Learn more about Search Results vLLM

- You may be interested
- BERTopic(バートピック):v0.16の特別さ...
- 「初心者のためのPandasを使ったデータフ...
- AIはETLの再発明に時間を浪費する必要はない
- 「音波センサーを使用したロボットのネッ...
- 混乱するデータサイエンティストのためのP...
- 「多数から少数へ:機械学習における次元...
- LangChain:LLMがあなたのコードとやり取...
- デルタレイク – パーティショニング...
- 「エンコーディングからエンベディングへ」
- Googleは、AIのトレーニングに公開Webデー...
- データサイエンスは変わった、死んだわけ...
- 「LangchainとDeep Lakeでドキュメントを...
- 実際のデータなしで効率的なテーブルの事...
- 「3Dガウシアンスプラッティング入門」
- ChatGPTを使用して、忘れられないスローガ...

「vLLMの解読:言語モデル推論をスーパーチャージする戦略」
イントロダクション 大規模言語モデル(LLM)は、コンピュータとの対話方法を革新しました。しかし、これらのモデルを本番環境に展開することは、メモリ消費量と計算コストの高さのために課題となることがあります。高速なLLM推論とサービングのためのオープンソースライブラリであるvLLMは、PagedAttentionと呼ばれる新しいアテンションアルゴリズムと連携して、これらの課題に対処します。このアルゴリズムは効果的にアテンションのキーと値を管理し、従来のLLMサービング方法よりも高いスループットと低いメモリ使用量を実現します。 学習目標 この記事では、以下の内容について学びます: LLM推論の課題と従来のアプローチの制約を理解する。 vLLMとは何か、そしてどのように機能するのか理解する。 vLLMを使用したLLM推論のメリット。 vLLMのPagedAttentionアルゴリズムがこれらの課題を克服する方法を発見する。 vLLMを既存のワークフローに統合する方法を知る。 この記事はData Science Blogathonの一環として公開されました。 LLM推論の課題 LLMは、テキスト生成、要約、言語翻訳などのタスクでその価値を示しています。しかし、従来のLLM推論手法でこれらのLLMを展開することはいくつかの制約を抱えています: 大きなメモリフットプリント:LLMは、パラメータや中間アクティベーション(特にアテンションレイヤーからのキーと値のパラメータ)を保存するために大量のメモリを必要とし、リソースに制約のある環境での展開が困難です。 スループットの限定:従来の実装では、大量の同時推論リクエストを処理するのが難しく、スケーラビリティと応答性が低下します。これは、大規模言語モデルが本番サーバーで実行され、GPUとの効果的な連携が行えない影響を受けます。 計算コスト:LLM推論における行列計算の負荷は、特に大規模モデルでは高額になることがあります。高いメモリ使用量と低いスループットに加えて、これによりさらにコストがかかります。 vLLMとは何か vLLMは高スループットかつメモリ効率の良いLLMサービングエンジンです。これは、PagedAttentionと呼ばれる新しいアテンションアルゴリズムと連携して、アテンションのキーと値をより小さな管理しやすいチャンクに分割することで効果的に管理します。このアプローチにより、vLLMのメモリフットプリントが削減され、従来のLLMサービング手法と比べて大きなスループットを実現することができます。テストでは、vLLMは従来のHuggingFaceサービングよりも24倍、HuggingFaceテキスト生成インファレンス(TGI)よりも2〜5倍高速になりました。また、連続的なバッチ処理とCUDAカーネルの最適化により、インファレンスプロセスをさらに洗練させています。 vLLMのメリット vLLMは従来のLLMサービング手法よりもいくつかの利点を提供します: 高いスループット:vLLMは、最も人気のあるLLMライブラリであるHuggingFace Transformersよりも最大24倍の高いスループットを実現できます。これにより、より少ないリソースでより多くのユーザーに対応することができます。 低いメモリ使用量:vLLMは、従来のLLMサービング手法と比べて非常に少ないメモリを必要とするため、ソフトハードウェアのプラットフォームに展開する準備ができています。…

「vLLMに会ってください:高速LLM推論とサービスのためのオープンソース機械学習ライブラリ」
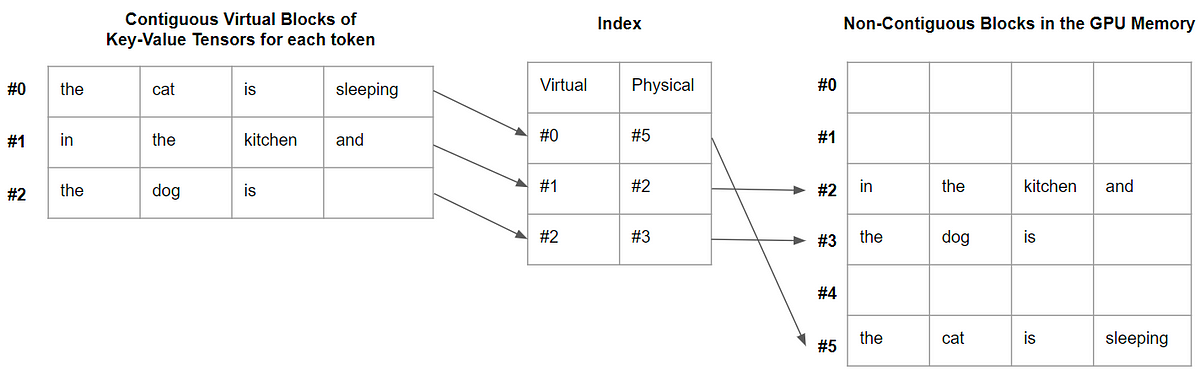
大規模な言語モデル(LLM)は、プログラミングアシスタントやユニバーサルチャットボットなどの新しいアプリケーションを可能にするため、日常生活やキャリアにますます大きな影響を与えています。しかし、これらのアプリケーションの動作は、GPUなどの重要なハードウェアアクセラレータの要件による重要なコストがかかります。最近の研究によると、LLMのリクエストの処理は、従来のキーワード検索と比較して、10倍以上高価になることが示されています。そのため、LLMのサービングシステムのスループットを向上させ、リクエストごとの費用を最小限に抑える必要性が高まっています。 大規模な言語モデル(LLM)の高スループットなサービスを実行するには、一度に十分な数のリクエストをバッチ処理する必要があります。ただし、既存のシステムは支援が必要です。各リクエストのキーバリューキャッシュ(KVキャッシュ)メモリは非常に大きく、動的に成長および縮小する可能性があります。このメモリは慎重に管理する必要があります。効率的に管理されていない場合、断片化や冗長な重複により、このRAMを大幅に節約し、バッチサイズを減らすことができます。 研究者たちは、この問題の解決策として、オペレーティングシステムの伝統的な仮想メモリとページング技術に着想を得たアテンションアルゴリズム「PagedAttention」を提案しています。メモリの利用をさらに削減するために、研究者たちはvLLMも展開しています。このLLMサービスは、ほぼゼロのKVキャッシュメモリの無駄を生じず、リクエスト内およびリクエスト間でのKVキャッシュの柔軟な共有を提供します。 vLLMは、PagedAttentionを使用してアテンションキーとバリューを管理します。モデルアーキテクチャの変更を必要とせずに、HuggingFace Transformersよりも最大24倍のスループットを提供するvLLMは、LLMサービスの現在の最先端を再定義します。 従来のアテンションアルゴリズムとは異なり、PagedAttentionでは、連続したメモリ空間にキーと値を格納することができます。PagedAttentionは、各シーケンスのKVキャッシュをブロックに分割し、予め定められたトークンの数に対応するキーと値を含んでいます。これらのブロックは、アテンション計算中にPagedAttentionカーネルによって効率的に識別されます。ブロックは必ずしも連続する必要がないため、キーと値を柔軟に管理することができます。 PagedAttention内のシーケンスの最後のブロックのみでメモリリークが発生します。実際の使用では、これにより効果的なメモリ利用が可能となり、わずか4%の非効率性しか生じません。このメモリ効率の向上により、GPUの利用率を高めることができます。 また、PagedAttentionには効率的なメモリ共有のもう一つの利点があります。PagedAttentionのメモリ共有機能は、並列サンプリングやビームサーチなどのサンプリング技術に必要な追加メモリを大幅に削減します。これにより、メモリ利用率を最大55%削減しながら、スピードを最大2.2倍向上させることができます。この改善により、これらのサンプル技術は大規模言語モデル(LLM)サービスにおいて有用で効果的なものとなります。 研究者たちは、このシステムの精度を研究しました。彼らは、FasterTransformerやOrcaなどの最先端のシステムと同じ遅延時間で、vLLMが有名なLLMのスループットを2〜4倍増加させることを発見しました。より大きなモデル、より複雑なデコーディングアルゴリズム、およびより長いシーケンスは、より顕著な改善をもたらします。

vLLMについて HuggingFace Transformersの推論とサービングを加速化するオープンソースLLM推論ライブラリで、最大24倍高速化します
大規模言語モデル、略してLLMは、人工知能(AI)の分野において画期的な進歩として登場しました。GPT-3などのこのようなモデルは、自然言語理解を完全に革新しました。これらのモデルが既存の大量のデータを解釈し、人間らしいテキストを生成できる能力を持っていることから、これらのモデルは、AIの未来を形作るために膨大な可能性を秘めており、人間と機械の相互作用とコミュニケーションに新たな可能性を開くことができます。ただし、LLMで達成された大成功にもかかわらず、このようなモデルに関連する重要な課題の1つは、計算の非効率性であり、最も強力なハードウェアでも遅いパフォーマンスにつながることがあります。これらのモデルは、数百万から数十億のパラメータで構成されているため、このようなモデルをトレーニングするには、広範囲な計算リソース、メモリ、および処理能力が必要であり、常にアクセスできるわけではありません。さらに、これらの複雑なアーキテクチャによる遅い応答時間により、LLMはリアルタイムまたはインタラクティブなアプリケーションでは実用的ではなくなることがあります。そのため、これらの課題に対処することは、LLMのフルポテンシャルを引き出し、その利点をより広く利用可能にするために不可欠なことになります。 この問題に取り組むため、カリフォルニア大学バークレー校の研究者たちは、vLLMというオープンソースライブラリを開発しました。このライブラリは、LLMの推論とサービングのためのよりシンプルで、より速く、より安価な代替方法です。Large Model Systems Organization (LMSYS)は、現在、このライブラリをVicunaとChatbot Arenaの駆動力として使用しています。初期のHuggingFace Transformersベースのバックエンドに比べて、vLLMに切り替えることで、研究機関は限られた計算リソースを使用しながらピークトラフィックを効率的に処理することができ、高い運用コストを削減することができました。現在、vLLMは、GPT-2、GPT BigCode、LLaMAなど、いくつかのHuggingFaceモデルをサポートしており、同じモデルアーキテクチャを維持しながら、HuggingFace Transformersのスループットレベルを24倍に向上させることができます。 バークレーの研究者たちは、PagedAttentionという革新的なコンセプトを導入しました。これは、オペレーティングシステムでのページングの従来のアイデアをLLMサービングに拡張した、新しいアテンションアルゴリズムです。PagedAttentionは、キーと値のテンソルをより柔軟に管理する方法を提供し、連続した長いメモリブロックが必要なくなるため、非連続のメモリスペースにそれらを格納することができます。これらのブロックは、アテンション計算中にブロックテーブルを使用して個別に取得することができ、より効率的なメモリ利用を実現します。この巧妙な技術を採用することで、メモリの無駄を4%未満に減らし、ほぼ最適なメモリ使用を実現できます。さらに、PagedAttentionは、5倍のシーケンスをまとめてバッチ処理できるため、GPUの利用率とスループットが向上します。 PagedAttentionには、効率的なメモリ共有の追加的な利点があります。複数の出力シーケンスが単一のプロンプトから同時に作成される並列サンプリング時に、PagedAttentionは、そのプロンプトに関連する計算リソースとメモリを共有することを可能にします。これは、論理ブロックを同じ物理ブロックにマッピングすることによって実現されます。このようなメモリ共有メカニズムを採用することで、PagedAttentionはメモリ使用量を最小限に抑え、安全な共有を確保します。研究者たちによる実験評価により、並列サンプリングによりメモリ使用量を55%削減し、スループットを2.2倍に向上させることができることが明らかになりました。 まとめると、vLLMは、PagedAttentionメカニズムの実装により、アテンションキーと値のメモリ管理を効果的に処理します。これにより、優れたスループット性能が実現されます。さらに、vLLMは、よく知られたHuggingFaceモデルとシームレスに統合され、並列サンプリングなどの異なるデコーディングアルゴリズムと一緒に使用することができます。ライブラリは、簡単なpipコマンドを使用してインストールでき、オフライン推論とオンラインサービングの両方に現在利用可能です。
vLLM:24倍速のLLM推論のためのPagedAttention
この記事では、PagedAttentionとは何か、そしてなぜデコードを大幅に高速化するのかを説明します

デシAIはDeciLM-7Bを紹介します:超高速かつ超高精度の70億パラメータの大規模言語モデル(LLM)
技術の進化が絶えず進む中で、言語モデルは欠かせない存在となりました。これらのシステムは高度な人工知能によって動力を得ており、デジタルプラットフォームとのインタラクションを向上させます。LLM(Language Models)は人間の言語の理解と生成を促進し、人間のコミュニケーションと機械の理解とのギャップを埋めるために設計されています。技術の進歩により、言語モデルは情報処理、コミュニケーション、問題解決においてますます重要な役割を果たすデジタル時代を迎えました。 最近、Deciは7兆パラメータクラスで利用可能な高精度高速な革新的なモデルであるDeciLM-7Bを導入しました。Apache 2.0でライセンスされたこのモデルは、7兆パラメータクラスで類を見ない精度と速度を誇る新世代の言語モデルの最前線に立っています。このモデルは、言語処理の進歩と変革の力を備えています。 DeciLM-7BはThe Open Language Model Leaderboardにおいて61.55の印象的な平均スコアを記録しています。これは、DeciLM-7Bが7兆パラメータクラスで最も先進的なベース言語モデルであり、さまざまなアプリケーションにおいて改善された精度と信頼性を提供していることを示しています。Mistral 7Bは、Arc、HellaSwag、MMLU、Winogrande、GSM8Kを含むいくつかのベンチマークで従来のモデルよりも優れたパフォーマンスを発揮します。 DeciLM-7Bは単に精度が高いだけでなく、驚異的な速度能力を持っています。Mistral 7Bに比べてスループットが83%向上し、Llama 2 7Bに比べて139%も向上しています。DeciLM-7Bは言語モデルの効率性の基準を引き上げています。PyTorchのベンチマークでは、Mistral 7BおよびLlama 2 7Bよりも1.83倍および2.39倍のスループットを示しており、その優位性がハイライトされています。 DeciLM-7BとInfery、Decが開発した推論SDKの相乗効果により、vLLMを使用したMistral 7Bに比べて4.4倍の速度向上が実現され、コスト効果の高い大量ユーザーインタラクションの可能性が提供されます。 DeciLM-7BはNASパワードエンジン、AutoNACを活用しています。このモデルは複雑な好み最適化手法なしで、上位の7兆パラメータの説明モデルの中で優れた性能を発揮します。研究者たちは、DeciLM-7BとInfery-LLMが革新的な変化をいくつかの産業にもたらす可能性を持つアプリケーションを持っていることを強調しています。これら2つは、リアルタイムのチャットボットによるハイボリューム顧客サービスの向上と、医療、法律、マーケティング、ファイナンスなどのテキスト重視の専門分野におけるワークフロー自動化を革新します。 まとめると、DeciLM-7Bは大規模な言語モデルにおける重要なモデルです。精度と効率性だけでなく、アクセシビリティと多様性においても言語モデルが優れていることを示しています。技術の進化につれて、DeciLM-7Bのようなモデルはデジタル世界を形作る上でますます重要になっています。これらのモデルは未来に向けた無数の可能性を示してくれます。技術の進歩とともに、これらのモデルはますます重要になり、デジタルフロンティアの多岐にわたる選択肢を展望する魅力的かつ広大な予感を私たちにもたらしてくれます。

「LLMアプリを作成するための5つのツール」
「経験豊富なMLエンジニアであろうと、新しいLLMデベロッパーであろうと、これらのツールはあなたの生産性を高め、AIプロジェクトの開発と展開を加速させるのに役立ちます」
AMD + 🤗 AMD GPUでの大規模言語モデルの即戦力アクセラレーション
今年早些时候,AMD和Hugging Face宣布合作伙伴关系在AMD的AI Day活动期间加速AI模型。我们一直在努力实现这一愿景,并使Hugging Face社区能够在AMD硬件上运行最新的AI模型,并获得最佳性能。 AMD正在为全球一些最强大的超级计算机提供动力,其中包括欧洲最快的超级计算机LUMI,该计算机拥有超过10,000个MI250X AMD GPUs。在这次活动中,AMD公布了他们最新一代的服务器级GPU,AMD Instinct™ MI300系列加速器,很快将正式推出。 在本博客文章中,我们将提供关于在AMD GPUs上提供良好开箱即用支持以及改进与最新服务器级别的AMD Instinct GPUs互操作性的进展报告。 开箱即用加速 你能在下面的代码中找到AMD特定的代码更改吗?别伤眼睛,跟在NVIDIA GPU上运行相比,几乎没有。 from transformers import AutoTokenizer, AutoModelForCausalLMimport torchmodel_id = "01-ai/Yi-6B"tokenizer…

マイクロソフトと清華大学の研究者は、「SCA(Segment and Caption Anything)を提案し、SAMモデルに地域キャプションの生成能力を効率的に装備する」と述べています
コンピュータビジョンと自然言語処理の交差点では、画像内のエンティティの領域キャプションの生成の課題に常に取り組んできました。この課題は、トレーニングデータにセマンティックラベルが存在しないことにより、特に複雑です。研究者は、このギャップに効率的に対処する方法を追求し、モデルが多様なイメージ要素を理解し、説明するための方法を見つけることを目指しています。 Segment Anything Model(SAM)は、強力なクラス非依存セグメンテーションモデルとして登場し、さまざまなエンティティをセグメント化する驚異的な能力を示しています。ただし、SAMは領域キャプションを生成する必要があり、その潜在的な応用範囲が制限されます。そのため、マイクロソフトと清華大学の研究チームは、SAMの能力を効果的に活用するためにSCA(Segment and Caption Anything)という解決策を提案しました。SCAは、SAMの重要な拡張と見なすことができます。それは効率的に領域キャプションを生成する能力をSAMに与えるように設計されています。 ブロックの構築に類似して、SAMはセグメンテーションのための堅牢な基盤を提供し、SCAはこの基盤に重要なレイヤーを追加します。この追加機能は、軽量のクエリベースのフィーチャーミキサーの形で提供されます。従来のミキサーとは異なり、このコンポーネントはSAMと因果言語モデルを結びつけて、領域固有の特徴を言語モデルの埋め込み空間と整合させます。この整合は、後続のキャプション生成に重要であり、SAMの視覚的理解と言語モデルの言語的能力との相乗効果を生み出します。 SCAのアーキテクチャは、画像エンコーダ、フィーチャーミキサー、マスクまたはテキストのためのデコーダヘッドの3つの主要なコンポーネントの熟慮された組み合わせです。モデルの要となるフィーチャーミキサーは、軽量な双方向トランスフォーマーです。これはSAMと言語モデルを結びつける結合組織として機能し、領域固有の特徴を言語の埋め込みと最適化する役割を果たします。 SCAの主な強みの一つは、効率性です。数千万個のトレーニング可能なパラメータを持つ、トレーニングプロセスがより高速かつスケーラブルになります。この効率性は、SAMのトークンをそのまま保持しながら、追加のフィーチャーミキサーにのみ焦点を当てた戦略的な最適化から生じます。 研究チームは、領域キャプションデータの不足を克服するために、弱い監督による事前トレーニング戦略を採用しています。このアプローチでは、モデルは物体検出とセグメンテーションタスクで事前トレーニングされ、完全な文章の説明ではなくカテゴリ名を含むデータセットを活用します。このような弱い監督による事前トレーニングは、限られた領域キャプションデータを超えて視覚的概念の一般的な知識を転送するための実用的な解決策です。 SCAの有効性を検証するためには、比較分析、さまざまなビジョンラージランゲージモデル(VLLM)の評価、およびさまざまな画像エンコーダのテストが行われています。モデルはリファリング式生成(REG)タスクで強力なゼロショットパフォーマンスを示し、その適応性と汎化能力を示しています。 まとめると、SCAはSAMの堅牢なセグメンテーション能力をシームレスに拡張する有望な進歩です。軽量なフィーチャーミキサーの戦略的な追加とトレーニングの効率性とスケーラビリティにより、SCAはコンピュータビジョンと自然言語処理の持続的な課題に対する注目すべき解決策となります。

「OpenAIモデルに対するオープンソースの代替手段の探索」
序文 AIの領域では、11月はドラマチックな展開がありました。GPTストアやGPT-4-turboのローンチ、そしてOpenAIの騒動まで、まさに忙しい一ヶ月でした。しかし、ここで重要な問題が浮かび上がります:クローズドモデルとその背後にいる人々はどれだけ信頼できるのでしょうか?自分が実際に運用しているモデルが内部の企業ドラマに巻き込まれて動作停止するのは快適な体験とは言えません。これはオープンソースモデルでは起こらない問題です。展開するモデルには完全な管理権限があります。データとモデルの両方に対して主権を持っています。しかし、OSモデルをGPTと置き換えることは可能でしょうか?幸いなことに、既に多くのオープンソースモデルが、GPT-3.5モデル以上の性能を発揮しています。本記事では、オープンソースのLLM(Large Language Models)およびLMM(Large Multi-modal Models)の最高の代替品をいくつか紹介します。 学習目標 オープンソースの大規模言語モデルについての議論。 最新のオープンソース言語モデルとマルチモーダルモデルについての探求。 大規模言語モデルを量子化するための簡易な導入。 LLMをローカルおよびクラウド上で実行するためのツールやサービスについて学ぶ。 この記事は、データサイエンスブログマラソンの一環として公開されました。 オープンソースモデルとは何ですか モデルがオープンソースと呼ばれるのは、モデルの重みとアーキテクチャが自由に利用できる状態にあるからです。これらの重みは、例えばMeta’s Llamaのような大規模言語モデルの事前訓練パラメータです。これらは通常、ファインチューニングされていないベースモデルやバニラモデルです。誰でもこれらのモデルを使用し、カスタムデータでファインチューニングして下流のアクションを実行することができます。 しかし、それらはオープンなのでしょうか?データはどうなっているのでしょうか?多くの研究所は、著作権に関する懸念やデータの機密性の問題などの理由から、ベースモデルの訓練データを公開しません。これはまた、モデルのライセンスに関する部分にも関連しています。すべてのオープンソースモデルは、他のオープンソースソフトウェアと同様のライセンスが付属しています。Llama-1などの多くのベースモデルは非商用ライセンスとなっており、これらのモデルを利用して収益を上げることはできません。しかし、Mistral7BやZephyr7Bなどのモデルは、Apache-2.0やMITライセンスが付属しており、どこでも問題なく使用することができます。 オープンソースの代替品 Llamaのローンチ以来、オープンソースの領域ではOpenAIモデルに追いつこうとする競争が繰り広げられています。そしてその結果は今までにないものでした。GPT-3.5のローンチからわずか1年で、より少ないパラメータでGPT-3.5と同等またはそれ以上のパフォーマンスを発揮するモデルが登場しました。しかし、GPT-4は依然として理性や数学からコード生成までの一般的なタスクには最も優れたモデルです。オープンソースモデルのイノベーションと資金調達のペースを見ると、GPT-4のパフォーマンスに近づくモデルが間もなく登場するでしょう。とりあえず、これらのモデルの素晴らしいオープンソースの代替品について話しましょう。 Meta’s Llama 2 Metaは今年7月にLlama-2という彼らの最高のモデルをリリースし、その印象的な能力により一瞬で人気を集めました。MetaはLlama-7b、Llama-13b、Llama-34b、Llama-70bの4つの異なるパラメータサイズのLlama-2モデルをリリースしました。これらのモデルは、それぞれのカテゴリにおいて他のオープンモデルを上回る性能を発揮しました。しかし、現在ではmistral-7bやZephyr-7bのような複数のモデルが、多くのベンチマークで小さなLlamaモデルを上回る性能を発揮しています。Llama-2 70bはまだそのカテゴリーで最高のモデルの一つであり、要約や機械翻訳などのタスクにおいてGPT-4の代替モデルとして価値があります。 Llama-2はGPT-3.5よりも多くのベンチマークで優れたパフォーマンスを発揮し、GPT-4に迫ることもできました。以下のグラフは、AnyscaleによるLlamaとGPTモデルのパフォーマンス比較です。…

新しいAmazon SageMakerコンテナでLLMの推論パフォーマンスを強化する
今日、Amazon SageMakerは、大規模モデル推論(LMI)Deep Learning Containers(DLCs)の新バージョン(0.25.0)をリリースし、NVIDIAのTensorRT-LLMライブラリのサポートを追加しましたこれらのアップグレードにより、SageMaker上で最先端のツールを簡単に使用して大規模言語モデル(LLMs)を最適化し、価格パフォーマンスの利点を得ることができます - Amazon SageMaker LMI TensorRT-LLM DLCは、レイテンシを33%削減します[...]
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.