AIのオリンピック:機械学習システムのベンチマーク
AIオリンピック:機械学習ベンチマーク
ベンチマークはどのようにブレークスルーを生み出すのか?
測定しないと改善できない。— ピーター・ドラッカー

4分のマイル: ランニングを再定義したベンチマーク
長年にわたり、4分未満でマイルを走ることは、多くの人々にとって困難な課題であり、不可能な偉業と考えられていました。それは、心理的で物理的なベンチマークであり、多くの人々が到達不可能だと考えたものでした。医師やスポーツの専門家たちは、人間の体がそのような速さで長時間走ることはできないという理論を立てました。この信念は根強く、それを試みることが致命的になる可能性さえあるとさえ示唆する者もいました。
イギリスの中距離ランナーであり、医学生でもあるサー・ロジャー・バニスターは、異なった考えを持っていました。彼は課題を認識しながらも、障壁は心理的なものであり、生理学的なものよりもそうであると信じていました。バニスターは、科学的なアプローチを取り、マイルをセクションに分け、各セクションを厳密にタイミングしました。また、インターバルトレーニングに基づいた厳しいトレーニング計画を採用し、自身の記録挑戦の準備段階で小さなベンチマークを設定しました。
1954年5月6日、オックスフォードのトラックで、友人のクリス・ブラッシャーとクリス・チャタウェイの助けを借りて、バニスターは4分の壁を破る挑戦をしました。彼はマイルを3分59.4秒で完走し、その閾値を打ち破り、歴史を作りました。

バニスターの偉業の余波は非常に予想外でした。バニスターが現れるまで、グンダー・ヘッグの1945年の記録(4分1.4秒)は約10年間破られることはありませんでした。しかし、4分のマイルのベンチマークが破られると、すぐに他の人々も続きました。バニスターのランからわずか46日後、ジョン・ランディはマイルを3分57.9秒で完走しました。その後の10年間で、その記録はさらに5回破られました。現在の記録は、ヒシャム・エル・グエルジュによって樹立された3分43.1秒です。
1900年から2000年までの世界記録のマイルタイム。1945年から1954年までのロジャー・バニスターが4分のマイルのベンチマークを破った間のギャップに注目してください。それ以外の部分はほぼ直線的な下降傾向です。著者によって作成された図。
バニスターの偉業は、ベンチマークの力を示しています。それはパフォーマンスの尺度だけでなく、変革の動機を提供します。4分の「ベンチマーク」が破られると、アスリートが可能と信じることを再定義しました。障壁はトラック上だけでなく、心の中にも存在しました。
4分のマイルは、さまざまな分野でベンチマークの変革力を具現化しています。ベンチマークは特定のタスクのパフォーマンス向上を数量化する手段を提供し、他者と比較する手段を与えます。これがオリンピックなどのスポーツイベントの基盤です。ただし、ベンチマークは、関係するコミュニティが追求すべき共通の目標を決定できる場合にのみ有用です。
機械学習とコンピュータサイエンスの領域では、ベンチマークは共同のオリンピックとして機能します。アルゴリズム、システム、および方法論がメダルを競うのではなく、進歩と革新の誇りを競います。アスリートがオリンピック金メダルを追求するために数年間トレーニングするように、開発者や研究者はモデルとシステムを最適化し、パフォーマンスを向上させるために努力し、確立されたベンチマークを上回ることを目指します。
ベンチマークの芸術と科学は、共通の目標の確立にあります。単なるタスクの設定だけでなく、それが現実の課題の本質を捉え、可能性の限界に挑戦し続けながら、関連性と適用性を保つようにすることです。適切に選択されたベンチマークは、研究者たちが迷いに陥ることなく、現実世界のアプリケーションの向上につながるタスクの最適化を促すことができます。よく設計されたベンチマークは、ある分野を再定義するブレークスルーに向けて、コミュニティ全体を導くことができます。
したがって、ベンチマークは比較と競争のためのツールではありますが、その真の価値は共有されたビジョンを中心にコミュニティを結束させる能力にあります。バニスターの走りが単なる記録更新ではなく、運動の可能性を再定義したように、よく構想されたベンチマークは学問全体を高め、パラダイムをシフトし、革新の新たな時代を切り開くことができます。
この記事では、ベンチマーキングがコンピュータサイエンスと機械学習の進歩に果たす重要な役割を探求し、その歴史をたどり、機械学習システムのベンチマーキングの最新トレンドを議論し、ハードウェアセクターでのイノベーションをどのように促進しているかを見ていきます。
コンピューティングシステムのベンチマーキング:SPEC
1980年代、パーソナルコンピュータ革命が進む中で、異なるコンピュータシステムの性能を比較するための標準化された指標の需要が高まっていました。それがベンチマークです。標準化されたベンチマークがなかった時代、メーカーは独自のカスタムベンチマークを開発し、使用していました。これらのベンチマークは、自社のマシンの強みを強調し、弱点を軽視する傾向がありました。比較のためには中立的で普遍的に受け入れられるベンチマークが必要であることが明らかになりました。
この課題に対処するために、システムパフォーマンス評価協力会 (SPEC) が開発されました。この組織のメンバーは、ハードウェアベンダー、研究者、および他の関係者であり、一般的に「チップ」とも呼ばれる中央演算処理装置(CPU)のベンチマーキングのための普遍的な基準を作成することに関心を持っていました。
SPECの最初の大きな貢献は、SPEC89ベンチマークスイートでした。これは産業標準のCPUベンチマークの最初の試みの一つでした。SPECのベンチマークは、実世界のアプリケーションと計算タスクに焦点を当て、ニッチな測定値ではなく、エンドユーザーにとって重要なメトリクスを提供することを目指していました。
しかし、ベンチマークが進化するにつれ、興味深い現象が現れました。それは「ベンチマーク効果」と呼ばれるものです。SPECのベンチマークがCPUパフォーマンスの基準となるにつれ、CPUデザイナーは自社のデザインをSPECのベンチマークに最適化し始めました。要するに、業界が全体のパフォーマンスを測る指標としてSPECのベンチマークを評価するようになったため、メーカーは自社のCPUがこれらのテストで優れたパフォーマンスを発揮することを確保するために強い動機を持っていました。これは非SPECタスクのパフォーマンスを犠牲にする可能性があってもです。
これはSPECの意図したことではなく、コンピュータサイエンスのコミュニティ内で熱い議論が巻き起こりました。これらのベンチマークは本当に現実世界のパフォーマンスを代表しているのか?それとも、ベンチマークが目的そのものになり、目標への手段ではなくなっているのか?
これらの課題に対応するために、SPECは年々ベンチマークを更新し、過度な最適化を防ぐために最先端に対応してきました。彼らのベンチマークスイートは、整数演算と浮動小数点演算から、グラフィックス、ファイルシステムなどのより特定のドメインに関連するタスクまで、さまざまな領域をカバーするように拡大しました。
SPECとそのベンチマークの物語は、ベンチマーキングが産業全体の方向に与える深い影響を示しています。これらのベンチマークは単にパフォーマンスを測定しただけではなく、それに影響を与えました。これは標準化の力を示すものですが、一つの指標が最適化の焦点になった場合に生じる意図しない結果についての警告の物語でもあります。
現在、SPECのベンチマークは、他のベンチマークとともに、コンピュータハードウェア産業の方向を形作り、消費者や企業が購入において指針となっています。
ディープラーニングのベンチマーキング:ImageNet
2000年代後半、コンピュータビジョンというAIのサブフィールドは、視覚データに基づいて機械が解釈し、意思決定を行う能力を可能にすることに焦点を当てて進展を遂げようとしていました。従来の技術は進歩を遂げていましたが、多くのタスクでパフォーマンスの限界に達していました。当時利用可能だった手法は、手作業で特定のタスクごとに特定の特徴を設計・選択することを重要視するものであり、手間のかかるプロセスであり、多くの制約がありました。
その後、Fei-Fei Li博士と彼女のチームによって始まった大規模なビジュアルデータベースであるImageNetがリリースされました。ImageNetは、数千のカテゴリにわたる数百万のラベル付き画像を提供しました。このデータセットの規模は前例のないものであり、Amazon Mechanical Turkなどのクラウドベースのアプローチを通じたデータラベリングのクラウドソーシングが可能になったことによるものでした。ImageNetは最初のデータセットベンチマークの一つであり、そのリリース以来、ImageNetの論文は5万回以上引用されています。

しかし、データセットの収集は始まりに過ぎませんでした。2010年、ImageNet Large Scale Visual Recognition Challenge(ILSVRC)が開催されました。このチャレンジは目標はシンプルですが、スケールは非常に大きく、画像を自動的に1,000のカテゴリのいずれかに分類することです。このベンチマークチャレンジは、コンピュータビジョンの進歩を客観的に評価するためのものであり、以前の試みをはるかに上回るスケールで行われました。
初年度は従来の手法に比べて少しずつ改善されました。しかし、2012年のチャレンジでは、画期的な変化が起こりました。トロント大学のアレックス・クリジェフスキー、イリヤ・スツケヴェル、ジェフリー・ヒントン率いるチームが、「AlexNet」と呼ばれる深い畳み込みニューラルネットワーク(CNN)を導入しました。彼らのモデルは15.3%のエラー率を達成し、前年のエラー率をほぼ半分に減らしました!
なぜこのようなことが可能になったのでしょうか?ディープラーニング、特にCNNは、生のピクセルから直接特徴を学習する能力を持っており、手動で特徴を作り出す必要がありませんでした。十分なデータと計算能力があれば、これらのネットワークは従来の手法では扱えない複雑なパターンを明らかにすることができました。
AlexNetの成功は、AIの発展における画期的な瞬間でした。2012年以降の数年間は、ディープラーニングの手法がImageNetチャレンジを席巻し、エラーレートを下げ続けました。ベンチマークからの明確なメッセージは否定できませんでした。機械学習のニッチな領域だったディープラーニングが、コンピュータビジョンだけでなく、自然言語処理からゲームプレイまで、AIのさまざまな領域で革命を起こすことができるということです。
そして、それ以上のこともしました。ILSVRCでの成功は、AIの研究者、資金、焦点をこの領域に引き寄せることで、コンピュータビジョンだけでなく、自然言語処理からゲームプレイまで、AIのさまざまな領域においてもディープラーニングの潜在能力を強調しました。
明確で厳しい基準を設定することで、ImageNetチャレンジはAI研究の軌道を変える重要な役割を果たし、現在目撃しているディープラーニング主導のAIルネサンスへと導きました。
マシンラーニングシステムのベンチマーク:MLPerf
SPECやImageNetのようなベンチマークの変革的な影響は、当然ながら次の疑問を呼び起こします。次は何でしょうか?ディープラーニングモデルがますます複雑になるにつれて、計算要件も高まりました。これにより、これらのモデルを駆動するハードウェアへの関心が高まりました。そこで登場したのがMLPerfです。
MLPerfは、業界の巨大企業や学術機関が参加する共同プロジェクトとして登場しました。そのミッションは、機械学習ハードウェア、ソフトウェア、クラウドプラットフォームのパフォーマンスを測定するための標準的なベンチマークセットを作成することです。その名前が示すように、MLPerfは明示的に機械学習に焦点を当てており、画像分類から強化学習までの幅広いタスクをカバーしています。その目標は明確です。従来の「最高のパフォーマンス」という主張は一般的になっていましたが、基準が一貫していないか、選りすぐりのメトリックに基づいていたため、明確さを提供することです。
MLPerfの導入により、テクノロジー業界には必要不可欠な統一された基準が提供されました。学術界にとっては、イノベーションのアルゴリズムが簡単に測定および比較できる環境を促進する明確なパフォーマンス目標が提供されました。特にハードウェアメーカーにとっては、チャレンジと機会の両方を提供しました。新しいチップが機械学習パフォーマンスに関する曖昧な主張で発売されることはありませんでした。MLPerfという普遍的に受け入れられたベンチマークが、そのような主張を検証することになるからです。
SPECがCPU設計に影響を与えたように、MLPerfもAIハードウェアの方向性を形作り始めました。企業は、MLPerfのベンチマークを考慮に入れながら設計を最適化し始めました。そして、単なるパフォーマンスだけでなく、効率のメトリックも取り入れられました。これにより、巨大なトランスフォーマーモデルと環境意識の時代におけるエネルギー効率も提供できるイノベーションが促進されました。これらのベンチマークは、NvidiaやAMDなどの大手テック企業によって定期的に使用され、新しいハードウェアの紹介に使用されています。
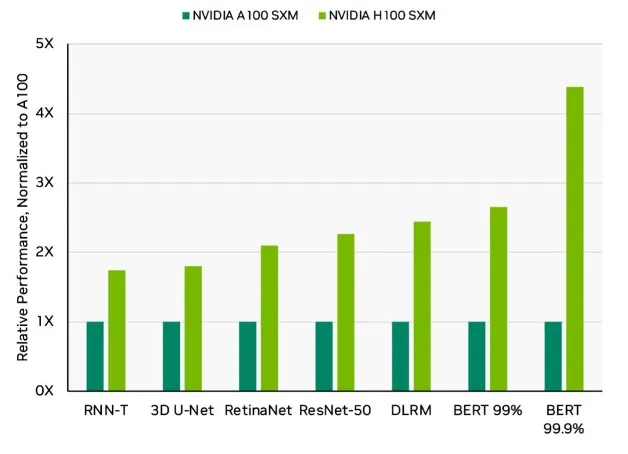
今日、MLCommonsによって管理されているMLPerfのようなベンチマークは数十あります。その中には以下のものが含まれます:
- MLPerf Training. 機械学習モデルのトレーニング中にシステムのパフォーマンスをベンチマークする(研究者により関連性が高い)。
- MLPerf Inference. クラウドを介してモデルをホストする企業にとってシステムのパフォーマンスをベンチマークする(データセンター、モバイルデバイス、エッジデバイス、小規模機械学習デバイスに焦点を当てた複数のバージョンが存在する)。
- MLPerf Training HPC. ハイパフォーマンスコンピューティングシステムに関連するワークロードのベンチマーク。
- MLPerf Storage. ストレージシステムに関連するワークロードのベンチマーク。
しかし、MLPerfには批判もあります。注目を集めるベンチマークには、ベンチマークテストに過度に最適化されることで実世界での適用性が損なわれるという懸念があります。さらに、ML分野の急速な進歩を反映するためにベンチマークを最新化し、関連性を保つという常に課題が存在します。
それでも、MLPerfの物語は、その前身と同様に、基本的な真実を浮き彫りにしています:ベンチマークは進歩を促進するのです。ベンチマークは単に最先端の状況を測定するだけでなく、それを形作ります。明確で厳しい目標を設定することにより、ベンチマークは集合的なエネルギーを集中させ、産業界や研究コミュニティを新たな領域に進展させます。そして、AIが可能性を再定義し続ける世界で、その複雑さを航海するための指針を持つことは、望ましいだけでなく、不可欠なものとなります。
生成AIのベンチマークの課題
AIハードウェア以外にも、生成AIの一形態である大規模言語モデルは、ベンチマークの焦点となっています。より一般的には基盤モデルと呼ばれ、これらはハードウェアや他の多くのタイプの機械学習モデルよりもベンチマークが困難です。
なぜなら、言語モデルの成功は単に計算速度や狭義のタスクにおける正確さにかかっているわけではなく、幅広いプロンプトと文脈にわたって一貫した、文脈に即した、情報量のある応答を生成する能力にかかっているからです。さらに、応答の「品質」を評価することは本質的に主観的であり、アプリケーションや評価者のバイアスによって異なる場合があります。これらの複雑さから、GPT-3やBERTのような言語モデルのためのベンチマークは、従来のベンチマークよりも多様で多面的である必要があります。
言語モデルの最もよく知られたベンチマークの1つは、2018年に開発されたGeneral Language Understanding Evaluation(GLUE)ベンチマークです。GLUEは単一のタスクだけでなく、感情分析からテキストの含意まで、9つの多様な言語タスクのコレクションでした。そのアイデアは、総合的な評価を提供し、モデルが1つのタスクだけでなく、さまざまな課題において言語を理解する能力を本当に持っていることを確認することでした。
GLUEの影響は即座で深いものでした。初めて、明確かつ一貫したベンチマークが言語モデルの評価に利用されました。すぐに、技術巨大企業と学術界が参加し、GLUEのリーダーボードのトップを競い合いました。
GPT-2がGLUEベンチマークに初めて評価されたとき、それは多くのモデルを上回る驚異的なスコアを獲得しました。これはGPT-2の優れた能力だけでなく、GLUEが明確な測定基準を提供した価値を示しています。GLUE上での「最先端」と主張する能力は、コミュニティでの望まれる認識になりました。
しかし、GLUEの成功は一面的なものでした。2019年末までに、多くのモデルがGLUEのリーダーボードを飽和させ、人間のベースラインに近いスコアを達成しました。この飽和は、ベンチマークのもう一つの重要な側面を浮き彫りにしました:ベンチマークが分野と共に進化する必要性です。この問題を解決するため、同じチームはSuperGLUEを導入しました。これは、さらに限界を押し広げるために設計された厳しいベンチマークです。
GLUE、SuperGLUE、およびSQuADのようなベンチマークは、感情分析や質問応答のような特定のタスクでモデルを評価するために使用されます。しかし、これらのベンチマークは、基礎となるモデルが目指すものの表面しか触れていません。タスク固有の正確さを超えて、これらのモデルを評価するために他の次元が現れています:
- 頑健性。 モデルはエッジケースや敵対的な入力をどの程度うまく処理できるか? 頑健性のベンチマークは、モデルが混乱させたり誤導したりするように設計された入力でモデルに挑戦し、悪意のある行為者や予期しないシナリオに対する弾力性を評価します。
- 一般化と転移学習。 基礎となるモデルは、明示的にトレーニングされていないタスクでも優れたパフォーマンスを発揮することが期待されています。モデルのゼロショットまたはフューショット学習能力を評価し、最小限または事前の例のないタスクを与えることは、その柔軟性と適応性を理解するために重要です。
- 対話性と一貫性。 チャットボットやバーチャルアシスタントのようなアプリケーションでは、モデルが長時間の対話や複数のやり取りでコンテキストを維持するかどうかが重要です。この領域のベンチマークでは、長い対話や複数のやり取りでのコンテキストの維持が関わる場合があります。
- 安全性と制御性。 モデルのサイズが増えるにつれて、これらのベンチマークは、モデルが有害な、不適切な、または非意味的な出力を生成しないことを保証します。
- カスタマイズ性。 基礎となるモデルがより広まるにつれて、特定のドメインやアプリケーションに合わせてモデルをカスタマイズする必要性が増しています。この領域のベンチマークでは、モデルが新しいデータセットでの微調整や特定の業界の専門用語やニュアンスにどの程度適応できるかが評価される場合があります。
興味深いことに、言語モデルのパフォーマンスが人間のパフォーマンスに近づくにつれて、従来は人間のパフォーマンスを評価するために使用されていたテストが言語モデルのベンチマークとして使用されるようになっています。たとえば、GPT-4はSAT、LSAT、および医療委員会などの試験でテストされました。SATでは1410点を獲得し、全国でトップ6%にランクインしました。GPT-4は、医療委員会のすべてのバージョンに合格することさえでき、平均点は80.7%でした。ただし、LSATでは148点と157点という低いスコアであり、それぞれ37番目と70番目のパーセンタイルに位置しました。
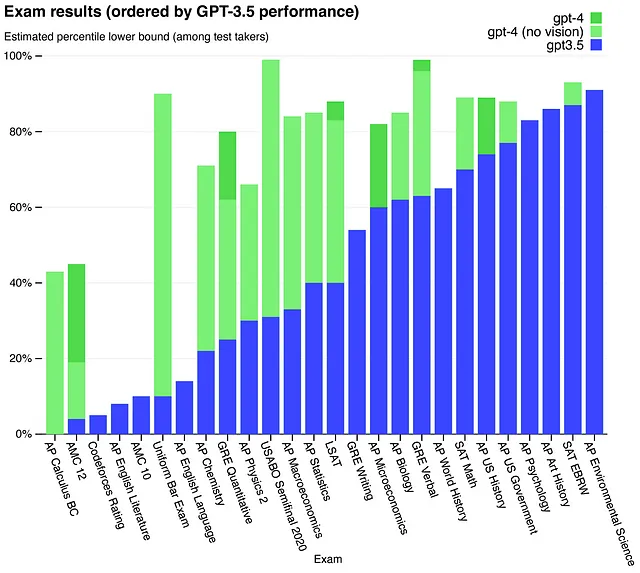
言語モデルが多くの領域で人間のパフォーマンスを追い越すようになるにつれて、ベンチマークアプローチの将来がどのように発展するかが興味深いです。
ベンチマークの将来
ベンチマークの将来は急速に進化し、新興技術やアプリケーションの幅広いスペクトラムに対応するために多様化しています。以下に、ベンチマークが実装されている新興領域のいくつかの例を示します:
- RobotPerf: ロボティクスが私たちの日常生活により統合されるにつれて、RobotPerfのようなベンチマークが作成されており、効率と安全基準の両方を満たすようにマシンを測定および加速しています。
- NeuroBench: 脳のインスパイアされたコンピューティングの領域では、NeuroBenchがニューロモーフィックシステムの評価を先駆けて行い、これらのアーキテクチャが神経プロセスをどれだけ再現しているかに関する洞察を提供しています。
- XRBench: バーチャルリアリティと拡張現実のセクターは、MetaやAppleが新たなハードウェアで参入することにより復活を遂げました。そのため、XRアプリケーションに焦点を当てたXRBenchが開発されました。これは没入型かつシームレスなユーザーエクスペリエンスにとって重要です。
- MAVBench: ドローンは、マルチエージェントシステムとバッテリーテクノロジーの進歩を通じて、ますます商業的に重要になっています。MAVbenchのようなベンチマークは、これらのシステムのパフォーマンスを最適化する上で重要な役割を果たします。
コンピュータサイエンスと機械学習コミュニティは、自分たちの領域の進歩を推進するためのベンチマークの重要性を十分に認識しています。AIのフラッグシップカンファレンスのひとつであるNeurIPSですら、データセットとベンチマークに専用のトラックを設けています。今年で3年目を迎えたこのトラックは、今年だけでも1,000近い投稿があるという驚異的な数を誇っています。このトレンドは、技術が着実に進展するにつれて、ベンチマークがリアルタイムでその軌跡を導き、形作り続けることを強調しています。
総括的な考え
ベンチマークの役割は、競技やAIの進歩を形作る上で非常に重要です。ベンチマークは、現状を反映する鏡としての役割と、未来の可能性を垣間見る窓としての役割を果たします。AIが医療から金融まで様々なアプリケーションや産業に影響を与える中で、頑健なベンチマークが重要になります。これにより、進歩が急速かつ意義深いものとなり、取り組むべき課題に向かって努力が向けられます。サー・ロジャー・バニスターが4分の壁を破ったように、時には最も困難なベンチマークは、征服されると何年にもわたって革新とインスピレーションの波を引き起こすことがあります。機械学習とコンピューティングの世界では、競争はまだ終わっていません。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
