「AIはオーディオブック制作をどのように革新しているのか? ニューラルテキストtoスピーチ技術により、電子書籍から数千冊の高品質なオーディオブックを作成する」
AIはニューラルテキストtoスピーチ技術を使い、数千冊の高品質なオーディオブックを作成する


現在では、多くの人々が書籍や他のメディアの代わりにオーディオブックを読んでいます。オーディオブックは、現在の読者が道路上で情報を楽しむだけでなく、子供や視覚障害者、新しい言語を学んでいる人などのグループにもコンテンツを利用しやすくすることができます。従来のオーディオブック制作技術は時間と費用がかかり、プロの人間のナレーションやLibriVoxのようなボランティア主導の取り組みなど、録音品質のばらつきが生じることがあります。これらの問題により、出版される書籍の増加に追いつくには時間と労力がかかります。
ただし、テキスト読み上げシステムのロボット的な性質や、目次、ページ番号、図表、脚注などのテキストを読み上げないようにする難しさにより、自動オーディオブック作成はこれまで苦労してきました。彼らは、さまざまなオンライン電子書籍コレクションから高品質のオーディオブックを作成するために、最近のニューラルテキスト読み上げ、表現豊かな読み上げ、スケーラブルな計算、関連コンテンツの自動認識などの最新の進展を取り入れた手法を提供しています。
彼らは、オープンソースに5,000冊以上のオーディオブック、合計35,000時間以上の音声を提供しています。また、デモンストレーションソフトウェアも提供しており、会議参加者がライブラリの本を声に出して読むだけで、自分自身の声でオーディオブックを作成できるようになっています。この研究では、HTMLベースの電子書籍を優れたオーディオブックに変換するためのスケーラブルな方法を紹介しています。パイプラインの基盤としては、分散オーケストレーションが可能なスケーラブルな機械学習プラットフォームであるSynapseMLが使用されています。彼らの配信チェーンは、数千冊のProject Gutenbergが提供する無料の電子書籍から始まります。これらの書籍は主にHTML形式で取り扱われており、自動解析に適しています。
- Amazon SageMakerで@remoteデコレータを使用してFalcon 7Bやその他のLLMを微調整する
- 「アメリカがGoogleの検索支配に挑戦する」
- 「GPT-4と説明可能なAI(XAI)によるAIの未来の解明」
その結果、Project GutenbergのHTMLページの完全なコレクションを整理し、同様の構造を持つファイルの多数のグループを特定することができました。主要な電子書籍のクラスは、これらのHTMLファイルのコレクションを使用して作成されたルールベースのHTML正規化器を使用して、標準形式に変換されました。このアプローチにより、大量の本を迅速かつ確実に解析することができました。最も重要なことは、読み上げると高品質の録音になるファイルに焦点を当てることができたということです。
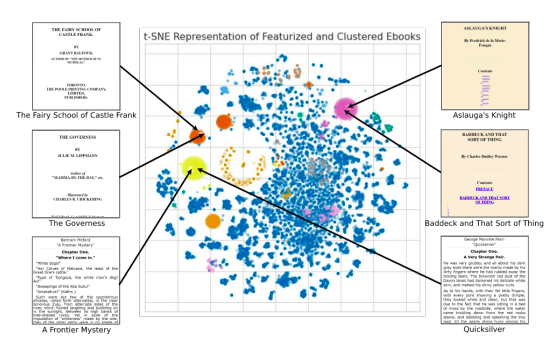
このクラスタリングの結果は、図1に示されており、Project Gutenbergのコレクションにおいて同様に構成された電子書籍のさまざまなグループが自発的に現れる様子が示されています。処理後、プレーンテキストのストリームを抽出し、テキスト読み上げアルゴリズムに供給することができます。さまざまなオーディオブックには多くの読み方のテクニックが必要です。ノンフィクションには明確で客観的な声が最適であり、対話があるフィクションには表現豊かな読み上げと少しの「演技」が適しています。ただし、ライブデモンストレーションでは、テキストの声、ペース、ピッチ、抑揚を変更するオプションを提供します。ほとんどの本では、明確で中立的なニューラルテキスト読み上げの声を使用しています。
彼らは、ゼロショットテキスト読み上げ技術を使用して、登録された少数の録音から効果的に声の特徴を転送し、ユーザーの声を再現しています。これにより、少量のキャプチャされた音声だけで、ユーザーは迅速に自分の声でオーディオブックを作成することができます。また、音声と感情の推論システムを使用して、文脈に基づいて読み上げの声やトーンを動的に変更し、感情的なテキスト読み上げを行います。これにより、複数の人物や動的な対話を持つシーケンスのリアルさと興味が向上します。
これを実現するために、まずテキストをナレーションと会話に分割し、各対話ごとに異なる話者を割り当てます。次に、セルフスーパーバイズド学習を使用して、各対話の感情的なトーンを予測します。最後に、異なる声と感情をナレーターとキャラクターの会話に割り当てるために、マルチスタイルとコンテキストベースのニューラルテキスト読み上げモデルを使用します。彼らは、このアプローチがオーディオブックの利用可能性とアクセシビリティを大幅に向上させる可能性があると考えています。
を日本語に翻訳すると、
となります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- コンテンツを人間味を持たせ、AIの盗作を克服する方法
- 「Amazon QuickSightでワードクラウドとしてAmazon Comprehendの分析結果を可視化する」
- 「Hugging Faceを使用してAmazon SageMakerでのメール分類により、クライアントの成功管理を加速する」
- 「Amazon SageMakerは、個々のユーザーのためにAmazon SageMaker Studioのセットアップを簡素化します」
- 「ロボットに対するより柔らかいアプローチ」
- 「3Dプリントされた『生物性材料』が汚染された水を浄化することができる」
- 「AIプロジェクトが、アルゼンチンの軍事独裁政権下で行方不明になった子供たちの成人した顔を想像します」






