「AIはデータガバナンスにどのように影響を与えているのか?」
AIのデータガバナンスへの影響は?
データガバナンスとAIの相互関係

生成的AIは既にデータガバナンスの世界を揺るがし始めており、今後もその影響は続くでしょう。
ChatGPTのリリースからわずか6ヶ月ですが、もう振り返りが必要な感じがします。この記事では、生成的AIがデータガバナンスに与える影響や、近い将来の展望について探っていきます。ここで強調したいのは、近いということです。なぜなら、事象は速く進化し、様々な方向に進む可能性があるからです。この記事はデータガバナンスの次の100年を予測するものではなく、現在起こっている変化と将来の変化について実践的に見ていくものです。
さて、まずはデータガバナンスがどのようなものかを思い出しましょう。
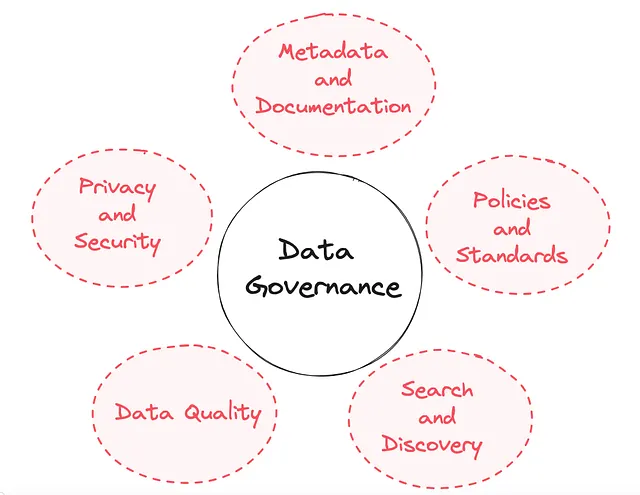
簡単に言えば、データガバナンスとは組織が信頼性のあるデータを確保するために従うルールやプロセスのことです。以下の5つの主要な領域が含まれます:
- CMU、AI2、およびワシントン大学の研究グループが、NLPositionalityというAIフレームワークを導入しましたこれは、デザインのバイアスを特徴づけ、NLPのデータセットとモデルの位置性を定量化するためのものです
- 「Langchain x OpenAI x Streamlit — ラップソングジェネレーター🎙️」
- 「Google Sheetsにおける探索的データ分析」
- メタデータとドキュメンテーション
- 検索と発見
- ポリシーと標準
- データプライバシーとセキュリティ
- データ品質
この記事では、生成的AIを取り入れることで、それぞれの領域がどのように進化するかを見ていきます。
さあ、始めましょう!
1. メタデータとドキュメンテーション
メタデータとドキュメンテーションはおそらくデータガバナンスの中でも最も重要な部分であり、他の部分はこれが適切に行われていることに重く依存しています。AIは既に始まっており、データの文脈を作成する方法を変え続けています。ただし、あまり期待しすぎることは避けた方が良いです。ドキュメンテーションに関しては、まだ人間の介入が必要です。
データに関する文脈を作り出す、またはデータを文書化するには2つの部分があります。最初の要素は、多くの企業に共通の一般的な情報を文書化することで、仕事の約70%を占めます。非常に基本的な例としては、「メール」という定義がすべての企業に共通しています。2番目の部分は、会社固有の特定のノウハウを記述することです。
ここが興味深い部分です:最初の70%はAIがほとんどの作業を行うことができます。なぜなら、最初の要素は一般的な知識を必要とし、生成的AIはそれを扱うのに優れているからです。
では、会社固有の知識はどうでしょう?すべての組織はユニークであり、このユニークさが独自の会社言語を生み出します。この言語は、指標やKPI、ビジネス定義として表れます。そして、それは外部からインポートできるものではありません。それはビジネスを最もよく知る人々、つまり従業員によって生み出されるものです。
データリーダーとの会話で、私はしばしばこれらのビジネスコンセプトに共有理解を生み出す方法について議論します。多くのリーダーは、このアラインメントを実現するために、ドメインチームを同じ部屋に集めて話し合い、議論し、最適な定義に合意することで実現していると共有しています。
たとえば、「顧客」という定義を取り上げましょう。定額制のビジネスにとって、顧客とは現在サービスに登録している人のことかもしれません。しかし、小売業にとっては、顧客は過去12ヶ月以内に購入した人であるかもしれません。各企業は最も自社に合った方法で「顧客」を定義し、この理解は通常、組織内部から生まれます。
このような特異な知識に関しては、AIは賢くてもまだその部分を担当することはできません。AIは会議に参加したり、議論に加わったり、新しいコンセプトを育てるのを手助けしたりすることはできません。Andreessen Horowitzにとっては、これが可能になるのはAIの第2の波が訪れたときかもしれません。現時点では、私たちはまだ第1の波にいます。
また、Benn Stancilが提起した質問に触れてみたいと思います。Bennは「ボットが必要に応じてデータのドキュメンテーションを書いてくれるなら、それを書き留める意味は何ですか?」と尋ねています。
これには一定の真実があります。もし生成型AIが必要な時にコンテンツを生成できるなら、なぜすべてを文書化する手間をかける必要があるのでしょうか?残念ながら、それは二つの理由からうまくいきません。
まず、以前に説明したように、文書化の一部はAIがまだ捉えきれない企業の固有の側面をカバーしています。これには人間の専門知識が必要です。AIではリアルタイムで生成することはできません。
そして、AIは進化しているとはいえ、完全ではありません。生成されるデータは常に正確ではありません。AIが生成するコンテンツは、人間がチェックして確認する必要があります。
2. 検索と発見
生成型AIは、文書作成方法だけでなく、文書の利用方法も変えています。実際、検索と発見の方法はパラダイムシフトを起こしています。従来の方法では、アナリストがデータカタログを検索して関連情報を見つけるという手法はすでに時代遅れになりつつあります。
真のゲームチェンジャーは、AIが会社の全員に対して「個人データアシスタント」となる能力にあります。一部のデータカタログでは、AIに特定のデータに関する問い合わせをすることができます。たとえば、「データを使用してアクションXを実行できるか?」、「データを使用してYを達成することができない理由は何ですか?」、「Zを示すデータを持っていますか?」といった質問ができます。データが適切なコンテキストで充実している場合、AIはこのコンテキストを会社全体に伝えるのに役立ちます。
予想されるもう一つの進展は、AIがデータカタログを受け身の存在から能動的な助手に変えることです。考えてみてください。もしもあなたが式を誤って使用している場合、AIアシスタントが注意を促すことができます。同様に、既に存在するクエリを書こうとしている場合、AIはそれを知らせ、既存の作業に案内することができます。
過去には、データカタログはそこに座って、回答を探し求めるためにあなたが選別するのを待っていました。しかし、AIによって、カタログは積極的に助けるようになり、必要とする前に洞察と解決策を提供するようになるかもしれません。これはデータとの関わり方の完全なシフトであり、非常に近い将来に実現するかもしれません。
ただし、AIアシスタントが効果的に機能するためには、データカタログを維持する必要があります。AIアシスタントがステークホルダーに信頼性のあるガイダンスを提供するためには、基礎となる文書化が100%信頼できる必要があります。カタログが適切に維持されていない場合やポリシーが明確に定義されていない場合、AIアシスタントは会社全体に誤った情報を広めてしまいます。これは何も情報がないよりも有害であり、誤ったコンテキストに基づいた誤った意思決定につながる可能性があります。
おそらく理解しているかもしれませんが、AIとデータガバナンスは相互依存関係にあります。AIはデータガバナンスを向上させることができますが、その代わりにAIの能力を引き出すためには堅牢なデータガバナンスが必要です。これにより、各要素が互いを高める好循環が生まれます。ただし、忘れてはならないのは、どの要素も他の要素に置き換えることはできないということです。

3. データポリシーと基準
データガバナンスのもう一つの重要な要素は、ガバナンスルールの策定と実施です。
これには組織内でのデータの所有権とドメインの定義が含まれます。現時点では、AIはこれらのポリシーと基準の定義には対応していません。AIはルールの実行や違反のフラグ付けには優れていますが、ルール自体の作成には不足しています。
これには単純な理由があります。所有権やドメインの定義は、人間の政治に関係します。たとえば、所有権は、組織内で特定のデータセットに対する権限を持つ人を決定することを意味します。これにはデータの使用方法やアクセス権限、保守とセキュリティなどの決定権が含まれます。これらの決定には、各自、チーム、または部門間での交渉が必要であり、それぞれが独自の利害や視点を持っています。そして、明らかな理由から、人間の政治はAIで置き換えることはできません。
ですから、人間がこのガバナンスの側面で今後も重要な役割を果たし続けると予想されます。生成型AIは所有権フレームワークの策定やデータドメインの提案に役立つことができますが、人間を関与させることは依然として必要です。
4. データのプライバシーとセキュリティ
しかし、生成型AIはガバナンスのプライバシー部門を揺るがすことになるでしょう。個人情報の管理は、伝統的に恐れられるガバナンスの一環です。誰もそれを楽しんでいません。それは、機密データが保護されるように複雑な許可のアーキテクチャを手動で作成することを含みます。
良いニュースは、AIがこのプロセスの大部分を自動化できるということです。ユーザーの数やそれぞれの役割などのパラメーターを考慮して、AIはアクセス権のルールを作成できます。アクセス権のアーキテクチャは、基本的にコードベースであるため、AIの能力とよく一致しています。AIシステムはこれらのパラメーターを処理し、関連するコードを生成し、効率的にデータアクセスを管理するために適用することができます。
AIが大きな影響を与えることができる別の領域は、個人を特定する情報(PII)の管理です。現在、PIIのタグ付けは通常手動で行われており、担当者にとって負担となっています。これはAIが完全に自動化できるものです。AIのパターン認識能力を活用することで、PIIのタグ付けは人間が行うよりも正確に行うことができます。この意味で、AIの使用は実際にはプライバシー保護の管理方法を改善することができます。
これは、AIが完全に人間の関与を置き換えることを意味するものではありません。AIの能力にもかかわらず、予期しない状況の管理や判断が必要な場合には、人間の監督が依然として必要です。
5. データの品質
ガバナンスの重要な柱であるデータの品質を忘れてはなりません。データの品質は、企業が使用する情報が正確で一貫性があり信頼性があることを保証します。データの品質の維持は常に複雑な試みでしたが、生成型AIによって既に変化が始まっています。
先述のように、AIはルールを適用し違反を検出するのに非常に優れています。これにより、アルゴリズムはデータの異常を識別することが容易になります。AIがデータの品質の異なる側面にどのように影響を与えるかについての詳細な説明は、この記事で見つけることができます。
AIはデータの品質の技術的な障壁も低くすることができます。これは、すでにSODAが実現していることです。彼らの新しいツールであるSodaGPTは、自然言語だけを使用してデータ品質のチェックを行うためのノーコードアプローチを提供します。これにより、データの品質維持が直感的でアクセスしやすくなります。
結論
AIがデータガバナンスを効果的に促進する方法を見てきました。多くの変化が既に起こっており、これからも続いていくでしょう。
ただし、AIはすでに確立された基盤の上に構築される必要があります。AIが会社の検索と発見の体験を変えるためには、既にドキュメンテーションを維持している必要があります。AIは強力ですが、欠陥のあるシステムを奇跡的に修復することはできません。
また、AIがデータの文脈の大部分を生成できるとしても、人間の要素を完全に置き換えることはできません。各企業に固有の知識を文書化し検証するためには、私たちにはまだ人間が必要です。したがって、ガバナンスの将来に対する私たちの予測は次のようになります:AIによってターボチャージされ、人間の識別力と認識力に基づいています。
私たちについて
CastorDocでは、Notion、Figma、Slackの世代向けのデータドキュメンテーションツールを開発しています。
詳細をチェックしたいですか?お問い合わせいただければ、デモをご紹介します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
