「AI駆動の洞察:LangChainとPineconeを活用したGPT-4」
AI駆動の洞察:LangChainとPineconeを活用したGPT-4
次世代のプロダクトマネージャーをサポートする- Vol. 1

質的データを効果的に扱うことは、プロダクトマネージャーにとって最も重要なスキルの一つです。データを収集し、分析し、具体的かつ価値のある洞察を得るために、効率的にコミュニケーションすることが求められます。
質的データは、ユーザーインタビュー、競合他社からのフィードバック、製品を使用している人々からのコメントなど、さまざまな場所から得ることができます。目標に応じて、このデータを直ちに分析するか、後で保存するかを選択することができます。時には、仮説を確認するためにわずかなユーザーインタビューだけが必要な場合もあります。他の場合では、トレンドを発見するために数千人のユーザーからのフィードバックが必要になることもあります。したがって、データの分析方法は状況に応じて変わることがあります。
GPT-4などの大規模言語モデル、およびLangChainやPineconeなどのAIツールを使用することで、さまざまな状況や大量のデータを効果的に処理することができます。このガイドでは、これらのツールを使用した経験を共有します。質的データを扱うプロダクトマネージャーやその他の関係者が、これらのAIツールを使用してデータからより有用な洞察を得る方法を学ぶことを目指しています。
このガイド形式の記事には以下の内容が含まれています。
- これらのAIツールの紹介と、大規模言語モデル(LLMs)の現在の制約について説明します。
- 実際のユースケースにおいてこれらのツールを最大限に活用する方法について説明します。
- ユーザーフィードバックの分析を例に挙げ、これらのツールが実際の作業にどのように活用されるかをコードスニペットと例を交えて説明します。
注意:GPT-4、LangChain、Pineconeなどのツールを使用するには、データに慣れ親しんでおり、基本的なコーディングスキルを持っていることが重要です。また、顧客を理解し、データの洞察を具体的な行動に変えることができる能力も重要です。AIや機械学習の知識はあるとさらに良いですが、必須ではありません。
AIツールの理解:LangChainとPineconeの必要性
GPT-4については既に理解していると仮定しますが、LLMsと連携するツールを考える際にいくつかの概念を押さえることが重要です。現在のGPT-4などのLLMsの主な課題の一つは「コンテキストウィンドウ」です。これは、LLMsが一度に処理および記憶できる情報量を指します。
現在、GPT-4には2つのバージョンがあります。標準版は8kトークンのコンテキストを持ち、拡張版は32kのコンテキストウィンドウを持っています。32kトークンは約24,000語であり、おおよそ48ページのテキストに相当します。ただし、32kバージョンはGPT-4にアクセスできる人すべてに利用可能ではありません。
また、最近OpenAIはgpt-3.5-turboの4倍のコンテキスト長を提供する新しいChatGPTモデル「gpt-3.5-turbo-16k」について発表しました。洞察分析に取り組む場合、GPT-3.5よりもGPT-4の方が推論能力が高いため、gpt-4を使用することをおすすめします。しかし、自分のユースケースに最適なものを試してみることもできます。
なぜこれを言及しているのか?
洞察分析に取り組む際には、多量のデータを扱う場合や単一のプロンプトに興味がある場合に課題が生じます。たとえば、1つのユーザーインタビューがあるとします。GPT-4を使用して、そのインタビューのトランスクリプトからさらに洞察を得たい場合、GPT-4を選択してChatGPTに提供するだけで済みます。テキストを分割する必要があるかもしれませんが、それだけです。この場合、他の特別なツールは必要ありません。したがって、多量の質的データを扱う場合にはこれらの特別なツールが必要になります。それでは、それらのツールが何であるかを理解し、具体的な使用例に移りましょう。
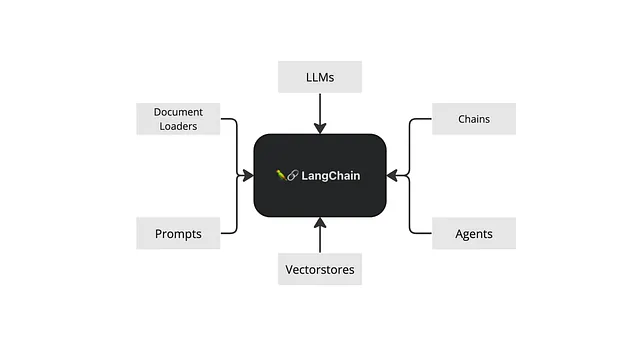
LangChainとは何ですか?
LangChainは、LLMsを中心に展開され、チャットボット、生成型質問応答(GQA)、要約などのさまざまな機能を提供するフレームワークです。その柔軟性は、プロンプトテンプレート、LLMs、エージェント、メモリシステムなど、さまざまなコンポーネントを結びつける能力にあります。
プロンプトテンプレートは、さまざまな状況に対応した事前作成のプロンプトであり、LLM(言語モデル)は応答を処理および生成します。エージェントはLLMの出力を基に意思決定を支援し、メモリシステムは情報を後で使用するために保存します。
この記事では、私の例を使用して、それのいくつかの機能を共有します。
Pineconeとは何ですか?
Pinecone.aiは、ベクトルとして知られる高次元データ表現の管理を簡素化するために設計された強力なツールです。
ベクトルは、テキストデータのような大量のデータを扱う際に特に有用です。たとえば、フィードバックを分析し、製品に関するさまざまな詳細を把握したいとします。このような深い洞察の収集は、「素晴らしい」「改善」「提案する」といったキーワード検索だけでは不可能です。文脈を逃す可能性があります。
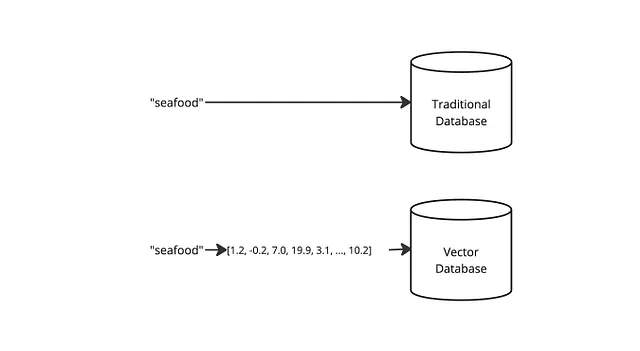
今回は、テキストベクトル化の技術的な側面には立ち入りません(単語ベース、文ベースなどになります)。理解しておくべき重要な点は、機械学習モデルを通じて単語が数値に変換され、それらの数値が配列に保存されるということです。
例を見てみましょう:
「シーフード」という単語は、次のような数値のシリーズに変換されるかもしれません:[1.2、-0.2、7.0、19.9、3.1、…、10.2]。
別の単語を検索すると、その単語も数値のシリーズ(またはベクトル)に変換されます。機械学習モデルが適切に機能している場合、同じ文脈を持つ単語は、「シーフード」とのシリーズに近い数値のシリーズを持つはずです。例を挙げます:
「エビ」という単語は、次のように変換されるかもしれません:[1.1、-0.3、7.1、19.8、3.0、…、10.5]。これらの数値は、「シーフード」の数値に近いです。
Pinecone.aiを使用すると、これらのベクトルを効率的に保存し、検索することができます。これにより、迅速かつ正確な類似性の比較が可能となります。
これらの機能を使用することで、LLMモデルから派生したベクトルを整理し、インデックス化することができます。これにより、包括的なデータセット内の意味のあるパターンの発見や深い洞察の得ることができます。
簡単に言えば、Pinecone.aiは、定性的データのベクトル表現を便利に保存することができるツールです。これらのベクトルを簡単に検索し、LLMモデルを適用して有益な洞察を抽出することができます。データの管理と有意義な情報の抽出のプロセスを簡素化します。
実際にLangChainとPineconeのようなツールが必要になるのはいつですか?
簡単に言えば、定性的データを扱う場合です。
私の経験からいくつかのユースケースを共有しましょう:
- 製品チャンネルから数千のフィードバックエントリを持っていると想像してください。データ内のパターンを特定し、フィードバックの進化を追跡したいとします。
- さまざまな言語でレビューがあり、それを希望の言語に翻訳し、洞察を抽出したいとします。
- 顧客のレビューやフィードバック、製品に関する感情を分析することで競合分析を実施したいとします。
- 企業がアンケートやユーザースタディを実施し、大量の定性的な回答を生成している場合。意味のある洞察を抽出し、トレンドを見つけ、製品やサービスの改善に役立てることが目標です。
これらは、定性的データを扱うプロダクトマネージャーにとって、LangChainとPineconeのようなツールが非常に有益なシチュエーションのいくつかです。
プロジェクトの例:フィードバック分析
プロダクトマネージャーとして、私の仕事は、ミーティングノートと転写の機能を改善することです。これを実現するために、ユーザーがそれについて何と言っているかを聞く必要があります。
ミーティングノートの機能では、ユーザーは品質について1から5のスコアを付け、使用したテンプレートを教えてくれ、またコメントも送ってくれます。以下はフローです:
このプロジェクトでは、2つのことに注目しました:ユーザーが私たちの機能について言ったことと、彼らが使用したテンプレートです。私は膨大な量のデータに取り組むことになりました – 20,000語以上のデータは、特別なツールを使用して分解すると38,000以上の「トークン」(またはデータの断片)に変わりました。それは非常に多くのデータであり、一度に扱うことができる一部の高度なモデルよりも多いです!
この広範なデータを分析するために、私は2つの高度なツール、LangChainとPinecone、さらにGPT-4を活用しました。これらを使って、プロジェクトについて詳しく調べ、これらのハイテクツールが私たちに何を可能にしたのか見てみましょう。
このプロジェクトの主な目的は、収集したデータから洞察を抽出することでした。そのためには以下が必要でした:
- データセットに関連する特定のクエリを作成する能力。
- 大量の情報を処理するためのLLMの使用。
まず、プロジェクトをどのように実施したかの概要を説明します。その後、使用したコードのいくつかの例を共有します。
まず、テキストファイルのコレクションから始めます。各ファイルには、ユーザーフィードバックと使用したテンプレートの名前がペアになっています。このデータを必要に応じて処理して自分のニーズに合わせることができます – 私はプロジェクトのためにいくつかの事後処理を行う必要がありました。自分のファイルとデータは異なるかもしれませんので、自分のプロジェクトに合わせて情報を調整してください。
例えば、ユーザーの会議のメモの構造に対するフィードバックを理解したい場合は:
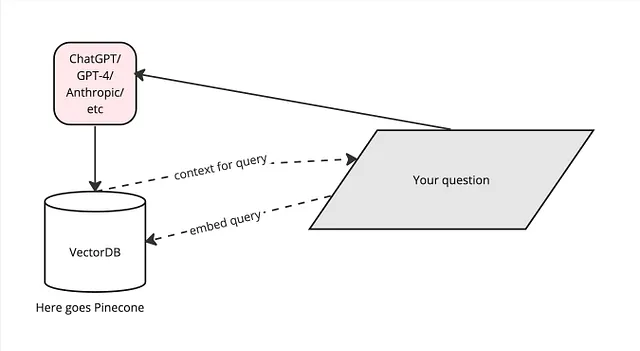
query = "Please list all feedback regarding sentence structures in a table \in markdown and get a single insight for each one, and give a general summary for all."以下は、LLMとPineconeを利用したプロセスフローを示した高レベルなダイアグラムです。GPT-4に質問、または私たちが「クエリ」と呼ぶものを尋ねます。一方、フィードバックがすべて入ったPineconeは、質問自体をそれに送信することで、クエリに対する文脈を提供します(「埋め込みクエリ」)。これらを組み合わせて、データを効率的に理解するのに役立ちます:
以下は、ダイアグラムのより簡略化されたバージョンです:
さあ、始めましょう!このスクリプトでは、OpenAIのGPT-4、Pinecone、およびLangChainを使用してユーザーフィードバックデータを分析するためのパイプラインを設定します。必要なライブラリをインポートし、フィードバックデータのパスを設定し、このデータを処理するためのOpenAI APIキーを確立します。
import osimport openaiimport pineconeimport certifiimport nltkfrom tqdm.autonotebook import tqdmfrom langchain.document_loaders import DirectoryLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconefrom langchain.llms import OpenAIfrom langchain.chains.question_answering import load_qa_chaindirectory = 'テキストファイルが含まれるディレクトリのパス'OPENAI_API_KEY = "あなたのキー"次に、指定したディレクトリからLangChainのDirectoryLoaderを使用してユーザーフィードバックドキュメントをロードするload_docs()関数を定義して呼び出します。それから読み込まれたドキュメントの総数を数えて表示します。
def load_docs(directory): loader = DirectoryLoader(directory) documents = loader.load() return documentsdocuments = load_docs(directory)len(documents)次に、ロードされたドキュメントを特定のサイズとオーバーラップでより小さなチャンクに分割するsplit_docs()関数を定義して実行します。これにはLangChainのRecursiveCharacterTextSplitterが使用されます。その後、生成されたチャンクの総数を数えて表示します。
def split_docs(documents, chunk_size=500, chunk_overlap=20): text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) docs = text_splitter.split_documents(documents) return docsdocs = split_docs(documents)print(len(docs))基本的にはベクトルデータベースであるPineconeで作業するために、ドキュメントから埋め込みを取得する必要があります。そのためには関数を導入する必要があります。方法はいくつかありますが、ここではOpenAIの埋め込み関数を使用します:
# OpenAIEmbeddingsクラスが上でインポートされていることを前提としますembeddings = OpenAIEmbeddings()# クエリに対して埋め込みを生成するための関数を定義しましょうdef generate_embedding(query): query_result = embeddings.embed_query(query) print(f"クエリの埋め込みの長さは: {len(query_result)}") return query_resultこれらのベクトルをPineconeに保存するには、そこでアカウントを作成し、インデックスも作成する必要があります。それは非常に簡単に行うことができます。その後、APIキー、環境名、そしてインデックス名を取得します。
MY_API_KEY_p= "the_key"MY_ENV_p= "the_environment"pinecone.init( api_key=MY_API_KEY_p, environment=MY_ENV_p)index_name = "your_index_name"index = Pinecone.from_documents(docs, embeddings, index_name=index_name)次のステップは、答えを見つけることです。これは、可能な答えのフィールドで質問に最も関連性の高い結果を与える、質問に対して最も近いポイントを見つけるようなものです。
def get_similiar_docs(query, k=40, score=False): if score: similar_docs = index.similarity_search_with_score(query, k=k) else: similar_docs = index.similarity_search(query, k=k) return similar_docsこのコードでは、OpenAIのGPT-4モデルとLangChainを使用して質問応答システムを設定しています。get_answer()関数は質問を入力として受け取り、類似ドキュメントを見つけ、質問応答チェーンを使用して回答を生成します。
from langchain.chat_models import ChatOpenAImodel_name = "gpt-4"llm = OpenAI(model_name=model_name, temperature =0)chain = load_qa_chain(llm, chain_type="stuff")def get_answer(query): similar_docs = get_similiar_docs(query) answer = chain.run(input_documents=similar_docs, question=query) return answer質問に到達しました!1つまたは複数の質問をすることができます。
query = "Please list all feedback regarding sentence structures in a table \in markdown and get a single insight for each one, and give a general summary for all."answer = get_answer(query)print(answer) 検索Q&Aチェーンの実装:
検索質問応答システムを実装するために、LangChainのRetrievalQAクラスを使用します。これはOpenAI LLMを使用して質問に答え、”stuff”チェーンタイプに依存します。リトリーバーは以前に作成したインデックスに接続され、’qa’変数に保存されます。より良い理解のために、リトリーバ技術についても学ぶことができます。
from langchain.chains import RetrievalQAretriever = index.as_retriever()qa_stuff = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=retriever, verbose=True)response = qa_stuff.run(query)応答が得られたので、Markdownテキストを使用して応答変数に格納されている内容を視覚的に魅力的な形式で表示しましょう。これにより、表示されるテキストがより整理され、読みやすくなります。
from IPython.display import display, Markdowndisplay(Markdown(response))
このアプローチとツールの最大の利点を引き出すために、入力ファイルとクエリの両方で実験してみてください。
結論
要するに、GPT-4、LangChain、およびPineconeは、大量の質的データを扱うことを容易にします。これらは私たちがこのデータに掘り下げて価値のある洞察を見つけ、より良い意思決定を導くのに役立ちます。この記事ではそれらの使用方法の一部を紹介しましたが、これらのツールにはさらに多くの可能性があります。
これらのツールはますます進化し一般的になるにつれ、今それらを使いこなすことは将来的に大きな利点をもたらします。ですので、これらのツールについて探求し学習し続けてください。なぜなら、これらのツールがデータ分析の現在と未来を形作っているからです。
将来的にこれらの便利なツールをさらに探求する方法についてもお楽しみに!
すべての画像は、特に注記がない限り、著者のものです。
参考文献
LangChain ドキュメンテーション
Pinecone ドキュメンテーション
LangChain による LLM アプリケーション開発短期コース
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






