「Hugging Faceを使用してAmazon SageMakerでのメール分類により、クライアントの成功管理を加速する」
Accelerating client success management through email classification on Amazon SageMaker using Hugging Face.
これは、ヨーロッパでリーディングなFinTechであり、デジタルウェルスマネジメントと取引手数料のフラットレートを提供するScalable Capitalからのゲスト投稿です。
急成長しているScalable Capitalの目標は、革新的で堅牢かつ信頼性のあるインフラを構築するだけでなく、特にクライアントサービスにおいて最高の体験を提供することです。
Scalableは、毎日何百ものクライアントからのメール問い合わせを受けます。最新の自然言語処理(NLP)モデルを導入することで、応答プロセスが効率的に形成され、クライアントの待ち時間が大幅に短縮されました。機械学習(ML)モデルは、新しい顧客のリクエストが到着するとすぐに分類し、事前定義されたキューにリダイレクトします。これにより、専任のクライアントサクセスエージェントは、スキルに応じてメールの内容に焦点を当て、適切な回答を提供することができます。
この投稿では、Amazon SageMakerで展開されたHugging Faceトランスフォーマーを使用することの技術的な利点、スケーラビリティとコスト効率の向上などを紹介します。
- 「Amazon SageMakerは、個々のユーザーのためにAmazon SageMaker Studioのセットアップを簡素化します」
- 「ロボットに対するより柔らかいアプローチ」
- 「3Dプリントされた『生物性材料』が汚染された水を浄化することができる」
問題の説明
Scalable Capitalは、ヨーロッパで最も成長しているFinTechの1つです。同社は投資を民主化することを目指し、クライアントに金融市場への簡単なアクセスを提供しています。Scalableのクライアントは、同社の取引プラットフォームを通じて市場に積極的に参加するか、スケーラブルウェルスマネジメントを使用してインテリジェントかつ自動化された投資を行うことができます。2021年、Scalable Capitalのクライアントベースは数万人から数十万人に10倍増加しました。
製品とクライアントサービスのトップクラス(かつ一貫した)ユーザーエクスペリエンスを提供するために、当社はスケーラブルなソリューションの効率を向上させる自動化ソリューションを探していました。Scalable Capitalのデータサイエンスおよびクライアントサービスチームは、電子メールの問い合わせに対応する際の最大のボトルネックが、日々の基準リクエストの読み取りとラベル付けのステップであることを特定しました。メールが適切なキューにルーティングされた後、それぞれの専門家が迅速に対応し、問題を解決します。
この分類プロセスを効率化するために、Scalableのデータサイエンスチームは、Hugging Faceが公開した事前学習済みのdistilbert-base-german-casedモデルに基づく最先端のトランスフォーマーアーキテクチャを使用して、マルチタスクNLPモデルを構築し、展開しました。distilbert-base-german-casedは、元のBERTベースモデルよりも小さく、高速な汎用言語表現モデルを事前学習するための知識蒸留法を使用しています。蒸留バージョンは、元のバージョンと比較可能なパフォーマンスを達成しながら、より小さく高速です。MLライフサイクルプロセスを容易にするために、モデルのビルド、展開、提供、モニタリングにSageMakerを採用することにしました。次のセクションでは、プロジェクトのアーキテクチャ設計を紹介します。
ソリューションの概要
Scalable CapitalのMLインフラストラクチャは、2つのAWSアカウントで構成されています。1つは開発ステージの環境、もう1つは本番ステージのためです。
以下の図は、私たちのメール分類器プロジェクトのワークフローを示していますが、他のデータサイエンスプロジェクトにも一般化できます。
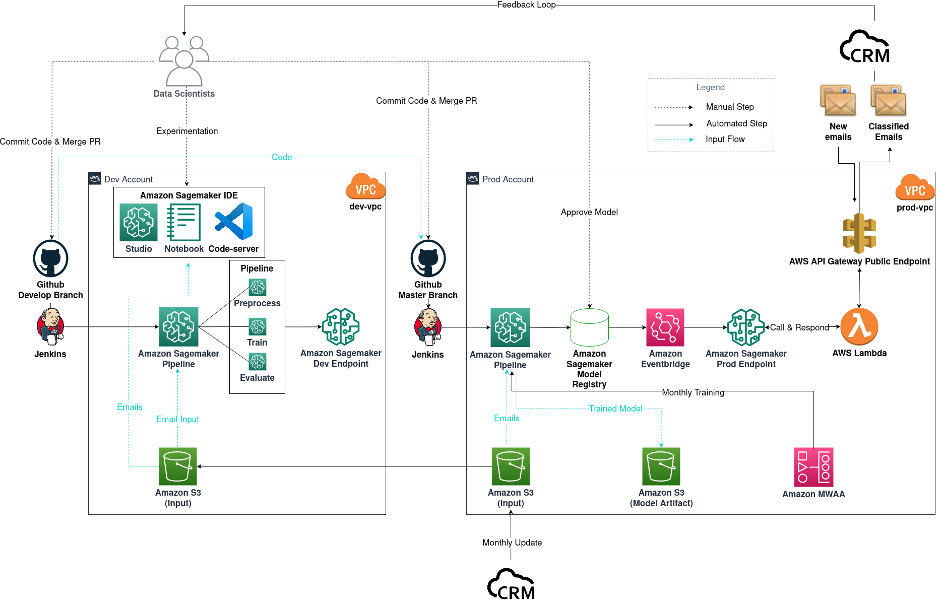
メール分類プロジェクトのワークフロー図
ワークフローは次のコンポーネントで構成されています:
- モデルの実験 – データサイエンティストは、Amazon SageMaker Studioを使用して、データサイエンスのライフサイクルの最初のステップである探索的データ分析(EDA)、データのクリーニングと準備、およびプロトタイプモデルの構築を行います。探索フェーズが完了したら、VSCodeをSageMakerノートブックのホストとして使用して、コードベースをモジュール化および本番化します。さまざまなタイプのモデルとモデル構成を試すため、同時に実験を追跡するためにSageMaker TrainingとSageMaker Experimentsを使用します。
- モデルのビルド – 本番用途のモデルを決定した後、この場合はマルチタスクdistilbert-base-german-casedモデル(Hugging Faceの事前学習済みモデルからファインチューニング)を選択した後、コードをGithubの開発ブランチにコミットしてプッシュします。Githubのマージイベントは、Jenkins CIパイプラインをトリガーし、そのパイプラインはテストデータを使用してSageMakerパイプラインジョブを開始します。これは、コードが期待通りに実行されていることを確認するためのテストです。テスト用のエンドポイントが展開されます。
- モデルの展開 – すべてが期待通りに動作していることを確認した後、データサイエンティストは開発ブランチをプライマリブランチにマージします。このマージイベントは、本番データを使用してSageMakerパイプラインジョブをトリガーします。その後、モデルアーティファクトが生成され、出力Amazon Simple Storage Service(Amazon S3)バケットに保存され、新しいモデルバージョンがSageMakerモデルレジストリに記録されます。データサイエンティストは、新しいモデルのパフォーマンスを調査し、期待に沿っている場合に承認します。モデル承認イベントはAmazon EventBridgeによってキャプチャされ、それによってモデルが本番環境のSageMakerエンドポイントに展開されます。
- MLOps – SageMakerエンドポイントはVPC外のサービスから到達できないため、AWS Lambda関数とAmazon API Gateway公開エンドポイントがCRMとの通信に必要です。CRMの受信トレイに新しいメールが到着するたびに、CRMがAPI Gateway公開エンドポイントを呼び出し、それがLambda関数をトリガーしてプライベートなSageMakerエンドポイントを呼び出します。関数は、分類結果をCRMにAPI Gateway公開エンドポイントを介して中継します。展開されたモデルのパフォーマンスを監視するために、CRMとデータサイエンティストの間にフィードバックループを実装し、モデルからの予測メトリクスを追跡します。月次で、CRMは実験とモデルトレーニングに使用する履歴データを更新します。月次の再学習には、Amazon Managed Workflows for Apache Airflow(Amazon MWAA)をスケジューラとして使用します。
以下のセクションでは、データの準備、モデルの実験、およびモデルの展開のステップを詳細に説明します。
データの準備
Scalable Capitalは、メールデータの管理と保存にCRMツールを使用しています。関連するメールの内容には、件名、本文、および証券会社が含まれます。各メールには3つのラベルが割り当てられます: メールの所属する業務部門、適切なキュー、およびメールの具体的なトピックです。
NLPモデルのトレーニングを開始する前に、入力データがクリーンであり、期待どおりのラベルが割り当てられていることを確認します。
Scalableのクライアントからクリーンな問い合わせ内容を取得するために、メールの署名、インプレッサム、前のメールチェーンのメッセージの引用、CSSのシンボルなど、生のメールデータと余分なテキストとシンボルを削除します。そうしないと、将来のトレーニング済みモデルのパフォーマンスが低下する可能性があります。
メールのラベルは、Scalableのクライアントサービスチームが新しいラベルを追加したり、既存のラベルを改善または削除したりすることで、時間とともに進化します。トレーニングデータのラベルと予測の期待される分類が最新であることを確認するために、データサイエンスチームはクライアントサービスチームと緊密に連携してラベルの正確性を確保します。
モデルの実験
私たちは、Hugging Faceが公開した既に利用可能なpre-trained distilbert-base-german-casedモデルから実験を開始します。pre-trainedモデルは汎用の言語表現モデルであるため、ニューラルネットワークに適切なヘッドを付けることで、特定の下流タスク(分類や質問応答など)を実行するためのアーキテクチャを適応させることができます。私たちのユースケースでは、関心のある下流タスクはシーケンス分類です。既存のアーキテクチャを変更せずに、私たちは必要なカテゴリごとに3つの別々のpre-trainedモデルを微調整することにしました。SageMaker Hugging Face Deep Learning Containers(DLC)を使用すると、Hugging FaceコンテナとSageMaker Experiments APIを使用してNLP実験の開始と管理が簡単になります。
次のコードスニペットは、train.pyです:
config = AutoConfig.from_pretrained("distilbert-base-german-cased") # オリジナルの設定をロードします
config.num_labels = num_labels # ラベルの数を特定の数に適応します(デフォルトは2です)
# pre-trainedモデルをインスタンス化します
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-german-cased", config=config)
trainer = Trainer(
model=model, # トレーニングするTransformersモデル
args=training_args, # 上記で定義したトレーニング引数
train_dataset=train_dataset, # トレーニングデータセット
eval_dataset=val_dataset # 評価データセット
)
trainer.train()次のコードはHugging Faceの推定器です:
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.26.0',
pytorch_version='1.13.1',
py_version='py39',
hyperparameters = hyperparameters
)メールデータセットが不均衡な性質を持つため、微調整済みモデルの検証にはF1スコアを使用しますが、精度、適合率、再現率などの他のメトリックを計算するためにも使用します。SageMaker Experiments APIがトレーニングジョブのメトリックを登録するためには、まずメトリックをトレーニングジョブのローカルコンソールにログ出力し、それをAmazon CloudWatchが受け取る必要があります。その後、CloudWatchログをキャプチャするための正しい正規表現形式を定義します。メトリックの定義には、メトリックの名前とトレーニングジョブからメトリックを抽出するための正規表現の検証が含まれます:
metric_definitions = [
{"Name": "train:loss", "Regex": "'loss': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "learning_rate", "Regex": "'learning_rate': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:loss", "Regex": "'eval_loss': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "train:accuracy", "Regex": "'train_accuracy': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:accuracy", "Regex": "'eval_accuracy': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "train:precision", "Regex": "'train_precision': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:precision", "Regex": "'eval_precision': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "train:recall", "Regex": "'train_recall': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:recall", "Regex": "'eval_recall': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "train:f1", "Regex": "'train_f1': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:f1", "Regex": "'eval_f1': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:runtime", "Regex": "'eval_runtime': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:samples_per_second", "Regex": "'eval_samples_per_second': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "epoch", "Regex": "'epoch': ([0-9]+(.|e\-)[0-9]+),?"},
]分類器モデルのトレーニングイテレーションの一環として、混同行列と分類レポートを使用して結果を評価します。以下の図は業務予測のための混同行列を示しています。
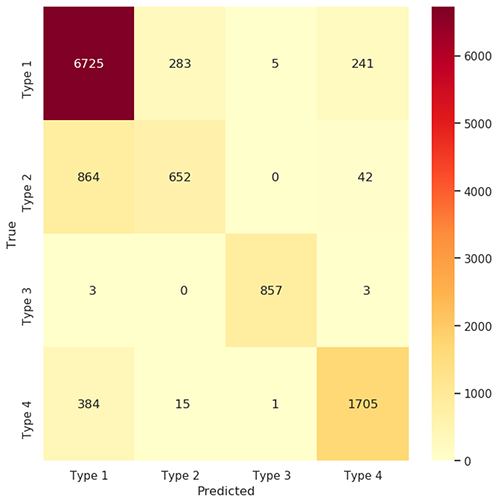
混同行列
以下のスクリーンショットは、業務予測の分類レポートの例を示しています。
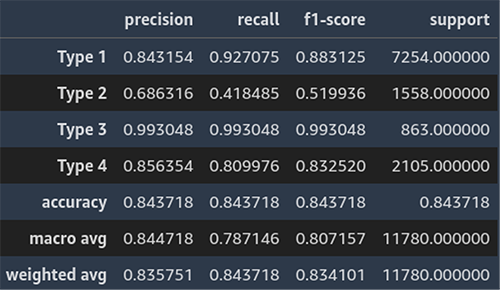
分類レポート
次の実験のイテレーションでは、マルチタスク学習を活用してモデルを改善します。マルチタスク学習は、モデルが複数のタスクを同時に解決するように学習する形式であり、タスク間の共有情報が学習効率を向上させることができます。元のdistilbertアーキテクチャに2つ以上の分類ヘッドをアタッチすることで、マルチタスクファインチューニングを実行し、クライアントサービスチームに合理的なメトリクスを提供できます。
モデルの展開
私たちのユースケースでは、メール分類器はエンドポイントに展開され、CRMパイプラインが未分類のメールのバッチを送信し、予測結果を受け取ることができます。Hugging Faceモデルの推論に加えて、入力データのクリーニングやマルチタスク予測などの他のロジックもあるため、SageMakerの標準に準拠したカスタム推論スクリプトを作成する必要があります。
以下はinference.pyのコードスニペットです:
def model_fn(model_dir):
model = load_from_artifact(model_dir)
return model
def transform_fn(model, input_data, content_type, accept):
if content_type == "application/json":
data = json.loads(input_data)
data = pd.DataFrame(data)
else:
raise ValueError(f"Unsupported content type: {content_type}")
data = preprocess(data)
# 推論
with torch.no_grad():
predictions = model(data)
predictions = postprocess(predictions)
if content_type == 'application/json':
return json.dumps(predictions.to_dict(orient="records"))
else:
raise NotImplementedErrorすべてが準備できたら、SageMaker Pipelinesを使用してトレーニングパイプラインを管理し、インフラストラクチャにアタッチしてMLOpsのセットアップを完了します。
展開されたモデルのパフォーマンスを監視するために、クローズ時にCRMから分類されたメールのステータスを提供するフィードバックループを構築します。この情報に基づいて、展開されたモデルを改善するための調整を行います。
結論
この記事では、SageMakerがScalableのデータサイエンスチームがデータサイエンスプロジェクトのライフサイクルを効率的に管理するのを支援する方法を共有しました。具体的には、メール分類器プロジェクトです。ライフサイクルは、SageMaker Studioによるデータ分析と探索の初期フェーズから始まり、SageMakerトレーニング、推論、およびHugging Face DLCを使用したモデルの実験と展開に移り、他のAWSサービスと統合されたSageMaker Pipelinesによるトレーニングパイプラインで完了します。このインフラストラクチャのおかげで、新しいモデルをより効率的に反復し展開することができ、Scalable内およびクライアントのエクスペリエンスを改善することができます。
Hugging FaceとSageMakerについて詳しくは、以下のリソースを参照してください:
- Amazon SageMakerでHugging Faceを使用する
- AWS Deep Learning Containersとは何ですか?
- SageMaker Python SDKのバージョン2.xを使用する: フレームワーク: Hugging Face
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






