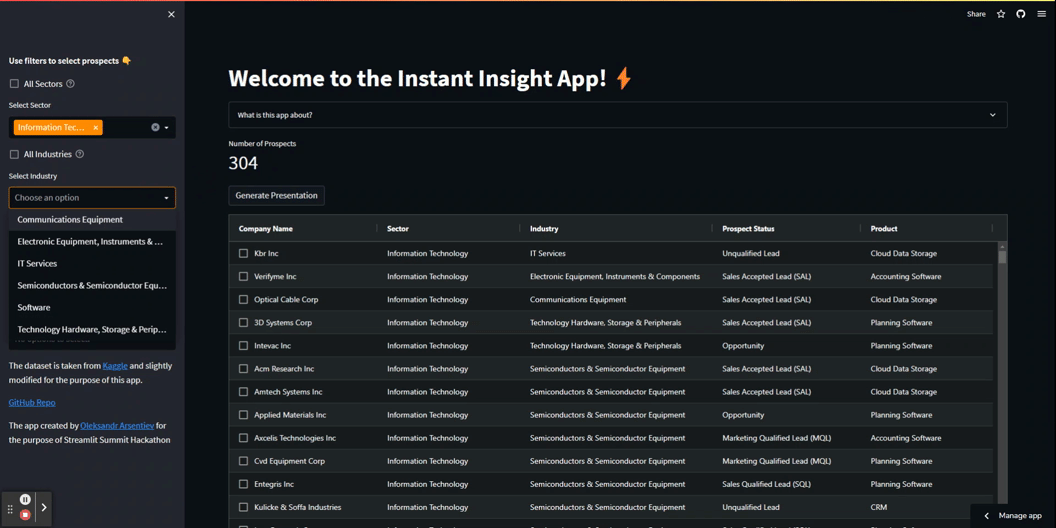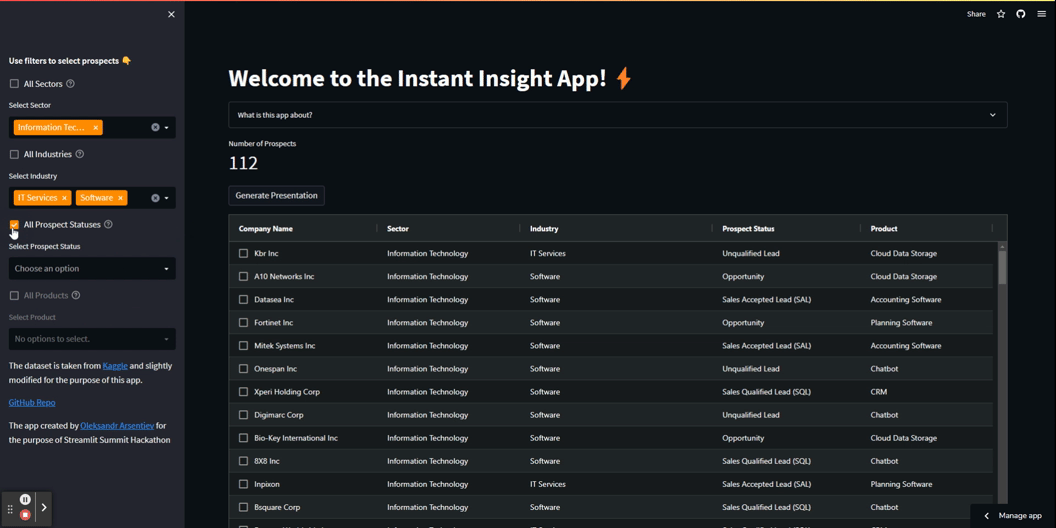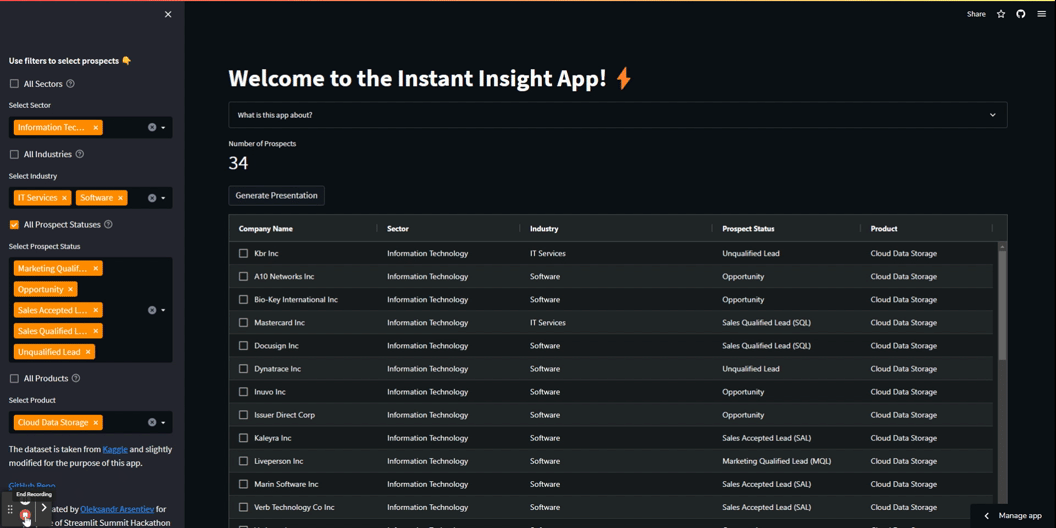
以下は最初の2つのフィルターを作成するためのコードです:
# サイドバーフィルターを作成st.sidebar.write('**フィルターを使用して見込み客を選択** 👇')sector_checkbox = st.sidebar.checkbox('全てのセクター', help='全てのセクターを選択するにはこのボックスをチェックしてください')unique_sector = sorted(df['SECTOR'].unique())# 全てのセクターチェックボックスがチェックされている場合は全てのセクターを選択するif sector_checkbox: selected_sector = st.sidebar.multiselect('セクターを選択', unique_sector, unique_sector)else: selected_sector = st.sidebar.multiselect('セクターを選択', unique_sector)# ユーザーがセクターを選択した場合は全ての業種チェックボックスをチェックできるようにするif len(selected_sector) > 0: industry_checkbox = st.sidebar.checkbox('全ての業種', help='全ての業種を選択するにはこのボックスをチェックしてください') # データをフィルタリングする df = df[(df['SECTOR'].isin(selected_sector))] # 選択された見込み客の数を表示する num_of_pros = str(df.shape[0])else: industry_checkbox = st.sidebar.checkbox('全ての業種', help='全ての業種を選択するにはこのボックスをチェックしてください', disabled=True) # 選択された見込み客の数を表示する num_of_pros = str(df.shape[0])# 全ての業種チェックボックスがチェックされている場合は全ての業種を選択するunique_industry = sorted(df['INDUSTRY'].loc[df['SECTOR'].isin(selected_sector)].unique())if industry_checkbox: selected_industry = st.sidebar.multiselect('業種を選択', unique_industry, unique_industry)else: selected_industry = st.sidebar.multiselect('業種を選択', unique_industry)# ユーザーが業種を選択した場合は全てのステータスチェックボックスをチェックできるようにするif len(selected_industry) > 0: status_checkbox = st.sidebar.checkbox('全ての見込み客ステータス', help='全ての見込み客ステータスを選択するにはこのボックスをチェックしてください') # データをフィルタリングする df = df[(df['SECTOR'].isin(selected_sector)) & (df['INDUSTRY'].isin(selected_industry))] # 選択された見込み客の数を表示する num_of_pros = str(df.shape[0])else: status_checkbox = st.sidebar.checkbox('全ての見込み客ステータス', help='全ての見込み客ステータスを選択するにはこのボックスをチェックしてください', disabled=True)次に、AgGridを使用してデータを表示するインタラクティブなテーブルを作成し、ユーザーがスライド生成の見込み客を選択できるようにします(詳細はこちらをご覧ください)。
各テーブル行にチェックボックスを配置し、ユーザーが1つの行のみを選択できるようにします。また、カスタムの列幅とテーブルの高さを設定します。
以下はそのコードです:
from st_aggrid import AgGridfrom st_aggrid.grid_options_builder import GridOptionsBuilderfrom st_aggrid import GridUpdateMode, DataReturnModeimport pandas as pd# AgGridの動的テーブルを作成し、設定を行うgb = GridOptionsBuilder.from_dataframe(df)gb.configure_selection(selection_mode="single", use_checkbox=True)gb.configure_column(field='Company Name', width=270)gb.configure_column(field='Sector', width=260)gb.configure_column(field='Industry', width=350)gb.configure_column(field='Prospect Status', width=270)gb.configure_column(field='Product', width=240)gridOptions = gb.build()response = AgGrid( df, gridOptions=gridOptions, height=600, update_mode=GridUpdateMode.SELECTION_CHANGED, data_return_mode=DataReturnMode.FILTERED_AND_SORTED, fit_columns_on_grid_load=False, theme='alpine', allow_unsafe_jscode=True)# 選択された行を取得response_df = pd.DataFrame(response["selected_rows"])Yahoo Financeから企業データを取得する
ユーザーが研究のために企業を選択したとします。そして、それに関するいくつかのデータを収集する必要があります。主なデータソースはYahoo Financeであり、これには非公式のYahoo Finance APIエンドポイントへのPythonインターフェースであるyahooqueryライブラリを使用します。このライブラリを使用すると、ユーザーはYahoo Financeのフロントエンドを介してほぼすべての表示データを取得できます。
以下は、Yahoo Financeデータを使用した概要スライドです:

yahooqueryのTickerクラスを使用して、選択した企業に関する数量的および質的なデータを取得します。企業の銘柄記号を引数として渡し、必要なプロパティを呼び出して返された辞書からデータを取得します。
以下は、企業概要スライドのデータを取得するコードです:
from yahooquery import Ticker
selected_ticker = 'ABC'
ticker = Ticker(selected_ticker)
# 企業情報を取得
name = ticker.price[selected_ticker]['shortName']
sector = ticker.summary_profile[selected_ticker]['sector']
industry = ticker.summary_profile[selected_ticker]['industry']
employees = ticker.summary_profile[selected_ticker]['fullTimeEmployees']
country = ticker.summary_profile[selected_ticker]['country']
city = ticker.summary_profile[selected_ticker]['city']
website = ticker.summary_profile[selected_ticker]['website']
summary = ticker.summary_profile[selected_ticker]['longBusinessSummary']このアプリは、Yahoo Financeのデータを使用して、時間の経過に伴う財務パフォーマンスを示すグラフを作成します。1つのスライドには、株価、総負債、総収益、およびEBITDAなどの基本的な財務指標が表示されます。
プロットについては後で説明します。今は、Yahoo Financeから財務データを取得することに焦点を当てましょう。関数get_stock()とget_financials()は、関連する財務指標を持つデータフレームを返します。株価データは他の財務指標とは別に保存されているため、2つのプロパティを呼び出す必要があります:
ticker.history()は、指定されたシンボルの過去の価格データを取得します(ここでドキュメントを読む)ticker.all_financial_data()は、収益計算書、貸借対照表、キャッシュフロー、評価指標などを含むすべての財務データを取得します(ここでドキュメントを読む)
以下は、過去の株価、収益、総負債、およびEBITDAの4つのデータフレームを生成するために使用されるコードです:
from yahooquery import Ticker
import pandas as pd
def get_stock(ticker, period, interval):
"""Yahoo Financeから株価データを取得する関数。銘柄、期間、インターバルを引数として受け取り、データフレームを返す"""
hist_df = ticker.history(period=period, interval=interval)
hist_df = hist_df.reset_index()
# 列名を大文字にする
hist_df.columns = [x.capitalize() for x in hist_df.columns]
return hist_df
def get_financials(df, col_name, metric_name):
"""データフレームから財務指標を取得する関数。データフレーム、列名、指標名を引数として受け取り、データフレームを返す"""
metric = df.loc[:, ['asOfDate', col_name]]
metric_df = pd.DataFrame(metric).reset_index()
metric_df.columns = ['Symbol', 'Year', metric_name]
return metric_df
selected_ticker = 'ABC'
ticker = Ticker(selected_ticker)
# すべての財務データを取得
fin_df = ticker.all_financial_data()
# 選択した銘柄の過去5年間の株価データフレームを作成
stock_df = get_stock(ticker=ticker, period='5y', interval='1mo')
# 収益、総負債、EBITDAのデータフレームを作成
rev_df = get_financials(df=fin_df, col_name='TotalRevenue', metric_name='Total Revenue')
debt_df = get_financials(df=fin_df, col_name='TotalDebt', metric_name='Total Debt')
ebitda_df = get_financials(df=fin_df, col_name='NormalizedEBITDA', metric_name='EBITDA')Yahoo Financeからのデータは、競合他社分析のための別のスライドでも使用されます。この分析では、企業のパフォーマンスを競合他社と比較します。これには総収益と売上高に対するS&A(販売総則および一般管理費)の割合の2つの指標が使用されます。これらの指標は収益計算書に含まれているため、ticker.income_statement()プロパティを使用してDataFrameを取得します(詳細はこちらを参照)。
extract_comp_financials()関数は、収益計算書のDataFrameから総収益とS&A(販売総則および一般管理費)を取得し、2022年のデータのみを保持します。売上高に対するS&Aの割合は即座に利用できないため、S&Aを収益で割り、100を乗算して手動で計算します。
この関数は、会社名をキーとし、ティッカーを値とする辞書としてネストされた辞書で動作し、既存の辞書に新しい値を追加します:
from yahooquery import Tickerimport pandas as pddef extract_comp_financials(tkr, comp_name, comp_dict): """競合他社の財務指標を抽出するための関数。ティッカー、企業名、およびネストされた辞書を引数として受け取り、財務指標を辞書に追加します。""" ticker = Ticker(tkr) income_df = ticker.income_statement(frequency='a', trailing=False) subset = income_df.loc[:, ['asOfDate', 'TotalRevenue', 'SellingGeneralAndAdministration']].reset_index() # 2022年のデータのみを保持 subset = subset[subset['asOfDate'].dt.year == 2022].sort_values(by='asOfDate', ascending=False).head(1) # 値を取得 total_revenue = subset['TotalRevenue'].values[0] sg_and_a = subset['SellingGeneralAndAdministration'].values[0] # 売上総利益に対するSG&Aの割合を計算 sg_and_a_pct = round(sg_and_a / total_revenue * 100, 2) # 辞書に値を追加 comp_dict[comp_name]['Total Revenue'] = total_revenue comp_dict[comp_name]['SG&A % Of Revenue'] = sg_and_a_pct# サンプル辞書peers_dict_nested = {'Company 1': {'Ticker': 'ABC'}, 'Company 2': {'Ticker': 'XYZ'}}# 各競合他社の財務データを抽出for key, value in peers_dict_nested.items(): try: extract_comp_financials(tkr=value['Ticker'], comp_name=key, dict=peers_dict_nested) # Yahoo Financeでティッカーが見つからない場合は、競合他社辞書から削除して続行 except: del peers_dict_nested[key] continue上記のコードを実行すると、以下のような構造を持つネストされた辞書が得られます:
# サンプルの出力辞書{'Company 1': {'Ticker': 'ABC', 'Total Revenue': '1234', 'SG&A % Of Revenue': '10'}, 'Company 2': {'Ticker': 'XYZ', 'Total Revenue': '5678', 'SG&A % Of Revenue': '20'}}次に、ネストされた辞書をDataFrameに変換してプロット関数に渡します:
# 競合他社の財務データを持つDataFrameを作成peers_df = pd.DataFrame.from_dict(peers_dict_nested, orient='index')peers_df = peers_df.reset_index().rename(columns={'index': 'Company Name'})生成されたDataFrameは、次のような形式になります:
Company Name Ticker Total Revenue SG&A % Of Revenue0 Company 1 ABC 1234 101 Company 2 XYZ 5678 20Plotlyを使用してグラフを作成する
フィルタリングされた財務データを取得したら、それをプロットしましょう!Plotly Expressを使用してシンプルで視覚的に魅力的なグラフを作成します(詳細はこちらを参照してください)。
前のセクションで、DataFrameと会社名の変数を作成しました。これらをplot_graph()関数で使用して、データフレーム、x軸とy軸の列名、およびグラフのタイトルを引数として渡します:
import plotly.express as pxdef plot_graph(df, x, y, title, name): """ライングラフをプロットする関数。DataFrame、x軸とy軸、タイトル、名前を引数として受け取り、Plotlyの図を返します。""" fig = px.line(df, x=x, y=y, template='simple_white', title='<b>{} {}</b>'.format(name, title)) fig.update_traces(line_color='#A27D4F') fig.update_layout(paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)') return figstock_fig = plot_graph(df=stock_df, x='Date', y='Open', title='Stock Price USD', name=name)rev_fig = plot_graph(df=rev_df, x='Year', y='Total Revenue', title='Total Revenue USD', name=name)debt_fig = plot_graph(df=debt_df, x='Year', y='Total Debt', title='Total Debt USD', name=name)ebitda_fig = plot_graph(df=ebitda_df, x='Year', y='EBITDA', title='EBITDA USD', name=name)生成されたグラフは、次のようなものになります:
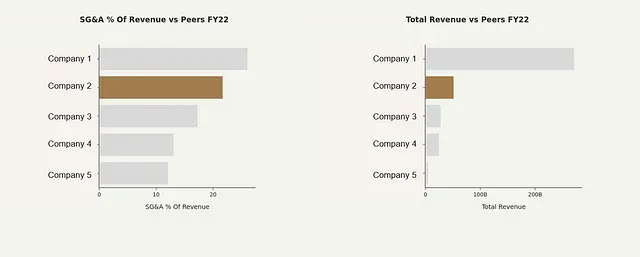
アプリは、与えられた企業に対して競合分析を含むスライドも生成します。これを作成するには、peers_plot()関数とpeers_dfを使用します。この関数は、競合他社間の総収益と販売・一般管理費用の収益に対する割合を比較する水平棒グラフを生成します。
以下にコードを示します:
import plotly.express as px
import pandas as pd
def peers_plot(df, name, metric):
"""DataFrame、名前、メトリック、およびティッカーを引数として受け取り、Plotlyグラフを返す関数"""
# 欠損値を持つ行を削除する
df.dropna(subset=[metric], inplace=True)
df_sorted = df.sort_values(metric, ascending=False)
# ラベルを繰り返し処理し、色を色マッピング辞書に追加し、選択した企業を強調表示する
color_map = {}
for label in df_sorted['Company Name']:
if label == name:
color_map[label] = '#A27D4F'
else:
color_map[label] = '#D9D9D9'
fig = px.bar(df_sorted, y='Company Name', x=metric,
template='simple_white', color='Company Name',
color_discrete_map=color_map,
orientation='h',
title='<b>{} {} vs Peers FY22</b>'.format(name, metric))
fig.update_layout(paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', showlegend=False, yaxis_title='')
return fig
# ピアズグラフをプロット
rev_peers_fig = peers_plot(df=peers_df, name=name, metric='Total Revenue')
sg_and_a_peers_fig = peers_plot(df=peers_df, name=name, metric='SG&A % Of Revenue')カスタムカラーを使用すると、企業が目立ちます。
棒グラフは、次のようなものになります:
Clearbit APIを使用して企業のロゴを取得する
企業概要スライドで見たように、調査対象企業のロゴが表示されています。Yahoo FinanceではロゴのURLは利用できないため、代わりにClearbitを使用します。以下のコードを使用して、企業のウェブサイトを「https://logo.clearbit.com/」に接続します:
from yahooquery import Ticker
selected_ticker = 'ABC'
ticker = Ticker(selected_ticker)
# 選択した企業のウェブサイトを取得
website = ticker.summary_profile[selected_ticker]['website']
# 選択した企業のロゴURLを取得
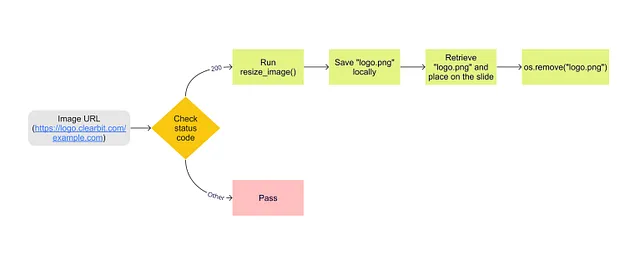
logo_url = '<https://logo.clearbit.com/>' + websiteロゴURLが取得できたら、その動作を確認します。動作する場合は、サイズを調整し、スライド上に配置します。これには、リサイズイメージ()というカスタム関数を使用します。この関数は、ロゴ画像をコンテナ内に配置し、アスペクト比を保ったままサイズを調整します。これにより、元のサイズによる初期の違いに関係なく、すべてのロゴが同じように見えるようになります。
次に、「logo.png」としてローカルにイメージオブジェクトを保存し、画像としてスライドに配置します。同様の方法で、Plotlyの図をスライドに配置することもできます。Python-pptxライブラリを使用して、PowerPointスライドと図形をプログラムで操作します(詳細はこちらを参照)。
以下は、プロセスです:
以下のコードは、前のコードスニペットで定義されたlogo_url変数を使用します:
from PIL import Image
import requests
from pptx import Presentation
from pptx.util import Inches
import os
def resize_image(url):
"""URLを引数として受け取り、アスペクト比を保ったままロゴをリサイズする関数。画像オブジェクトを返す"""
# URLから画像を開く
image = Image.open(requests.get(url, stream=True).raw)
# ロゴが高すぎるか幅が広すぎる場合、背景コンテナを2倍にする
if image.height > 140:
container_width = 220 * 2
container_height = 140 * 2
elif image.width > 220:
container_width = 220 * 2
container_height = 140 * 2
else:
container_width = 220
container_height = 140
# 元の画像と同じアスペクト比で新しい画像を作成
new_image = Image.new('RGBA', (container_width, container_height))
# 画像を中央に配置するための位置を計算
x = (container_width - image.width) // 2
y = (container_height - image.height) // 2
# 新しい画像に画像を貼り付ける
new_image.paste(image, (x, y))
return new_image
# プレゼンテーションオブジェクトを作成
prs = Presentation('template.pptx')
# 2番目のスライドを選択
slide = prs.slides[1]
# ロゴURLがコード200を返すかチェック(動作するリンク)
if requests.get(logo_url).status_code == 200:
# ロゴイメージオブジェクトを作成
logo = resize_image(logo_url)
logo.save('logo.png')
logo_im = 'logo.png'
# スライドにロゴを追加
slide.shapes.add_picture(logo_im, left=Inches(1.2), top=Inches(0.5), width=Inches(2))
os.remove('logo.png')上記のコードを実行すると、スライドにロゴが配置されるはずです:
LangChainとGPT 3.5 LLMを使用してSWOT分析とバリュープロポジションを作成しましょう。
会社の調査にAIを活用する時がきました!
ChatOpenAIとHuman/System Message LLMを使用してアプリケーションの作成を簡素化するために設計された人気のあるフレームワークであるLangChainを使用します(詳細はこちらを参照)。
generate_gpt_response()関数は2つの引数を取ります:
- gpt_input:モデルに渡すプロンプト
- max_tokens:モデルの応答のトークン数を制限する
ChatOpenAIの引数にgpt-3.5-turbo-0613モデルを使用し、Streamlitのシークレットに保存されているOpenAI APIキーを取得します。また、応答の品質を向上させるために、温度を0に設定してより決定論的な応答を得ます(詳細はこちらを参照)。
GPTの応答の品質を向上させるために、SystemMessage引数に次のテキストを渡します。「あなたはファイナンス、市場、および企業調査の分野で役立つ専門家です。B2Bソフトウェア製品の販売にも優れたスキルを持っています。」これにより、AIが従う目標が設定されます(詳細はこちらを参照)。
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
def generate_gpt_response(gpt_input, max_tokens):
"""GPT-3からの応答を生成する関数。入力と最大トークン数を引数として受け取り、応答を返す"""
# OpenAIクラスのインスタンスを作成する
chat = ChatOpenAI(openai_api_key=st.secrets["openai_credentials"]["API_KEY"], model='gpt-3.5-turbo-0613',
temperature=0, max_tokens=max_tokens)
# モデルから応答を生成する
response = chat.predict_messages(
[SystemMessage(content='あなたはファイナンス、市場、および企業調査の分野で役立つ専門家です。B2Bソフトウェア製品の販売にも優れたスキルを持っています。'),
HumanMessage(
content=gpt_input)])
return response.content.strip()次に、モデルのためのプロンプトを作成し、generate_gpt_response()関数を呼び出します。
次のコードで、モデルに特定の会社のSWOT分析を作成し、結果をPythonの辞書として返します:
input_swot = """{name}社(ティッカーシンボル:{ticker})の簡単なSWOT分析を作成してください。以下のキーを持つPythonの辞書として結果を返してください:Strengths、Weaknesses、Opportunities、Threatsがキーで、分析が値になります。それ以外は何も返さないでください。"""input_swot = input_swot.format(name='会社1', ticker='ABC')# GPT-3からの応答を返すgpt_swot = generate_gpt_response(input_swot, 1000)結果の辞書は以下のようになります:
{"Strengths": "テキスト", "Weaknesses": "テキスト", "Opportunities": "テキスト", "Threats": "テキスト"}同様に、GPTモデルに対して特定の会社の製品のバリュープロポジションを作成するようにプロンプトで指示することもできます。アプリは、顧客の痛みや利益、利益創出要素や痛み緩和要因を特定するための一般的なバリュープロポジションのフレームワークを使用しています:
input_vp = """"{product}に対するValue Proposition Canvasフレームワークを使用して、{name}社(ティッカーシンボル:{ticker})が{industry}業界で運営している会社のための簡単なバリュープロポジションを作成してください。以下のキーを持つPythonの辞書として結果を返してください:Pains、Gains、Gain Creators、Pain Relieversがキーで、テキストが値です。具体的かつ簡潔にしてください。それ以外は何も返さないでください。"""input_vp = input_vp.format(product='会計ソフトウェア', name='会社1', ticker='ABC', industry='小売業')# GPT-3からの応答を返すgpt_value_prop = generate_gpt_response(input_vp, 1000)# 応答は以下のようになります: # {"Pains": "テキスト", "Gains": "テキスト", "Gain Creators": "テキスト", "Pain Relievers": "テキスト"}GPTの応答から構造化データを抽出する
前のステップでは、GPTモデルにPythonの辞書形式の応答を要求しました。しかし、LLMは場合によっては意味のない応答を出力することがあり、返された文字列には必要な辞書だけではない場合があります。そのような場合は、応答文字列を解析して辞書を抽出し、Pythonの辞書型に変換する必要があります。
これを実現するには、reとastの2つの標準ライブラリが必要です。
dict_from_string()関数は、LLMからの応答文字列を受け取り、以下のワークフローで辞書を返します:
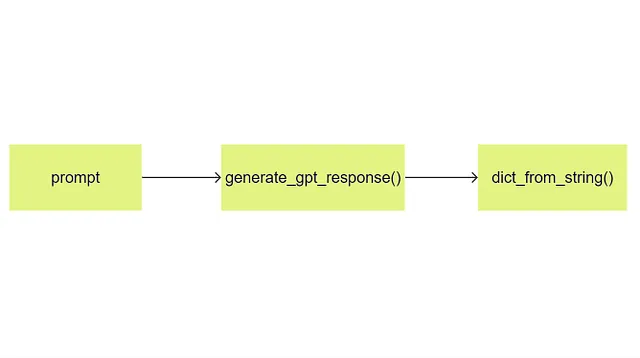
以下にコードを示します:
import reimport astdef dict_from_string(gpt_response): """GPTの応答を解析して辞書に変換する関数""" # 複数行にわたる、'{'で始まり'}'で終わる部分文字列を検索 match = re.search(r'\\{.*?\\}', gpt_response, re.DOTALL) dictionary = None if match: try: # 部分文字列を辞書に変換を試みる dictionary = ast.literal_eval(match.group()) except (ValueError, SyntaxError): # 辞書ではない return None return dictionaryswot_dict = dict_from_string(gpt_response=gpt_swot)vp_dict = dict_from_string(gpt_response=gpt_value_prop)python-pptxを使用したスライドの生成
データが手に入ったので、スライドを埋める時が来ました。PowerPointのテンプレートを使用し、python-pptxライブラリを使ってプレースホルダーを実際の値で置き換えます。
以下は、SWOTスライドのテンプレートの例です:

データでスライドを埋めるには、2つの引数を取るreplace_text()関数を使用します:
- プレースホルダーをキー、置換テキストを値とする辞書
- PowerPointのスライドオブジェクト
前のステップで定義したswot_dict変数を使用します:
from pptx import Presentationdef replace_text(replacements, slide): """PowerPointのスライド上のテキストを置換する関数。{match: replacement, ... }の辞書を受け取り、すべての一致箇所を置換します""" # スライド内のすべての形状に反復処理を行う for shape in slide.shapes: for match, replacement in replacements.items(): if shape.has_text_frame: if (shape.text.find(match)) != -1: text_frame = shape.text_frame for paragraph in text_frame.paragraphs: whole_text = "".join(run.text for run in paragraph.runs) whole_text = whole_text.replace(str(match), str(replacement)) for idx, run in enumerate(paragraph.runs): if idx != 0: p = paragraph._p p.remove(run._r) if bool(paragraph.runs): paragraph.runs[0].text = whole_textprs = Presentation("template.pptx")swot_slide = prs.slides[2]# スライドのタイトルを作成swot_title = '会社1のSWOT分析'# プレースホルダーと値の辞書を作成replaces_dict = { '{s}': swot_dict['Strengths'], '{w}': swot_dict['Weaknesses'], '{o}': swot_dict['Opportunities'], '{t}': swot_dict['Threats'], '{swot_title}': swot_title}# プレースホルダーを値で置換する関数を実行replace_text(replacements=replaces_dict, slide=swot_slide)要するに、replace_text()関数はスライド上のすべての形状を反復処理し、プレースホルダーの値を探し、辞書から値を見つけた場合にそれらを置換します。
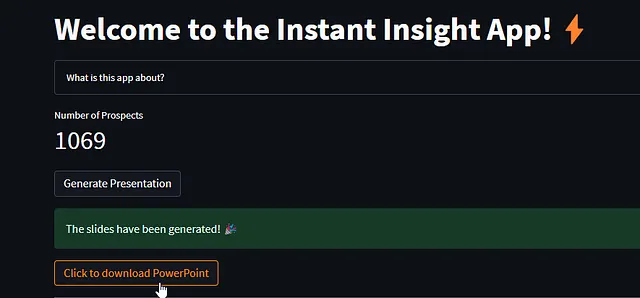
すべてのスライドにデータや画像が埋め込まれたら、プレゼンテーションオブジェクトはバイナリ出力として保存され、st.download_button()に渡されてユーザーがPowerPointファイルをダウンロードできるようになります(詳細はこちらを参照してください)。
以下は、フロントエンドでのダウンロードボタンの例です:
以下がコードです:
from pptx import Presentationfrom io import BytesIOfrom datetime import dateimport streamlit as st# ファイル名を作成するfilename = '{name} {date}.pptx'.format(name='会社1', date=date.today())# プレゼンテーションをバイナリ出力として保存するbinary_output = BytesIO()prs.save(binary_output)# 成功メッセージとダウンロードボタンを表示するst.success('スライドが生成されました! :tada:')st.download_button(label='PowerPointをダウンロードするにはクリックしてください', data=binary_output.getvalue(), file_name=filename)サンプルプレゼンテーションはこちらです。
まとめ
最後まで読んでいただきありがとうございます!これで、Streamlit、Snowflake、YahooFinance、LangChainを使用して、企業調査のスライド自動化アプリを開発することができます。この記事で新しい情報や有用な情報を見つけていただけたと思います。
ご覧の通り、このアプリにはいくつかの制限があります。まず、公開企業の調査のみを生成します。次に、GPTモデルは、ChatBotや会計ソフトウェアなどの製品に関する一般的な知識を使用して、価値提案を作成します。より高度なアプリでは、製品データを使用してモデルを微調整することで、2つめの制約に対処できます。これは、プロンプトに製品の詳細を渡すか、このデータを埋め込んでベクトルデータベースに保存することによって行うことができます(詳細はこちらをご覧ください)。
ご質問やフィードバックがありましたら、以下のコメント欄に投稿するか、GitHub、LinkedIn、Twitterでご連絡ください。
- プレースホルダをキーとし、置換テキストを値とする辞書
- PowerPointのスライドオブジェクト
前のステップで定義されたswot_dict変数を使用します:
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Google AI Researchは、正確な時空間の位置情報と密に関連付けられた意味的に正しい豊富なビデオの説明を取得する注釈手法であるVidLNsを提案しています
- ETHチューリッヒの研究者が、バイオミメティックな腱駆動式ファイブハンドを紹介:高次元自由度の3Dプリンタ対応設計で、器用な手の回転スキルを持つ
- 拡張版:NVIDIAがビデオ編集のためのMaxineを拡大し、3D仮想会議の研究を披露
- Airbnbの研究者がChrononを開発:機械学習モデルの本番用機能を開発するためのフレームワーク
- NVIDIAとテルアビブ大学の研究者が、効率的な訓練時間を持つコンパクトな100 KBのニューラルネットワーク「Perfusion」を紹介しました
- 「タンパク質設計の革命:ディープラーニングの改良により成功率が10倍に向上したこのAI研究」
- AIモデルは、患者のがんがどこで発生したかを判断するのに役立つことができます





