「文書理解の進展」
Advancements in Document Understanding
Google Research、Athenaチームのソフトウェアエンジニア、サンディープ・タタ氏による投稿
過去数年間で、複雑なビジネスドキュメントを自動的に処理し、それらを構造化されたオブジェクトに変換するシステムの進歩が急速に進んでいます。領収書、保険見積もり、財務報告書などのドキュメントからデータを自動的に抽出するシステムは、エラーが多く手作業が必要な作業を回避することで、ビジネスワークフローの効率を劇的に向上させる潜在能力を持っています。Transformerアーキテクチャに基づいた最近のモデルは、驚異的な精度の向上を示しています。PaLM 2などのより大規模なモデルは、これらのビジネスワークフローをさらに効率化するために活用されています。しかし、学術文献で使用されるデータセットは、現実のユースケースで見られる課題を捉えることができていません。その結果、学術ベンチマークはモデルの精度を高く報告していますが、同じモデルを複雑な現実世界のアプリケーションに使用すると、精度が低下します。
KDD 2023で発表された「VRDU: A Benchmark for Visually-rich Document Understanding」では、このギャップを埋め、研究者がドキュメント理解タスクの進捗状況をより正確に追跡できるようにするため、新しいVisually Rich Document Understanding(VRDU)データセットの公開を発表しています。私たちは、ドキュメント理解モデルが頻繁に使用される実世界のドキュメントの種類に基づいて、良いドキュメント理解ベンチマークのための5つの要件をリストアップしています。そして、現在研究コミュニティで使用されているほとんどのデータセットがこれらの要件のいずれかを満たしていないことを説明し、一方でVRDUはこれらの要件をすべて満たしていることを説明しています。私たちは、VRDUデータセットと評価コードをクリエイティブ・コモンズ・ライセンスの下で公開することを発表できることを喜んでいます。
ベンチマークの要件
まず、実世界のユースケースでの最先端のモデルの精度(例:FormNetやLayoutLMv2との比較)を学術ベンチマーク(例:FUNSD、CORD、SROIE)と比較しました。その結果、最先端のモデルは学術ベンチマークの結果とは一致せず、実世界でははるかに低い精度を提供しました。次に、ドキュメント理解モデルが頻繁に使用される典型的なデータセットを学術ベンチマークと比較し、実世界のアプリケーションの複雑さをより良く捉えるための5つのデータセットの要件を特定しました:
- ビッグテックと生成AI:ビッグテックが生成AIを制御するのか?
- なぜ特徴スケーリングは機械学習において重要なのか?6つの特徴スケーリング技術についての議論
- 「ミケランジェロのAIいとこ:ニューランジェロは高精度な3D表面再構築が可能なAIモデルです[コードも含まれています]」
- リッチスキーマ:実際の実務では、構造化抽出のためのさまざまな豊富なスキーマが存在します。エンティティには異なるデータ型(数値、文字列、日付など)があり、単一のドキュメント内で必須、オプション、または繰り返しの場合もあり、さらにネストする場合もあります。ヘッダ、質問、回答などの単純なフラットなスキーマの抽出タスクでは、実務でよく遭遇する問題を反映していません。
- レイアウト豊かなドキュメント:ドキュメントには複雑なレイアウト要素が含まれている必要があります。実践的な設定での課題は、ドキュメントにテーブル、キーと値のペア、単一列と二列のレイアウトの切り替え、異なるセクションのフォントサイズの変化、キャプション付きの画像や脚注などが含まれることです。これに対して、ほとんどのドキュメントが文、段落、セクションヘッダを持つ文章で構成されているデータセットとは対照的です。これは、長い入力に関する古典的な自然言語処理文献の焦点となるようなドキュメントの種類です。
- 異なるテンプレート:ベンチマークには異なる構造のレイアウトやテンプレートが含まれるべきです。特定のテンプレートから抽出することは、高容量モデルにとっては容易ですが、実際の実務では新しいテンプレート/レイアウトにも対応できる汎化能力が必要です。ベンチマークのトレーニングとテストの分割によって測定される能力です。
- 高品質なOCR:ドキュメントは高品質な光学文字認識(OCR)の結果を持っている必要があります。このベンチマークでは、VRDUタスク自体に焦点を当て、OCRエンジンの選択によってもたらされる変動性を除外することを目指しています。
- トークンレベルの注釈:ドキュメントには、対応する入力テキストの一部としてマッピングできる正解の注釈が含まれている必要があります。これにより、各トークンを対応するエンティティの一部として注釈付けすることができます。これは、単にエンティティから抽出するための値のテキストを提供するだけではありません。これは、与えられた値に偶発的な一致があることを心配する必要がないクリーンなトレーニングデータの生成に重要です。たとえば、一部の領収書では、「税抜き合計」フィールドが「合計」フィールドと同じ値を持つ場合があります。トークンレベルの注釈があれば、両方の一致する値が「合計」フィールドの正解としてマークされたトレーニングデータを生成することを防ぐことができ、ノイズのない例を生成できます。
 |
VRDUのデータセットとタスク
VRDUデータセットは、登録フォームと広告購入フォームの2つの公開データセットを組み合わせたものです。これらのデータセットは、実世界の使用例を代表する例を提供し、上記の5つのベンチマーク要件を満たしています。
広告購入フォームのデータセットは、政治広告の詳細を記録した641のドキュメントから構成されています。各ドキュメントは、テレビ局と選挙団体によって署名された請求書または領収書です。これらのドキュメントは、テーブル、複数の列、キーと値のペアを使用して、商品名、放送日、総額、発売日時などの広告情報を記録しています。
登録フォームのデータセットは、アメリカ政府に外国エージェントが登録する際の情報を含む1,915のドキュメントから構成されています。各ドキュメントは、公開開示を必要とする活動に関与する外国エージェントの重要な情報を記録しています。内容には、登録者の名前、関連する局の住所、活動の目的、その他の詳細が含まれます。
公共のFederal Communications Commission(FCC)およびForeign Agents Registration Act(FARA)のサイトからランダムにドキュメントを収集し、Google CloudのOCRを使用して画像をテキストに変換しました。数ページにわたる一部のドキュメントは処理が2分未満で完了しなかったため、廃棄しました。これにより、非常に長いドキュメントを手動で注釈付けする必要がなくなりました。1つのドキュメントについて1時間以上かかる作業です。その後、ドキュメントラベリングの経験のある注釈者チームのためにスキーマと対応するラベリングの指示を定義しました。
注釈者には、私たち自身がラベル付けしたいくつかのサンプルラベル付きドキュメントも提供されました。タスクは、各ドキュメントを調査し、スキーマからエンティティの各出現箇所にバウンディングボックスを描画し、そのバウンディングボックスを対象のエンティティに関連付けることでした。ラベリングの最初のラウンド後、専門家のプールが結果をレビューするように割り当てられました。修正された結果は、公開されたVRDUデータセットに含まれています。各データセットのラベリングプロトコルとスキーマの詳細については、論文を参照してください。
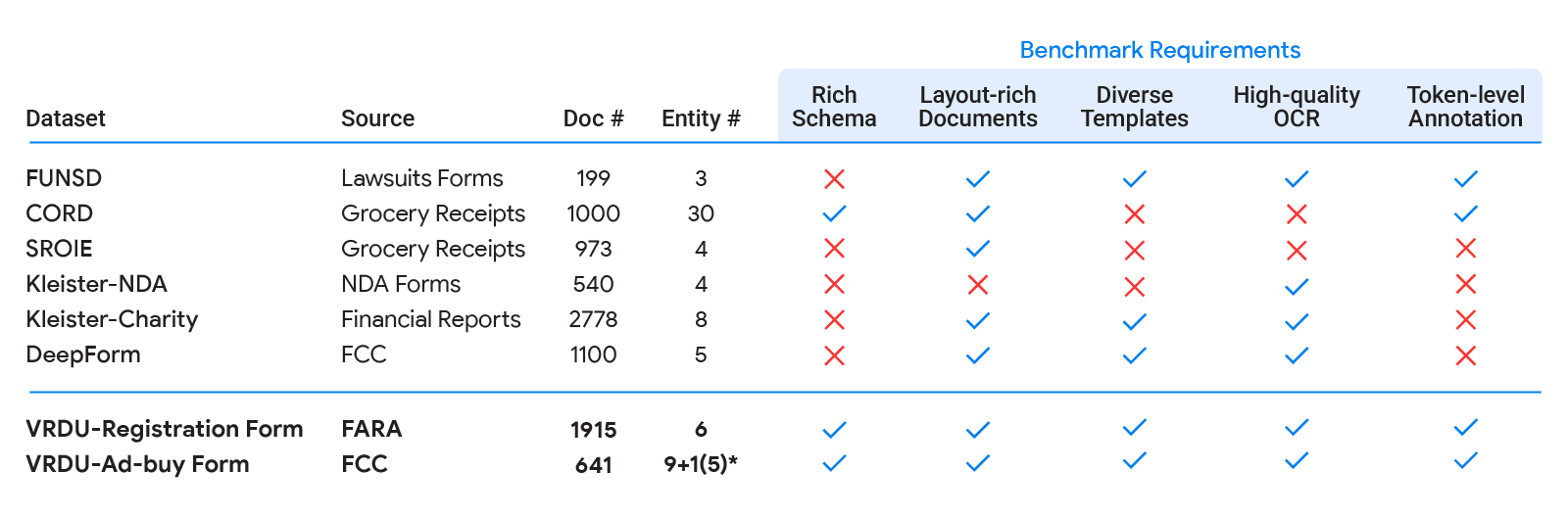 |
| 既存の学術ベンチマーク(FUNSD、CORD、SROIE、Kleister-NDA、Kleister-Charity、DeepForm)は、私たちが良いドキュメント理解ベンチマークのために特定した5つの要件のうち1つ以上を満たしていません。VRDUはそれらすべてを満たしています。これらのデータセットがそれぞれどのように要件を満たしていないかについての背景については、私たちの論文を参照してください。 |
私たちは、それぞれ10、50、100、および200のサンプルで4つの異なるモデルトレーニングセットを構築しました。次に、以下の3つのタスクを使用してVRDUデータセットを評価しました:(1)シングルテンプレート学習、(2)ミックステンプレート学習、および(3)未知のテンプレート学習。これらのタスクの各々について、テストセットに300のドキュメントを含めました。テストセットでのF1スコアを使用してモデルを評価します。
- シングルテンプレート学習(STL):これは、トレーニング、テスト、および検証セットが単一のテンプレートのみを含む最も単純なシナリオです。このシンプルなタスクは、モデルが固定されたテンプレートに対処する能力を評価するために設計されています。当然ながら、このタスクでは非常に高いF1スコア(0.90以上)が期待されます。
- ミックステンプレート学習(MTL):このタスクは、関連する論文のほとんどが使用するタスクと似ています。トレーニング、テスト、および検証セットはすべて同じテンプレートに属するドキュメントを含んでいます。データセットからドキュメントをランダムにサンプリングし、各テンプレートの分布がサンプリング中に変更されないように構築します。
- 未知のテンプレート学習(UTL):これは最もチャレンジングな設定であり、モデルが未知のテンプレートに対して汎化できるかどうかを評価します。たとえば、登録フォームのデータセットでは、3つのテンプレートのうち2つを使用してモデルをトレーニングし、残りの1つを使用してモデルをテストします。トレーニング、テスト、および検証セットのドキュメントは、異なるテンプレートの互いに素なセットから描画されます。私たちの知る限り、以前のベンチマークやデータセットには、トレーニング中に見たことのないテンプレートに汎化するモデルの能力を評価するために明示的に設計されたタスクは提供されていません。
目的は、モデルのデータ効率を評価できるようにすることです。私たちの論文では、STL、MTL、およびUTLのタスクを使用して、2つの最近のモデルを比較し、3つの観察結果を得ました。まず、他のベンチマークとは異なり、VRDUは挑戦的であり、モデルには改善の余地がたくさんあることを示しています。第二に、最新のモデルでもフューショットのパフォーマンスは驚くほど低く、最高のモデルでもF1スコアが0.60未満になることを示しています。第三に、モデルは構造化された繰り返しフィールドに対処するのに苦労し、特にそれらに対して非常に低いパフォーマンスを示します。
結論
私たちは、研究者が文書理解のタスクの進捗状況をより良く追跡できるようにするための新しいVisually Rich Document Understanding(VRDU)データセットを公開します。私たちは、なぜVRDUがこのドメインの実践的な課題をよりよく反映しているのかを説明します。また、VRDUのタスクが難しいことを示す実験も行い、最新のモデルが文献で通常使用されるデータセットと比較して改善の余地があることを示しています。F1スコアが0.90以上が一般的です。VRDUデータセットと評価コードの公開が、研究チームが文書理解の最先端を進めるのに役立つことを願っています。
謝辞
論文の共著者であるSandeep Tataと共に、Zilong Wang、Yichao Zhou、Wei Wei、Chen-Yu Leeに多くの感謝を申し上げます。貴重な洞察を提供してくれたGoogle ResearchとCloud AIチームのMarc Najork、Riham Mansour、および多くのパートナーにも感謝します。この投稿でのアニメーションの作成にはJohn Guilyardに感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「ゴリラ – API呼び出しの使用能力を向上させる大規模言語モデルの強化」 翻訳結果はこちらです
- このAI論文は、古典的なコンピュータによって生成される敵対的攻撃に対して、量子マシンラーニングモデルがより良く防御される可能性があることを示唆しています
- 「自己修正手法を通じて、大規模言語モデル(LLM)の強化」
- 「生成AIプロジェクトライフサイクル」
- 「目と耳を持つChatGPT:BuboGPTは、マルチモーダルLLMsにおいて視覚的なグラウンディングを可能にするAIアプローチです」
- 「7/8から13/8までの週のトップ重要なコンピュータビジョン」
- 「ソフトウェア開発者のための機械学習フレームワークの探求」






