「あなたのデータに基づいたLLMにドメイン固有の知識を追加する方法」
Adding domain-specific knowledge to LLM based on your data
あなたのLLMを専門家に変える
イントロダクション
最近、大規模言語モデル(LLM)は私たちの仕事やテクノロジーとの相互作用の方法を根本的に変え、執筆アシスタント、コード生成器、さらには創造的な共同作業者としてさまざまなドメインで有益なツールとなっています。彼らの文脈理解、人間らしいテキストの生成、そしてさまざまな言語関連のタスクの実行能力は、彼らを人工知能研究の最前線に押し上げました。
LLMは一般的なテキストの生成において優れていますが、高度に専門化されたドメインに直面した場合、正確な知識と微妙な理解を要求する場合には苦労することがよくあります。ドメイン固有のタスクに使用する場合、これらのモデルは制限があるか、あるいは誤った情報を生成する場合があります。これは、LLMにドメイン知識を組み込む必要性を浮き彫りにしています。これにより、彼らは複雑な業界特有の専門用語をよりうまく扱い、より微妙な文脈理解を示し、誤った情報を生成するリスクを制限することができます。
この記事では、LLMにドメイン知識を注入するためのいくつかの戦略と技術の一つを紹介します。これにより、クエリの注入時にLLMにドキュメントの一部をコンテキストとして追加することで、特定の専門的なコンテキストで最良のパフォーマンスを発揮することができます。
この手法はどの種類のドキュメントでも機能し、インターネットへのアクセスは必要なく、安全でオープンソースのテクノロジーを使用してコンピュータ上で実行されます。そのため、第三者のウェブサイトがアクセスすることを望まない個人や機密データに使用することができます。
原則
以下は、その動作の詳細です:
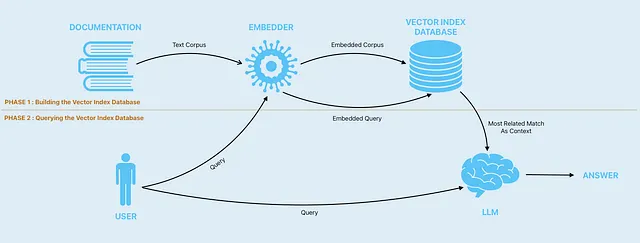
最初のステップは、ドキュメントを取り、そのドキュメントに基づいてベクトルインデックスデータベースを構築することです。ベクトルデータベースは、高次元のベクトルを効率的に格納し、クエリを行うために設計されたデータベースの一種です。これらのデータベースは、高速な類似性検索と意味的検索を可能にし、ユーザーがベクトルを見つけることができます…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
