「個人データへのアクセス」
Access to Personal Data
企業があなたのことについて持っている広範で時折驚くべきデータ、分析するために準備ができて待っています

データプライバシー法は世界中の多くの国で登場し、あなたが他人があなたをどのように見ているかを学ぶ機会を提供しています。ほとんどの法律は、一般データ保護規則(GDPR)として一般的に知られている欧州連合のGDPRと似ています。これには、組織があなたについて保存している個人データの種類、保存理由、使用方法、保存期間を告知する規定が含まれています。
しかし、法律にはしばしば見落とされるデータポータビリティという要件も含まれています。データポータビリティは、組織がリクエストに応じて、現在あなたについて保存しているデータの機械可読なコピーを提供することを要求します。GDPRでは、この権利は「データ主体のアクセス権」として第15条で定義されています。組織が持っているデータには、多様な特徴を持ち、整理されていることが多く、いくつかのデータ分析、モデリング、可視化のタスクに適しています。
この記事では、私が日常的に関わるいくつかの企業からデータをリクエストした経験を共有します。データをリクエストするためのヒントや、データサイエンスや個人的な洞察にデータを使用するためのアイデアも提供します。
自分の音楽の趣味についてしっかりと把握していると思いますか?私は広範で多様な音楽の趣味を持っていると思っていました。しかし、Appleによると、私はもっぱらロック好きのようです。
地理的データマッピングのスキルを磨きたいですか?これらのデータソースは、非常に多くのジオコーディングされたデータを提供します。
時系列モデリングのスキルを試してみたいですか?複数のデータセットには、詳細な時系列の観測データが含まれています。
最も良いニュースは、これがあなたのデータです。ライセンスや許可は必要ありません。
シートベルトを締めてください-受け取るデータの種類は多岐にわたります。行える分析やモデリングの種類は容易ではありません。そして、自分自身や他人があなたをどのように見ているかについて得る洞察は興味深いものです。
データの洞察に焦点を当てるため、および簡潔さを保つために、この記事にはコードは含まれていません。しかし、皆さんはコードが好きですので、ここに私がデータ分析に使用したいくつかのノートブックを含むリポジトリへのリンクを提供します。
データを取得する
自分に関するデータを持っている組織のリストを作成すると、リストが大きいことにすぐに気づくでしょう。ソーシャルメディア企業、オンライン小売業者、携帯電話キャリア、インターネットサービスプロバイダ、ホームオートメーションおよびセキュリティサービス、ストリーミングエンターテイメントプロバイダなど、あなたについてデータを保存している組織のカテゴリは数多くあります。これらのグループからデータをリクエストすることは非常に時間がかかる場合があります。
私の分析を管理可能にするために、私はFacebook、Google、Microsoft、Apple、Amazon、および自分の携帯キャリアであるVerizonに限定してデータのリクエストを行いました。以下は、データのリクエストと応答プロセスに関する私の経験をまとめた表です:

以下は、データをリクエストするために使用したリンクと、ベンダーから提供されたデータのドキュメントに関する情報です。
私は健康とフィットネスのデータを追跡するためにApple Watchを使用しています。このデータは、一般のAppleウェブサイトからリクエストする他のAppleデータとは別にアクセスされます。そのため、上記のテーブルには2つの別々のAppleエントリが表示され、Appleのデータについては2つのトピックで説明します。
受け取るデータの量と種類は、特定の会社との関わり方によって異なります。たとえば、私はあまりソーシャルメディアを使用しません。したがって、Facebookから受け取ったデータの量はそれほど多くないのは当然です。対照的に、私はApple製品とサービスをたくさん使用しています。Appleからは幅広い範囲の大量のデータを受け取りました。
会社ごとに複数のアイデンティティを持っている場合、各アイデンティティのデータをリクエストする必要があります。たとえば、GoogleがGoogle Playアカウントの1つのメールアドレスとGmailアカウントの異なるメールアドレスであなたを認識している場合、Googleがあなたに関して保存しているデータの全体像を把握するために、各アドレスに対してデータリクエストを行う必要があります。
上記の表では、ターゲット会社からデータをリクエストするために使用したリンクを示しています。これらのリンクは、この記事が公開された時点でのものですが、時間の経過とともに変更される可能性があります。一般的に、データをリクエストするための手順については、会社のホームページの「プライバシー」「プライバシー権利」または類似のリンクで説明が見つかることがあります。これらのリンクは、ホームページの一番下に頻繁に表示されます。

通常、データをリクエストするための実際のページへのリンクを取得するために、プライバシー権利について説明しているドキュメントを読み、アクセス方法、データのエクスポート、データの移植などのトピックを検索する必要があります。
最後に、データをリクエストするプロセス、応答のタイムリネス、データに関する説明の品質は、会社によって大きく異なります。忍耐強く努力してください。すぐに豊富なデータと知識が得られるでしょう。
私のデータの洞察
ここでは、それぞれの会社から受け取ったデータファイルのレビューと、より興味深いファイルを分析した後のいくつかの観察、さらなるデータ分析とモデリングの機会を指摘します。
Facebookからのダウンロードには、私のFacebook Messengerアカウントの個々のメッセージスレッドを含まない51の.jsonファイルが含まれていました。Facebookは、ダウンロードウェブサイトでファイルに関するいくつかの高レベルのドキュメントを提供しています。
私のFacebookのログインアクティビティ、ログインに使用したデバイス、ログイン時の推定地理的位置など、アカウントの活動に関する管理データは、いくつかのファイルにわたって表示されます。これらのファイルには特に興味深いものはありませんが、記録された活動時のIPアドレスから推測される場合でも、位置データは驚くほど正確であるように思われます。
本当に興味深いデータは、Facebookの外部アプリとウェブの活動を追跡するファイルに現れ始めました。そのファイルのデータと、既にFacebookが持っている私のFacebookプロフィールのデータを組み合わせることで、特定のFacebook広告主によってターゲットとして選ばれる人口統計的な情報が描かれます。外部アプリのファイルは、Facebookでのプロファイリングと広告のプロセスがどのように機能するかを示すものです。
ファイルを見てみましょう。ファイル名は次のとおりです:
“/apps_and_websites_off_of_facebook/your_off-facebook_activity.json”
これには、過去2年間に私が441の異なる非Facebookウェブサイトで行ったアクションの1,860のレコードが含まれています。以下は、そのファイルが記録しているウェブサイトとアクションの種類の編集サンプルです:
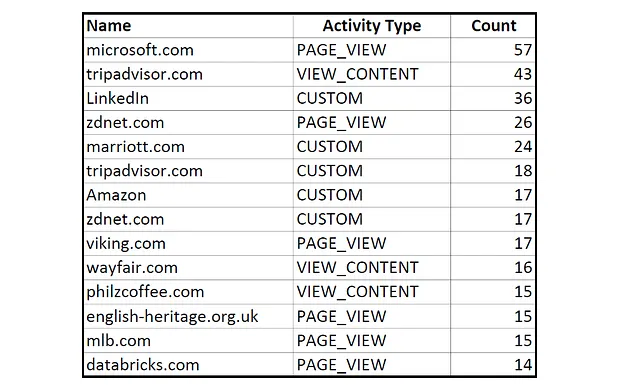
いくつかの技術と旅行に関連するサイトが私の非Facebook活動リストの上位にあります。次に、私の人口統計プロフィールを見てみましょう。
ファイル名は次のとおりです:
“ads_information/other_categories_used_to_reach_you.json”
これには、私がFacebookプロフィールのデータ、Facebookの友達、Facebookでの活動、およびFacebook外のアプリとウェブの活動に基づいてFacebookが私に割り当てた人口統計カテゴリのリストが含まれています。以下は、人口統計カテゴリの編集サンプルです:

上記のほとんどのカテゴリは、私のプロフィール、デバイスの使用パターン、および友達に基づいています。 「頻繁な旅行者」および「頻繁な国際旅行者」のカテゴリは、おそらくFacebook以外のウェブ活動から来ています。 これまでのところ、これはすべて正しいです。
最後に、次のファイルがあります:
「ads_information/advertisers_using_your_activity_or_information.json」
ファイルタイトルの「advertisers_using_your_activity_or_information」から、Facebookが私のデータを広告主に提供し、広告主がそれを使用してFacebookを通じて私に広告をターゲットにしていると推測できます。 このファイルには、私に広告を表示した広告主、または少なくとも私のデータに基づいて広告を表示しようと考えた広告主がリストされています。
このファイルには、1,366の異なる広告主が含まれています。 以下はその広告主の一部です:
著者による表
旅行サイト、小売業者、テクノロジー企業、フィットネスセンター、自動車修理会社、医療保険会社、メディア企業(広告主を代表する企業)などがリストに表示されます。 様々な組織が含まれていますが、多くの場合、私自身、好み、習慣に関連するものとして関連付けることができます。
Facebookのダウンロードに含まれる他のファイルには、Facebookの検索履歴、検索のタイムスタンプ、およびブラウザのクッキーデータが含まれます。
Googleのエクスポート機能は「Takeout」という名前です。 Takeoutのウェブページには、データを要求できるさまざまなGoogleサービス(Gmail、YouTube、検索、Nestなど)がリストされています。 各サービスの利用可能なファイルと、各ファイルのエクスポート形式(json、HTML、またはcsv)も表示されます。 大抵の場合、Googleは個々のファイルのエクスポート形式を選択することはありません。
Googleは、各ファイルの目的の概要を提供することができますが、個々のフィールドの文書化はありません。
私のエクスポートには94のファイルが含まれていました。 Facebookと同様に、デバイス情報、アカウント属性、設定、ログイン/アクセスデータの履歴など、通常の管理ファイルも含まれています。
興味深いファイルの1つは「…/Ads/MyActivity.json」というものです。 これは、検索結果として私に表示された広告の履歴を含んでいます。
Ads/MyActivityファイルのいくつかのエントリは、例えば次のようなclickserveドメインを含むURLを持っています:

Googleの360広告ウェブサイトによると、これらはGoogleの広告主の広告で、私が行ったクリック活動の結果として私に提供されたものです。 ファイルには、広告が表示された原因となった私の行動に関する情報は提供されません。
ファイルの「タイトル」列は、「訪問済み」と「検索された」のサイトを区別しています。 「訪問済み」のレコードは、 ‘詳細’列に「Google Adsから」という情報を持っています(上記の例を参照)。 これにより、Googleが特定のサイトを訪問した私に広告を表示したと推測できます。
「検索された」レコードは、直接訪問したサイト(macys.com、yelp.comなど)を示します。 ‘詳細’列はこれらのサイトを、 ‘タイトル’列はそれらの個別のサイトで私が検索した内容を示しているようです。 例えば、


私が興味深いと思った別のファイルは、「…/My Activity/Discover/MyActivity.json」というものです。これは、Googleアプリの「Discover」機能(以前はGoogleフィード機能と呼ばれていました)を通じて私に提示されたトピックの提案の履歴です。Discoverのトピックは、ウェブとアプリのアクティビティに基づいて選択されます。ただし、Discoverのトピックをガイドとして使用するためにGoogleにアクティビティの使用許可を与えることを前提としています。
私はDiscoverにウェブとアプリのアクティビティの使用を許可していませんが、それにもかかわらず私に関連するトピックの提案がいくつか表示されました。以下は、数日間にわたって最も頻繁に提示されたトピックの編集されたサンプルです:
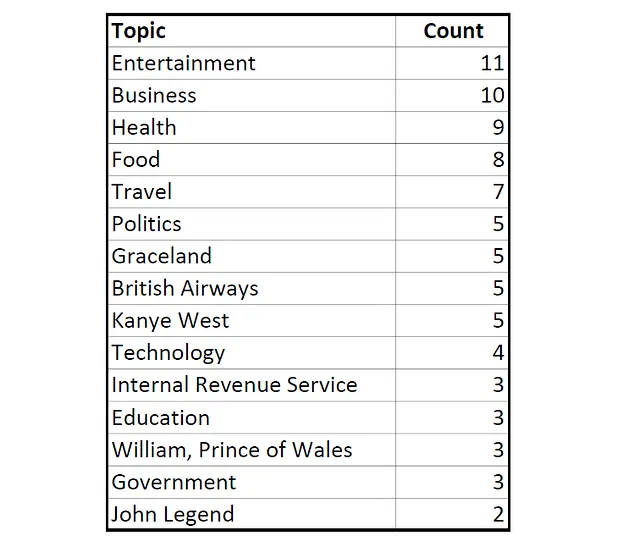
ここでは、テクノロジーや旅行などの繰り返しのテーマが見られます。さらに、Appleのファイルでも見ることになる新しいテーマである音楽があります!
Googleは、Googleの製品やサービス全体での活動履歴を追跡するいくつかのファイルをダウンロードに含めています。たとえば、私はトレーニングやドキュメンテーションリソースのためにdevelopers.google.comやcloud.google.comのサイトを訪れた履歴を受け取りました。このデータからは魅力的な洞察は得られませんでしたが、再訪したいトピックやさらに学習したいと思っていたトピックを思い出させてくれました。
抜粋に含まれる他の過去のデータには、Gmailアカウント内で実行された検索とアクション、画像の検索リクエスト、Googleマップアプリを通じて検索された場所、方向のリクエスト、および表示された地図、YouTube以外のウェブ上のビデオの検索、YouTubeの検索と視聴履歴、およびGoogleに保存されている連絡先(おそらくGmail内)が含まれています。
Facebookとは異なり、Googleは私のために構築した人口統計プロフィールに関する情報を提供していません。
なお、myactivity.google.comを訪れることで、Googleの製品やアプリ全体でのGoogleアクティビティデータを表示することができます:

このサイトからデータをエクスポートすることはできませんが、データを閲覧することはできます。これにより、Google Takeoutサイトを介してエクスポートしたいデータのタイプを把握することができます。
Microsoft
Microsoftは、Microsoft Privacy Dashboardを通じて一部のデータをエクスポートすることができます。ダッシュボードで利用できない個々のMicrosoftサービス(たとえば、MSDN、OneDrive、Microsoft 365、またはSkypeのデータ)については、Microsoftのプライバシーに関する声明ページの「個人データにアクセスして制御する方法」セクションのリンクを使用することができます。同じページでは、上記のいずれの方法でも入手できないデータを探している場合に提出できるウェブフォームへのリンクも指示されます。
私はPrivacy Dashboardを通じて利用可能なすべてのデータをエクスポートすることを選びました。これには、ブラウジング履歴、検索履歴、位置情報の活動、音楽、TVおよび映画の履歴、およびアプリとサービスの使用データが含まれます。また、Skypeのデータのエクスポートも要求しました。私のエクスポートには、4つのcsvファイル、6つのjsonファイル、および6つのjpegファイルが含まれていました。
エクスポートにはドキュメントが含まれておらず、Microsoftのサイトでも見つかりませんでした。ただし、ファイル内のフィールド名はかなり直感的です。
Microsoftのファイルからのいくつかの興味深い観察結果:
ファイル「…\Microsoft\SearchRequestsAndQuery.csv」には、過去18ヶ月間の私の検索データが含まれており、検索語句と、検索結果からクリックした場合はそのサイトも表示されています。このデータは、BingまたはWindows Searchを介して行った検索のみのようです。
データから判断すると、検索結果のリンクをクリックしたのは40%のみでした(870回の検索のうち347回のクリックがありました)。これから推測するに、リンクをクリックしなかった検索は、内容が不適切で、関連性のない結果を返していたか、検索結果のリンクプレビューを読んで必要な情報が得られた可能性があります。検索語句を頻繁に再入力する必要があるとは思い出せませんし、コーディング構文のリマインダーのために多くの検索を行っているため、リンクプレビューに必要な回答が表示されることがよくあります。いずれにしても、40%のクリック率には少し驚きました。もっと高いと予想していました。
Skypeのデータにはあまり興味深いものはありませんでした。それには、私と他のSkype会議参加者とのアプリ内メッセージスレッドの履歴が含まれていました。また、私の通話のいくつかの参加者の画像を含む.jpegファイルも含まれていました。
Apple Fitness
私はAppleの健康とフィットネスデータに他のデータとは別にアクセスする必要がありました。健康とフィットネスデータはiPhoneのHealthアプリからアクセスされます。Healthアプリ画面の右上隅にあるアイコンをクリックするだけで、プロフィール画面に移動し、画面の下部にある「すべての健康データをエクスポート」リンクをクリックします:
私の健康データのエクスポートには、約500個の.gpxファイルが含まれており、合計102メガバイトです。これらは過去数年間の記録されたワークアウトのルート情報を含んでいます。その他に、48個のファイルには、私がApple Watchで行ったセルフテストからの5.3メガバイトの心電図データが含まれています。
ファイル名が「…/Apple/apple_health_export/export.xml」のファイルには、本当に興味深いデータが含まれています。私にとっては、7年間の健康と運動のさまざまな測定に関する1,956,838のレコードが含まれ、合計770メガバイトです。測定されるアクティビティの種類のいくつかは以下の通りです:
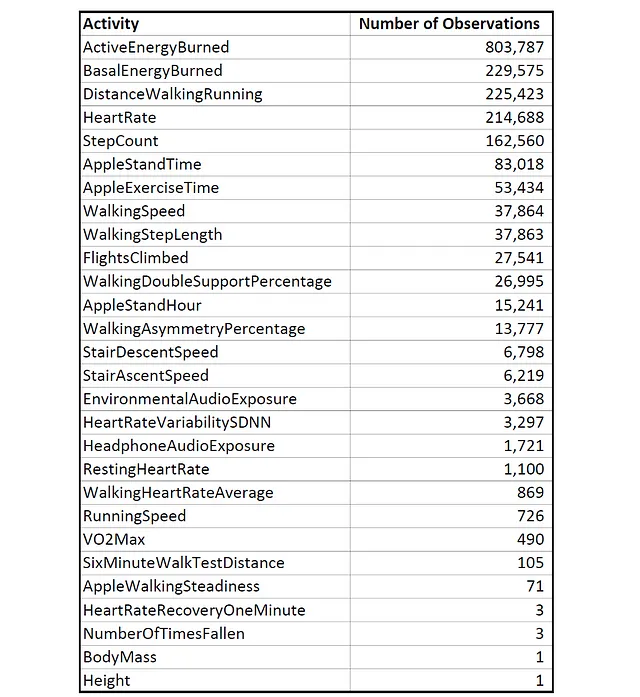
Appleがデータを記録する頻度はアクティビティの種類によって異なります。例えば、アクティブエネルギー消費量は毎時記録されますが、階段昇降速度は階段を上る時のみ記録されるため、これら2つのアクティビティの間の観測回数の大きな差が生じます。
各観測の記録されるデータには、観測が記録された日時、測定されたアクティビティの開始日時と終了日時、およびアクティビティを記録したデバイス(iPhoneまたはApple Watch)が含まれます。
優れたVoAGI記事「PythonとApple Healthで健康を分析する」で、Alejandro Rodríguez氏はexport.xmlファイルのxmlを解析し、Pandasのデータフレームを作成するために使用したコードを提供しています(Alejandroに感謝します!)。データの1年間のサブセットを選択し、日付とアクティビティの種類のレベルでグループ化し集計した後、いくつかの興味深いことがわかりました。
私の予想通り、私の平均活動レベルは旅行中の日と私のホームと呼ぶ都市(オースティンまたはシカゴ)にいる日とで異なりました。これを確認するために、先ほど言及した.gpx運動ルートファイルから緯度と経度データを使用しました。これにより、どのルートがホームの都市にあるか、どのルートが旅行中に発生したかを判断することができました。その後、その位置データを活動の概要データと結合しました。これは、さらにアクティビティの種類と位置(ホームの都市または旅行中)で要約されました。以下は結合されたパターンです:
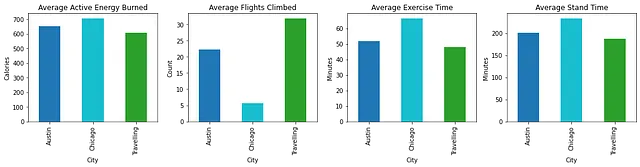
シカゴではエレベーターのあるアパートに滞在しているため、平均昇った階段の数の大幅な減少は驚きではありませんでした。しかし、オースティンと比較して、シカゴの活動レベルの増加は驚きでした。私の運動ルーティンは両方の場所で非常に似ていますが、シカゴではより多くの活動を行っています。これは、オースティンでの運動量を増やす必要があることを明らかにしています。
Apple Healthアプリの標準チャートでは見えない、上記のようなトレンドを見つけることは、健康データの素晴らしい活用です。
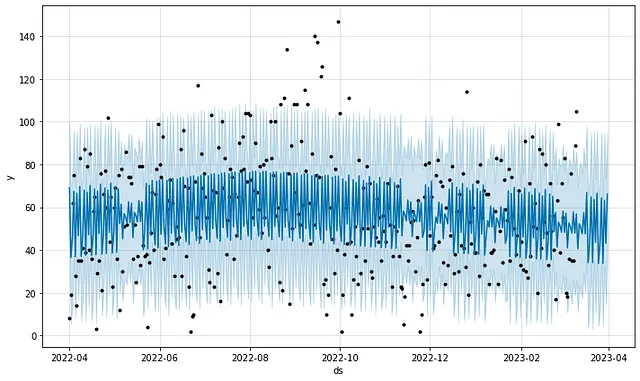
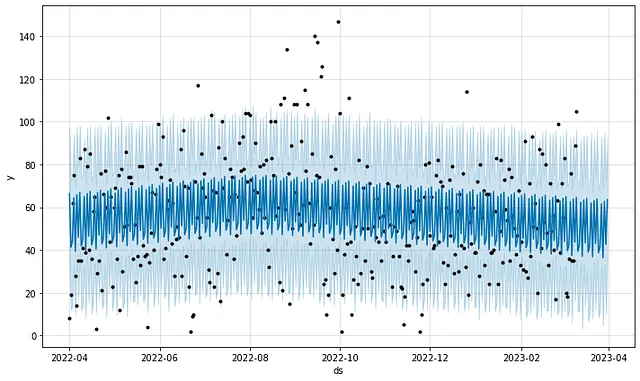
データは非常に完全で一般的にクリーンなので、モデリングにも適しています。以下は、FacebookのProphetモデルを使用して、1年間の期間に基づいた私の運動時間の時系列予測です:
こちらは同じ予測ですが、年間季節性を有効にし、私の位置(オースティン、シカゴ、または旅行中)に基づいて週次季節性を手動で追加したものです:
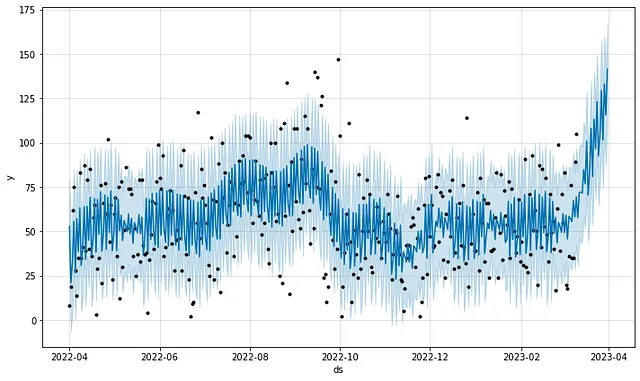
上記のデフォルトの週次季節性モデル(最初のプロット)は、カスタムの季節性項目が追加されたモデル(2番目のプロット)よりもトレーニングデータへの適合度が悪いです。しかし、デフォルトの季節性モデルは、運動時間の将来の値を予測する上でははるかに優れています(それでも十分ではありません)。言うまでもなく、ハイパーパラメータの調整により、これらの結果を改善することができます。

これは、健康データを使用して実験できるモデリングの一例です。非常に詳細な時系列データを使用してみたいですか?ワークアウトのルートファイルを見てください。それらは、記録されたワークアウトの各秒に緯度、経度、標高、速度のフィールドを持っています。
Apple — フィットネス/健康以外
Appleのメインウェブサイトから非フィットネス/健康データのダウンロードをリクエストします。私の場合、ほとんどのファイルは.csvと.jsonファイルで、いくつかの.xmlファイルもありました。また、Appleデバイス上の連絡先ごとに1つの.vcfファイルが数百個ダウンロードされました。合計で、.vcfファイルを除くと68メガのデータをダウンロードしました。
Appleは、各データファイルについて包括的なドキュメンテーションを提供していることが特徴的です。それぞれのフィールドの説明を含んでおり、ただし、定義によっては他よりも役立つものもあります。そのドキュメンテーションは、私が興味深いと思われるいくつかのデータファイルを解釈するのに役立ちました。
他のエクスポートと同様に、Appleのファイルには通常の管理データが含まれており、例えばアプリの設定、ログイン情報、デバイス情報などがあります。それらのファイルには特筆すべきものは見つかりませんでした。
Apple Musicに関連するいくつかのファイルがあります。タイトルが次のようなファイル:
- 「…/Media_Services/Apple Music — Play History Daily Tracks.csv」;
- 「…/Media_Services/Apple Music — Recently Played Tracks.csv」; および、
- 「…/Media_Services/Apple Music Play Activity.csv」
には、次のような情報が含まれています:
- 曲が再生された日時;
- 再生時間(ミリ秒);
- 再生がどのように終了したか(例:トラックの終わりまで再生されたか、曲をスキップしたか);
- 曲が再生された回数;
- 曲がスキップされた回数;
- 曲のタイトル;
- アルバムのタイトル(ある場合);
- 曲のジャンル;および、
- 曲が再生された場所 — ライブラリ、プレイリスト、またはAppleのラジオチャンネルのいずれか。
私のファイルには、目的によって13,900から20,700のレコードが含まれていました。データは約7年間の曲の再生をカバーしています。
Appleは、曲の再生がどのように終了するかに関するさまざまなデータを収集しており、おそらく私に他の曲を推薦するための目的で収集していると考えられます。曲の再生終了の理由には、次のようなものがあります:
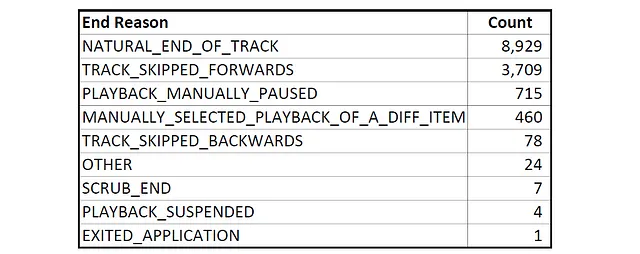
以下の分析では、’NATURAL_END_OF_TRACK’、’TRACK_SKIPPED_FORWARDS’、および’MANUALLY_SELECTED_PLAYBACK_OF_A_DIFF_ITEM’の再生終了理由に焦点を当てました。
私は好きな曲を繰り返し再生することがあります。私が持っていた質問の一つは、「お気に入りの曲を繰り返し熱中して聴くのか?」ということでした。それについての答えは、Appleのデータを使用しています:
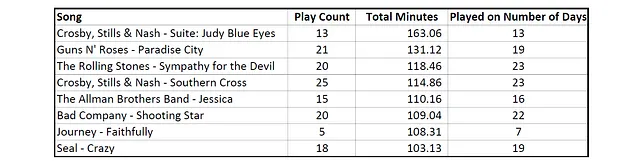
上記の表は、私がいくつかのお気に入りの曲をプレイした回数(「再生回数」)と曲をプレイした日数(「再生日数」)をまとめたものです。一日に一度だけ曲をプレイする傾向があるようです。また、再生回数が一部の曲の日数よりも少ないため、最近あまりにも多く聞いた曲やその時の気分に合わない曲はスキップしているようです。つまり、ここでは執念深くプレイしているわけではありません!
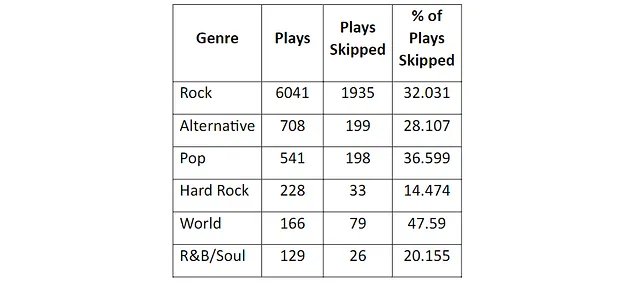
また、私は曜日や時間帯、さらには年の月によって特定のタイプの曲を好むかどうかも気になりました。直感的には、好みがあると思います。Appleのデータでは、異なる時期にプレイしたジャンルを簡単に可視化することができました。たとえば、年の各月において最も頻繁にプレイしたジャンルは以下の通りです:
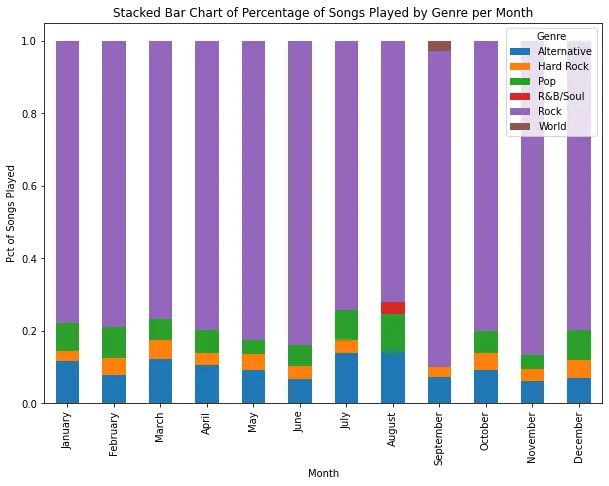
明らかにロックの曲を好んでおり、たまにバラエティとしてオルタナティブやポップミュージックも追加しています。7月と8月はバラエティを好む月のようです。
とは言っても、私がプレイするロックの量には驚きました。確かにロックは大好きですが、音楽の好みは広いと思っています。
そのため、Appleのデータに割り当てられたジャンルの正確さに疑問を抱きました。まず、私のファイルの22,313曲の中で10,083曲の再生にはジャンルが割り当てられていませんでした。また、割り当てられたジャンルには重複が多いようです。たとえば、「R&B/Soul」「Soul and R&B」「Soul」「R&B / Soul」などが私のデータの異なる曲に割り当てられたジャンルです。もしすべての曲のジャンルを一貫したジャンルの命名スキームに変更した場合、上記のチャートの合計は確実に異なるものになるでしょう。
ジャンルを更新するための時間をかける代わりに、私はチャートの傾向が本当に私のプレイパターンを表しているかどうかを確認するために別のテストを行うことにしました。Appleのデータには曲の再生終了理由も含まれているため、ロックの曲を他のジャンルよりも頻繁にスキップする傾向があるかどうかを調べました。これは、ロックの曲があまりにも多くプレイされている場合に他のジャンルをプレイしようとしていることを示すものです。
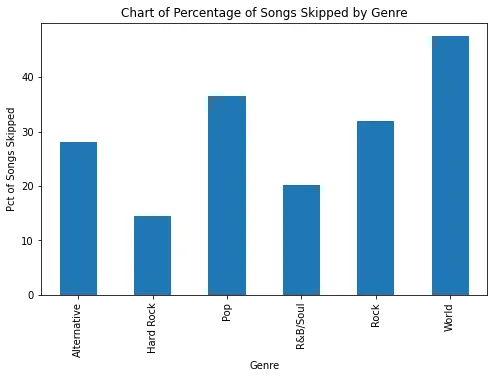
結果として、私は頻繁に聞く他のジャンルと比べてロックの曲をスキップすることはほとんどありません。直面しなければならないのは、私は忠実なロックファンだということです。
もう一つの興味深いファイルは「…/Media_Services/Stores Activity/Other Activity/App Store Click Activity.csv」と呼ばれています。ここでは分析しませんが、小売業者がウェブサイト上のアクティビティを追跡するために必要なデータの種類を知りたい方におすすめです。私の場合、このファイルには4,900以上のレコードが含まれており、アプリストアでの活動とApple Musicでの活動の詳細な履歴が含まれています。私が行ったアクションの種類、日時、A/Bテストフラグ、検索用語、そして私に表示されたデータ(「impressed」という用語が使用されています)などがファイルに含まれています。
分析においてもう一つの興味深いファイルは「\\Media_Services\\Stores Activity\\Other Activity\\Apple Music Click Activity V3.csv」と呼ばれています。これには、Apple Musicを使用していた場所の都市名と経度/緯度が含まれています。私の場合、このファイルには10,000件のレコードがありました。
Verizon
80日以上の長い待ち時間の後、Verizonからデータのダウンロードができると通知がありました。それには合計で1.4メガバイトの17個のcsvファイルが含まれていました。ほとんどのファイルはアカウントの管理情報(セルラインの説明、デバイス情報、請求履歴、注文履歴など)、Verizonから私に送られた通知の履歴、最近のテキストメッセージの履歴(ただし内容は含まれていません)をカバーしています。通話履歴とデータ使用履歴のファイルも提供されましたが、「セキュリティのためにマスクされた」データ以外は空でした。
Verizonは2つのドキュメンテーションファイルを提供しました。1つ目は、ダウンロードに含まれる可能性のある34のファイルの名前と一般的な説明が含まれています。含まれるファイルは使用しているVerizonのサービスによって異なります。2つ目のドキュメンテーションファイルには、ファイルに表示される可能性のある3,091のデータフィールドの説明が含まれています。データフィールドの説明は役立ちますが、一部の詳細が欠けています。たとえば、多くのフィールドはさまざまな目的のためのコードを含んでいると説明されていますが、コード自体やその意味については説明されていません。
非常に興味深いファイルの1つは、「… / Verizon / General Inferences.csv」という名前です。これには私と私の家族の他の人々に関する素晴らしい量の人口統計情報が含まれています。以下はVerizonのドキュメントがファイルを説明している方法です:
「一般的な推論ファイルは、プラットフォーム全体で関連性が高く、関連性のあるコンテンツを提供するための一般的な仮定と推論情報を提供します。これには、属性、嗜好、または意見などの情報が含まれる場合があります。」
人口統計的特徴の性質に基づいて、ほとんどはVerizonが私からではなく、外部のデータ集約業者から取得したものだと推測します。人口統計的特徴の数と範囲は、私がVerizonに直接提供した情報をはるかに超えています。
実際には、Verizonのドキュメントでは、別のファイル「一般」情報ファイルについても説明しています(私のダウンロードには含まれていません)。ドキュメントによると、「一般」ファイルには外部情報源からのデータが含まれています。私の推測では、「一般的な推論」ファイルの情報もそれらの外部情報源から来ていると思われます。 「一般的な推論」ファイルの一部の金融データは、Verizonが顧客に提供するよう要求しているクレジットレポートから来ている可能性があります。
私の一般的な推論データには合計332の人口統計的特徴が含まれています。以下はいくつかの驚くべき特徴を含む要約リストです:

Verizonは、一般的な推論の特徴を私に対して販売や顧客維持に使用しているようです。上記のリストでわかるように、配偶者や子供に関する特徴も含まれています。332の特徴の完全なリストはこちらでご覧いただけます。
私が特に珍しいと感じた特徴のいくつかには、次のようなものがあります:

Verizonがそれらのデータ要素を本当に必要としており、それらをどのように使用しているのか、という疑問がわきます。
Amazon
Amazonは、4.93メガバイトのデータを含む214のファイルを提供しました。いくつかのファイルには次のような内容が含まれています:
- アカウントの設定;
- 注文履歴;
- 配送と返品の履歴;
- 視聴および聴取の履歴(Amazon Prime VideoおよびAmazon Music);
- Kindleの購入および読書のアクティビティ、
- および検索履歴(検索語句を含む)。
Alexaの顧客またはRingの顧客であれば、それらのサービスでの活動に関するデータも受け取ったと思われます。
6つの.txtファイルには、ダウンロードされたデータファイルのいくつかの高レベルの説明が含まれています。いくつかの.pdfファイルには、ダウンロードされたファイルのフィールドのドキュメントが含まれています(たとえば、「Digital.PrimeVideo.Viewinghistory.Description.pdf」というファイルなど)。
Amazonからの最も興味深いファイルは、私に関連付けられたマーケティングの対象者に関するものです。これはAmazon自体が割り当てた21の対象者のサンプルです:
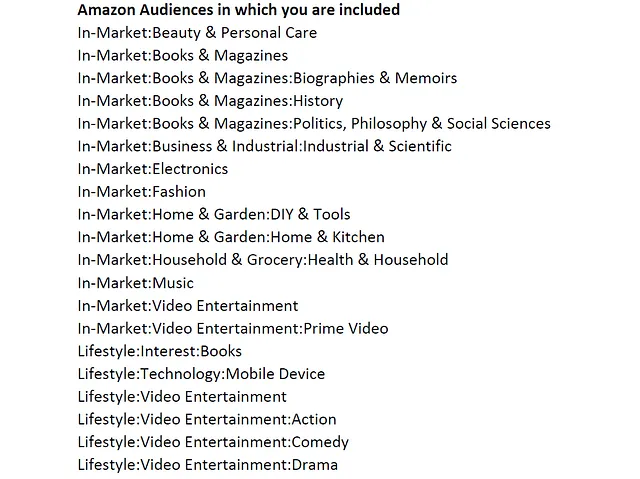
Amazonの対象者の割り当ては、私自身または他の人のために購入または検索した製品を考慮すると、ほとんど正確です。
「… / Amazon / Advertising.1 / Advertising.AmazonAudiences.csv」というファイルには、Amazonが自身で割り当てた対象者が含まれています。ここには50の広告主が含まれています。以下はサンプルです:

私はリスト内の広告主(たとえば、デルタ、インチュイト、ジップカー)と取引をしたり、製品を所有しているため、なぜ彼らの対象者リストに入っているのか理解しています。リスト内の他の企業(たとえば、AT&T、レッドブル、カナダロイヤル銀行)とは関係がないため、彼らの対象者リストに入っている理由はわかりません。
Amazonによると、ファイル
“…/Amazon/Advertising.1/Advertising.3PAudiences.csv”
には、
“サードパーティによってあなたが含まれている対象者”
のリストが含まれています。
その正確性は低いです。合計33の対象者がリストされており、そのうち28は自動車所有に関連しています。残りの4つは性別、教育レベル、婚姻状況、扶養家族に関連しています。自動車に関連する対象者のサンプル:

ファイル内の性別/教育レベル/婚姻状況の割り当ては正確ですが、自動車関連の割り当てはほんの一部しか正確ではありません。ほとんどの割り当ては正確ではありません。そして、私は自動車にあまり興味がないため、33のプロファイルのうち28が自動車に関連しているのはちょっと多すぎます。幸いなことに、Amazonは私に製品やビデオのおすすめを表示する際にこのデータを無視しているようです。
まとめ
この記事では、ビジネスを行っている企業から得られるさまざまなデータを紹介しました。これらのデータにより、企業が私についてどのような考えを持っているかを知ることができ、同時に自分自身についても驚くべきことを学ぶことができます!
いくつかの企業は私の技術や旅行に対する興味を正しく特定していますが、ある企業は私を熱心な自動車愛好家と見誤っています。目を見開き、少し不安に思った瞬間、別の企業が私の家族に関する包括的な人口統計情報を持っていることに気付きました。
私は、私が2つの場所のワークアウトを同等に考えていたにもかかわらず、自宅のどちらかでワークアウトの強度を増やす必要があると気付きました。FacebookやGoogleなどの一部の企業は私のプロフィールに強い見解を持っていないことがわかりました。しかし、Verizonが私の人口統計情報を驚くほど正確に把握していることもわかりました。
さまざまな企業から提供されるデータは、実験のための豊かな素材です。これらのデータは、深い分析、モデリング、可視化活動に適しています。たとえば、多くの観測値には地理座標とタイムスタンプが利用でき、移動の可視化やモデリングが可能です。
あなた自身の興味深い洞察を見つけるために、個人データをダウンロードしてみてください。私がここで取り上げていない他の企業との作業で注目すべき経験がある場合は、ぜひお知らせください。
これはあなたのデータです — さあ、やってみましょう!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- レコメンドシステムの評価指標 — 概要
- 「2023年に必要な機械学習エンジニアの10の必須スキル」
- 「DeepMindによるこのAI研究は、シンプルな合成データを使用して、大規模な言語モデル(LLM)におけるおべっか使用を減らすことを目指しています」
- 「ConDistFLとの出会い:CTデータセットにおける臓器と疾患のセグメンテーションのための革新的なフェデレーテッドラーニング手法」
- 「PUGに会ってください:メタAIによるアンリアルエンジンを使用したフォトリアルで意味的に制御可能なデータセットを用いた堅牢なモデル評価に関する新しいAI研究」
- USCとMicrosoftの研究者は、UniversalNERを提案します:ターゲット指向の蒸留で訓練され、13,000以上のエンティティタイプを認識し、43のデータセット上でChatGPTのNER精度を9%F1上回る新しいAIモデルです
- インフォグラフィックスでデータ可視化をどのように使用するか?
