テルアビブとコペンハーゲン大学からの新しいAI研究は、識別信号を使用して、テキストから画像への拡散モデルを迅速に微調整するための「プラグアンドプレイ」アプローチを紹介しています
A new AI research from Tel Aviv and Copenhagen University introduces a plug-and-play approach using discriminative signals to quickly fine-tune diffusion models from text to images.


テキストから画像への拡散モデルは、入力テキストの説明に基づいて多様で高品質な画像を生成することで印象的な成功を収めています。しかし、入力テキストが語彙的に曖昧であるか、複雑な詳細を含む場合は、課題に直面することがあります。これにより、服の「アイロン」などの意図した画像コンテンツが「元素的な」金属として誤って表現される場合があります。
これらの制約に対処するために、既存の手法では、事前に訓練された分類器を使用してノイズ除去プロセスをガイドすることがあります。1つのアプローチは、拡散モデルのスコア推定値を事前に訓練された分類器の対数確率の勾配とブレンドすることです。簡単に言えば、このアプローチでは、拡散モデルと事前に訓練された分類器の両方の情報を使用して、望ましい結果に一致し、画像が分類器の判断に合致するように生成します。
ただし、この方法には、実際のノイズのあるデータで動作することができる分類器が必要です。
- 「UCIとハーバードの研究者が、ユーザーに機械学習モデルを説明するTalkToModelを紹介する」
- マイクロソフトリサーチがBatteryMLを紹介:バッテリー劣化における機械学習のためのオープンソースツール
- 「ポーズマッピング技術によって、脳性麻痺の患者を遠隔で評価することができます」
他の戦略では、特定のデータセットを使用してクラスラベルに拡散プロセスを条件付けることがあります。効果的ではありますが、このアプローチは、ウェブ上の画像とテキストのペアの広範なコレクションで訓練されたモデルの完全な表現能力からは程遠いです。
別のアプローチとしては、特定の概念やラベルに関連する少量の画像を使用して拡散モデルまたはその入力トークンの一部を微調整することがあります。ただし、このアプローチには、新しい概念のための遅いトレーニング、画像分布の変化、および少数の画像からの制約された多様性のキャプチャなどの欠点があります。
この記事では、これらの問題に取り組む提案されたアプローチを報告しており、望ましいクラスのより正確な表現、語彙的な曖昧さの解消、および細かい詳細の描写の改善を提供しています。これにより、元の事前訓練済み拡散モデルの表現力を損なうことなく、前述の欠点に直面することなく達成されます。この方法の概要は、以下の図に示されています。
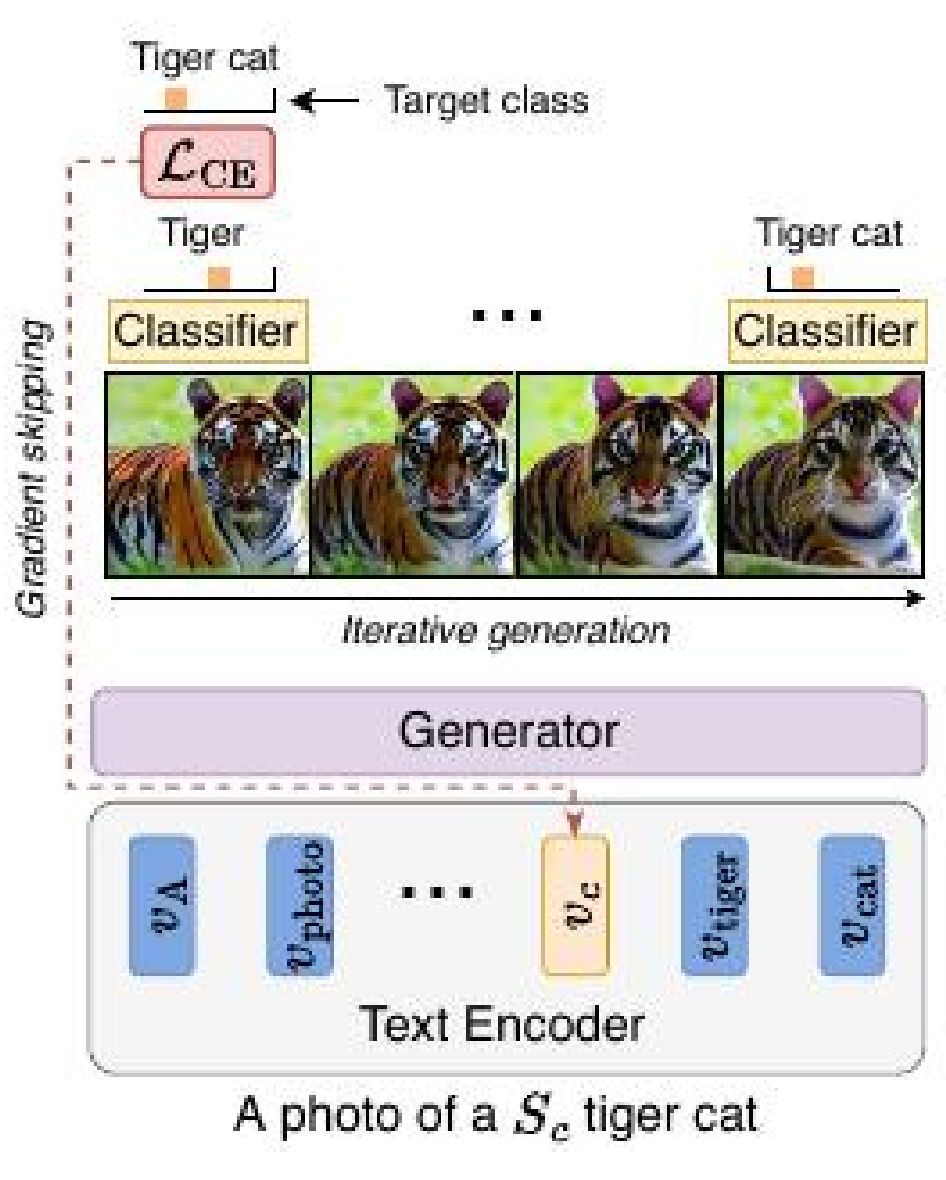

拡散プロセスをガイドしたり、モデル全体を変更する代わりに、このアプローチでは、各関心クラスに対応する単一の追加トークンの表現を更新することに焦点を当てています。重要なことは、この更新はラベル付きの画像でモデルのチューニングを行わないことです。
この方法では、事前に訓練された分類器に基づいて、新しい画像を生成する反復的なプロセスを通じて、特定のターゲットクラスのトークン表現を学習します。分類器からのフィードバックは、各反復で指定されたクラストークンの進化をガイドします。勾配スキップと呼ばれる新しい最適化技術が採用されており、勾配は拡散プロセスの最終ステージを通じてのみ伝播されます。最適化されたトークンは、元の拡散モデルを使用して画像を生成するための条件付きテキスト入力の一部として組み込まれます。
著者によれば、この方法にはいくつかの主要な利点があります。事前に訓練された分類器のみが必要であり、明示的にノイズのあるデータで訓練された分類器を要求しません。また、より時間のかかる方法とは対照的に、クラストークンがトレーニングされるとすぐに生成された画像の改善が可能で、速度に優れています。
研究から選択されたサンプル結果を以下の画像に示します。これらの事例研究は、提案された手法と最先端の手法の比較的な概要を提供します。

これは、事前にトレーニングされた分類器を利用してテキストから画像への拡散モデルを微調整する、新しいAI非侵襲技術の要約でした。興味があり、さらに詳しく知りたい場合は、以下に引用されたリンクをご参照ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- マイクロソフトの研究者が「InstructDiffusion:コンピュータビジョンタスクを人間の指示に合わせるための包括的かつ汎用的なAIフレームワーク」というタイトルで発表しました
- 大規模な言語モデルは本当に数学をできるのか?この人工知能AIの研究はMathGLMを紹介します:計算機なしで数学問題を解くための頑健なモデル
- 「量子ブースト:cuQuantumとPennyLaneによるスーパーコンピュータ上でのシミュレーション」
- 「研究者たちが、数千の変形可能な結び目を発見」
- 百度のAI研究者がVideoGenを紹介:高フレーム精度で高解像度のビデオを生成できる新しいテキストからビデオを生成する手法
- 「Google DeepMindの研究者たちは、PROmptingによる最適化(OPRO)を提案する:大規模言語モデルを最適化器として」
- グーグルの研究者たちは、MEMORY-VQという新しいAIアプローチを提案していますこれにより、メモリ拡張モデルのストレージ要件を削減することができますが、パフォーマンスを犠牲にすることはありません






