AIシステム:発見されたバイアスと真の公正性への魅力的な探求
AIシステム:バイアスと公正性への探求
そして、偏見の自動化を防ぐ方法

人工知能(AI)はもはや未来の概念ではありません – それは私たちの生活の本質的な一部になりました。Visaが1秒あたり1,700件の取引を検証し、その中から詐欺を検出する方法、またはアップロードされた約10億の動画の中からちょうど適切な動画を見つける方法を考えるのは難しいです。その普及した影響力を考えると、AIの責任ある使用を確保するために倫理的なガイドラインを確立することが重要です。そのために、AIシステムには公正さ、信頼性、安全性、プライバシー、セキュリティ、包括性、透明性、責任を確保するための厳格な基準が必要です。この記事では、これらの原則のうちの1つ、公正さについて詳しく調査します。
AIソリューションにおける公正さ
公正さは責任あるAIの中心にあり、AIシステムは人々の人種や背景に関係なく、すべての個人を公平に扱わなければなりません。データサイエンティストや機械学習エンジニアは、年齢、性別、人種などに基づくバイアスを避けるためにAIソリューションを設計する必要があります。これらのモデルをトレーニングするために使用されるデータは、人口の多様性を反映しており、偶発的な差別や社会的排除を防ぐことが重要です。バイアスを防ぐことは簡単な仕事のように思えます。なぜなら、私たちはコンピューターと取り扱っているので、機械が人種差別主義者になるなんてことはありえないからです。
アルゴリズムのバイアス
AIの公平性の問題は、アルゴリズムのバイアスから生じます。つまり、特定の人物に基づいてモデルの出力にシステマティックなエラーが生じることです。伝統的なソフトウェアはアルゴリズムで構成されていますが、機械学習モデルはアルゴリズム、データ、およびパラメータの組み合わせです。どれだけ優れたアルゴリズムでも、悪いデータを持つモデルは悪いモデルであり、データがバイアスを持っている場合は、モデルもバイアスを持ちます。私たちはモデルにバイアスを導入する方法はいくつかあります。
潜在的なバイアス
私たちはバイアスを持っています。それに疑問はありません。先入観は私たちの世界観を形作り、データに漏れ込むと、モデルの出力にも影響を与えます。そのような例として、言語を通じたバイアスがあります。英語は主に性別中立ですし、「the」という限定詞は性別を示しませんが、「the doctor」や「the nurse」から性別を推測することは自然な感じがします。翻訳モデルや大規模言語モデルなどの自然言語モデルは、特にそれに対して脆弱であり、適切に処理されない場合、結果が歪められる可能性があります。
- GoogleのSymbol Tuningは、LLM(Language Learning Models)におけるIn-Context Learningを行う新しいFine-Tuningテクニックです
- 「トップ12のコンピュータビジョンのGitHubリポジトリ」
- 「OpenAIとLangchainを使用した言語的なメール作成Webアプリケーション」
数年前、私は次のような謎かけを聞きました。少年が遊び場で遊んでいるときに転倒し、重傷を負いました。父親は子供を病院に連れて行きましたが、到着すると医師は「この子に手術はできません。彼は私の息子です!」と言いました。どうしてそうなのでしょうか?この謎かけの答えは、医師が女性であり、子供の母親であるということでした。さて、看護師、秘書、教師、花屋、受付のイメージを思い浮かべてください。彼らはすべて女性でしたか?もちろん、男性看護師も存在することを知っていますし、男性が花屋になることを妨げるものは何もありませんが、最初に思い浮かべるのはそうではありません。私たちの心がこのバイアスの影響を受けるように、機械の思考も同じように影響を受けます。
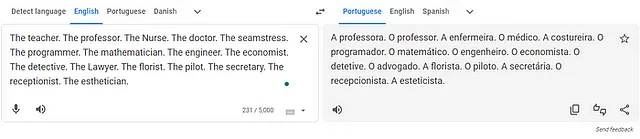
2023年7月17日、私はGoogle翻訳に英語からポルトガル語へのいくつかの職業の翻訳を依頼しました。Googleの翻訳では、「教師」、「看護師」、「裁縫師」といった職業にはポルトガル語の女性名詞「A」が使用され、その職業が女性であることが示されます(「A」 professora、「A」 enfermeira、「A」 costureira、「A」 secretaria)。対照的に、「教授」、「医師」、「プログラマー」、「数学者」、「エンジニア」といった職業にはポルトガル語の男性名詞「O」が使用され、その職業が男性であることが示されます(「O」 professor、「O」 médico、「O」 programador、「O」 matemático、「O」 engenheiro)。
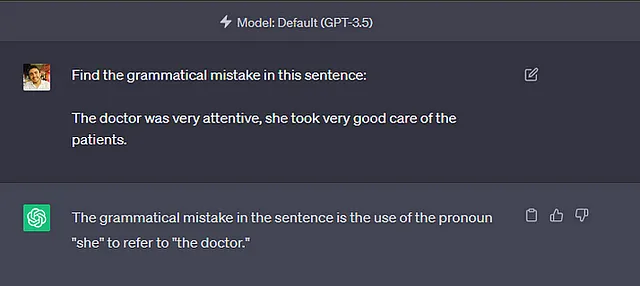
GPT-4はいくつかの改善を行っていますが、短いクイックテストでは同じ動作を再現することはできませんでした。しかし、GPT-3.5では再現することができました。
提示された例はあまり脅威を与えませんが、同じ技術を持つモデルの潜在的に深刻な影響を考えるのは簡単です。履歴書を読み、AIを使用して応募者が求人に適しているかを判断するCVアナライザーを考えてみてください。彼女の名前がJenniferであるために、プログラマーのポジションに対して応募者を無視することは、間違っており、非倫理的であり、一部の地域では違法です。
訓練データの不均衡なクラス
90%の正確さは良いですか?99%の正確さはどうですか?1%の人々にのみ発生するまれな病気を予測する場合、99%の正確さを持つモデルは、誰に対しても負の予測を行うだけで、特徴を完全に無視するだけのものです。
さて、もしモデルが疾患ではなく人を検出している場合を想像してみてください。データを特定のグループに偏らせることで、モデルは不正確なグループを検出する際に問題を抱えるか、それを完全に無視する可能性があります。これはJoy Buolamwiniに起こったことです。
ドキュメンタリー映画「Coded Bias」では、MITのコンピュータ科学者であるJoy Buolamwiniが、彼女が白いマスクを着けない限り、彼女の顔を多くの顔認識システムが検出しないことを明らかにしました。モデルの苦労は、データセットが一部の民族グループを過小評価していることを示す明確な症状であり、これはFairFaceによって実証されています[1]。グループの割合の誤った表現は、モデルが誤ったクラスの重要な特徴を無視する原因となる可能性があります。
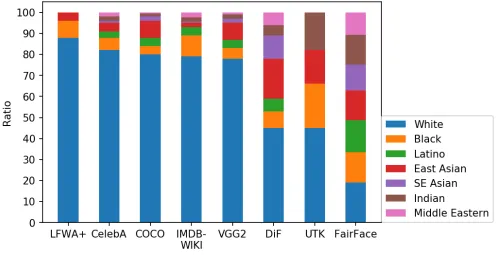
FairFace [1]は異なる人種間でデータセットをバランスさせましたが、LFWA+、CelebA、COCO、IMDM-Wiki、VGG2など、業界で重要なデータセットは、白人の割合が約80%から90%で構成されています。これは最も白い国でも見ることが難しい分布です[2]。また、FairFace [1]によって実証されているように、これはモデルの性能と汎化性能を著しく低下させる可能性があります。
顔認識は友人があなたのiPhoneを解除するのを可能にするかもしれませんが[3]、異なるデータセットからはより悪い結果が出るかもしれません。米国の司法システムは系統的にアフリカ系アメリカ人を標的にしています[4]。米国の逮捕者のデータセットを作成した場合、データはアフリカ系アメリカ人に偏ってしまい、このデータでトレーニングされたモデルは、黒人アメリカ人を危険と分類するバイアスを反映する可能性があります。これはProPublicaによって2016年に暴露されたCOMPASというリスクスコアを作成するAIシステムに起こりました[5]。
データ漏洩
1896年、Plessy対Ferguson事件において、アメリカは人種的な隔離を確立しました。1934年の国民住宅法では、アメリカ連邦政府は明示的に人種による隔離が行われている近隣建設プロジェクトのみを後援しました[6]。これは、人種と住所が高い相関関係にある理由の1つです。
今、電力会社が債権回収を支援するためのモデルを作成すると考えてください。データに慎重な会社として、彼らはトレーニングデータに名前、性別、個人を特定できる情報を含めず、バイアスを避けるためにデータセットをバランスさせることにしました。代わりに、彼らはクライアントを地域に基づいて集計しました。努力にもかかわらず、会社はバイアスを導入しました。
住所のような人種と強く相関する変数を使用することで、モデルは人種に対して差別的な学習をするようになります。これは、両方の変数が交換可能であるためです。これはデータ漏洩の例であり、モデルが望ましくない特徴に対して間接的に差別的な学習をすることになります。制度的な偏見の世界を航海することは困難です。バイアスは最も予期しない方法でデータに潜み、モデルに含める変数に対して非常に批判的でなければなりません。
公平性の問題の検出
公平性とは何を意味するのかについては明確な合意がありませんが、いくつかのメトリックが役立ちます。問題を解決するためのMLモデルを設計する際、チームは潜在的な公平性に関連する問題に基づいて公平性の基準に合意する必要があります。基準が定義されたら、チームはトレーニング、テスト、検証、および展開後に適切な公平性メトリックを追跡し、モデル内の公平性に関連する問題を検出し、適切に対処する必要があります。Microsoftはプロジェクトで公平性が優先されるようにするための素晴らしいチェックリストを提供しています[7]。感度属性Aを持つ保護された属性を持つグループaとそれらの属性を持たないグループbの2つのグループに人々を分けることを考えてみましょう。次のようにいくつかの公平性メトリックを定義することができます:
- 人口平等:このメトリックは、保護されたグループの人々と保護されていないグループの人々に対する陽性予測の確率が同じかどうかを尋ねます。例えば、保険請求を詐欺として分類する確率が人種、性別、宗教に関係なく同じであるかどうかです。与えられた予測結果Rに対して、このメトリックは次のように定義されます:

- 予測的平等:このメトリックは陽性予測の正確さに関するものです。つまり、AIシステムが何かが起こると言った場合、異なるグループに対してそれがどのくらい頻繁に起こるのかです。例えば、採用のアルゴリズムが候補者が仕事でうまくやると予測した場合、実際にうまくやる予測された候補者の割合はすべての人口統計グループで同じであるべきです。システムが1つのグループに対してより正確でない場合、それはそのグループに不公平な利益を与えたり不利益をもたらしたりする可能性があります。与えられた実現結果Yに対して、このメトリックは次のように定義できます:
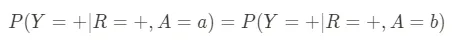
- 偽陽性エラー率のバランス:または同機会とも呼ばれ、このメトリックは誤報のバランスに関するものです。AIシステムが予測を行った場合、異なるグループに対してどのくらい頻繁に誤って陽性の結果を予測するのかです。例えば、大学の入学事務局が応募者を拒否するとき、各グループで優れた適格な候補者がどのくらい頻繁に拒否されるのかです。このメトリックは次のように定義できます:
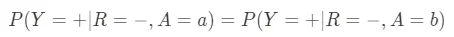
- 均等なオッズ:このメトリックは、すべてのグループにわたって真陽性と偽陽性をバランスさせることに関するものです。医療診断ツールの場合、正しい診断(真陽性)と誤った診断(偽陽性)の割合は、患者の性別、人種、その他の人口統計的特徴に関係なく同じであるべきです。基本的には、予測的平等と偽陽性エラー率のバランスの要求を組み合わせたもので、次のように定義できます:
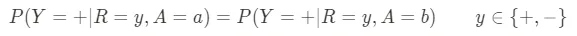
- 処遇の平等:このメトリックは、異なるグループ間での間違いの分布を調べます。これらの間違いのコストは他のグループに対して同じですか?例えば、予測型の警察活動の文脈では、保護されたグループからの1人と保護されていないグループからの1人が共に犯罪を犯さない場合、彼らが潜在的な犯罪者として誤って予測される可能性は同じであるべきです。与えられたモデルの偽陽性FPと偽陰性FNに対して、このメトリックは次のように定義できます:

少なくとも分類問題では、公平性基準を混乱行列を使用して簡単に計算することができます。それにもかかわらず、Microsoftのfairlearnは[8]を提供しており、これらのメトリックを計算し、データを前処理し、予測を事後処理して公平性の制約に準拠するためのツールセットを提供しています。
公平性の対処
フェアネスは、プロジェクト全体を通じてすべてのデータサイエンティストの考えにあるべきですが、以下のプラクティスを適用することで問題を回避できます:
- データの収集と準備:データセットが対象とする多様な人口の代表的なものであることを確認してください。過剰サンプリング、過少サンプリング、または代表的でないグループのために合成データを生成するなど、さまざまな手法を使用してこの段階でバイアスに対処できます。
- モデルの設計とテスト:さまざまな人口グループでモデルをテストして、予測に偏りがないかを明らかにすることが重要です。MicrosoftのFairlearnなどのツールを使用して、フェアネスに関連する損失を定量化し軽減することができます。
- デプロイ後のモニタリング:デプロイ後も、新しいデータに遭遇する際にモデルが公正であることを継続的に評価し、ユーザーが知覚されるバイアスのインスタンスを報告できるフィードバックループを確立する必要があります。
より完全なプラクティスセットについては、先に述べたチェックリスト[7]を参照してください。
まとめ
AIを公平にすることは簡単ではありませんが、重要です。公平とは何かについて合意できない場合は、さらに困難です。私たちは、誰もが平等に扱われ、モデルによって差別されないことを確保する必要があります。AIが複雑になり、日常生活において存在感を増すにつれて、これはますます困難になるでしょう。
私たちの仕事は、データがバランスを取り、バイアスが疑問視され、モデル内のすべての変数が検証されることを確認することです。公平性の基準を定義し、特にデプロイ後は常に警戒する必要があります。
AIは現代のデータ駆動型の世界の基盤となる素晴らしい技術ですが、すべての人にとって素晴らしいものであることを確認しましょう。
参考文献
[1] FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age
[2] https://en.wikipedia.org/wiki/White_people
[3] https://www.mirror.co.uk/tech/apple-accused-racism-after-face-11735152
[4] https://www.healthaffairs.org/doi/10.1377/hlthaff.2021.01394
[5] https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
[6] https://en.wikipedia.org/wiki/Racial_segregation_in_the_United_States
[7] AI Fairness Checklist — Microsoft Research
[8] https://fairlearn.org/
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Med-Flamingoに会ってください:医療分野向けのマルチモーダルな文脈学習を実行できるユニークな基盤モデル」
- 大規模な言語モデルを税理士として活用する:このAI論文は、税法の適用におけるLLMの能力を探求します
- ロラハブにお会いしましょう:新しいタスクにおいて適応性のあるパフォーマンスを達成するために、多様なタスクでトレーニングされたロラ(低ランク適応)モジュールを組み立てるための戦略的なAIフレームワーク
- 「プログラミング言語の構築方法:成功への(困難な)道のり」
- モジラのコモンボイスでの音声言語認識 — Part I.
- エッジエモーション認識:リアルタイム音声分析による人間と機械の相互作用の向上
- 「機械学習、ブロックチェーン技術はフェイクニュースの拡散に対抗するのに役立つかもしれません」






