マルチディフュージョンによる画像生成のための統一されたAIフレームワーク、事前学習されたテキストから画像へのディフュージョンモデルを使用して、多目的かつ制御可能な画像生成を実現します
A unified AI framework for image generation using multi-diffusion, achieving versatile and controllable image generation through a diffusion model from pre-trained text to image.


拡散モデルは現在の最先端のテキストから画像を生成するモデルとして位置付けられていますが、これらは以前に聞いたことのないスキルを持ち、高品質で多様な画像をテキストのプロンプトから生成する能力を持つ「破壊的技術」として浮上しています。生成された素材に対してユーザーが直感的な制御を与える能力は、テキストから画像へのモデルにとって依然として課題であり、この進歩はデジタルコンテンツの作成方法を変革する可能性を秘めています。
現在、拡散モデルを制御するための2つの技術があります:(i) ゼロからモデルを訓練するか、(ii) 手元の拡散モデルを微調整するかです。微調整の場合でも、これらの戦略は頻繁に大量の計算と長期間の開発期間を必要とすることがあります。既に訓練されたモデルを再利用し、いくつかの制御された生成能力を追加する(ii)という手法もあります。一部の手法は以前から特定のタスクに焦点を当て、特化した方法論を作成してきました。本研究では、制御された画像生成への参照拡散モデルの適応性を大幅に向上させる新しい統合フレームワークであるMultiDiffusionを生成します。

MultiDiffusionの基本的な目標は、複数の参照拡散生成プロセスを共通の特性や制約で結合した新しい生成プロセスを設計することです。生成された画像の異なる領域は、参照拡散モデルによってより具体的に各領域のノイズ除去サンプリングステップを予測します。MultiDiffusionは、これらの個別のフェーズを調整するために、最小二乗法の最適解を使用してグローバルなノイズ除去サンプリングステップを実行します。たとえば、正方形の画像でトレーニングされた参照拡散モデルを使用して、任意のアスペクト比を持つ画像を作成するという課題を考えてみましょう(下図2)。
- 「機械学習モデルのバリデーション方法」
- メタの戦略的な優れた点:Llama 2は彼らの新しいソーシャルグラフかもしれません
- 「TableGPTという統合された微調整フレームワークにより、LLMが外部の機能コマンドを使用してテーブルを理解し、操作できるようになります」
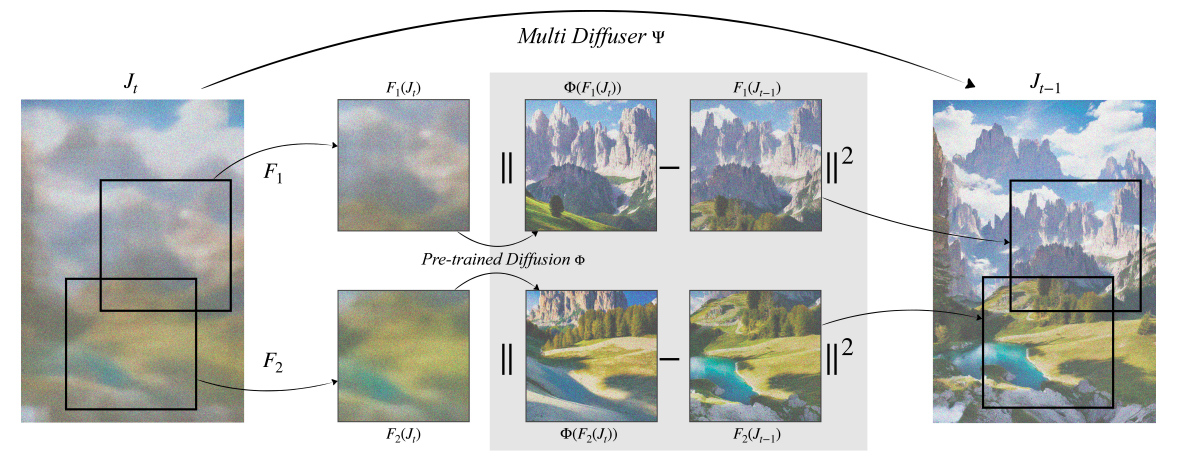
MultiDiffusionは、参照モデルが各ノイズ除去プロセスの各フェーズで提供する正方形のクロップからのノイズ除去方向を結合します。それらを可能な限り追いかけようとしますが、隣接するクロップが共通のピクセルを共有することで妨げられます。各クロップは異なる方向にノイズ除去を引っ張るかもしれませんが、彼らのフレームワークは単一のノイズ除去フェーズに結果を収束させ、高品質でシームレスな画像を生成します。各クロップが参照モデルの真のサンプルを表すようにしましょう。
MultiDiffusionを使用することで、事前にトレーニングされた参照テキストから画像へのモデルを、特定の解像度やアスペクト比で画像を生成したり、読み取りにくい領域ベースのテキストプロンプトから画像を生成したりするなど、さまざまなタスクに適用することができます(図1参照)。重要なのは、このアーキテクチャが共有の開発プロセスを利用して両方のタスクを同時に解決することができる点です。関連するベースラインと比較して、これらの手法はこれらのジョブに特化して訓練されたアプローチと比較しても最先端の制御された生成品質を達成できることを彼らは発見しました。また、彼らの手法は計算負荷を増やすことなく効果的に動作します。完全なコードベースは近日中に彼らのGithubページで公開される予定です。また、プロジェクトページでさらにデモをご覧いただけます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ReLoRa GPU上で大規模な言語モデルを事前学習する
- SimPer:周期的なターゲットの簡単な自己教示学習
- LMSYS ORG プレゼント チャットボット・アリーナ:匿名でランダムなバトルを行うクラウドソーシング型 LLM ベンチマーク・プラットフォーム
- 「Mojo」という新しいプログラミング言語は、Pythonの使いやすさとCのパフォーマンスを組み合わせ、AIハードウェアのプログラム可能性とAIモデルの拡張性を他のどの言語よりも優れたものにします
- MPT-7Bをご紹介します MosaicMLによってキュレーションされた1Tトークンのテキストとコードでトレーニングされた新しいオープンソースの大規模言語モデルです
- AIとディープラーニングに最適なGPU
- ラミニAIに会ってください:開発者が簡単にChatGPTレベルの言語モデルをトレーニングすることができる、革命的なLLMエンジン






