Learn more about Search Results XLM-R

- You may be interested
- 「サンゴ礁の衰退を転換する:CUREEロボッ...
- 「カスタムPyTorchオペレーターを使用して...
- 物議を醸している:GrokがOpenAIのコード...
- データサイエンスのインタビューのためのA...
- 「Ai X ビジネスおよびイノベーションサミ...
- LangChain:LLMがあなたのコードとやり取...
- 「ゼロ冗長最適化(ZeRO):Pythonによる...
- 「CohereによるLLM大学に関する必要なすべ...
- AI記事スキャンダルがアリーナグループに...
- 「NVIDIAは創造的AIの台頭に対応するため...
- チャットテンプレート:静かなパフォーマ...
- ジェミニに会いましょう:Googleの最大か...
- Q-学習入門 第1部への紹介
- OpenAIはGPT-4をターボチャージしています...
- 深層学習を用いた強力なレコメンデーショ...

「LLMテクノロジーの理解」
「LLMテクノロジーの進歩を発見しましょうLLMテクノロジーの世界を探求し、AIとNLPの分野における重要な役割を見つけましょう」

セールスフォースAIがGlueGenを導入:効率的なエンコーダのアップグレードとマルチモーダル機能により、テキストから画像へのモデルが革新的になります
テキストから画像への変換(T2I)モデルの急速に進化する風景の中で、GlueGenの導入により新たなフロンティアが現れています。T2Iモデルは、テキストの説明から画像を生成する驚異的な能力を示していますが、機能の修正や強化の点での堅牢さは重要な課題となっています。GlueGenは、シングルモーダルまたはマルチモーダルのエンコーダを既存のT2Iモデルと調整することにより、このパラダイムを変えることを目指しています。このアプローチは、ノースウェスタン大学、Salesforce AI Research、スタンフォード大学の研究者によって行われ、アップグレードや拡張を簡素化し、多言語サポート、音声から画像の生成、強化されたテキストエンコーディングの新たな時代を切り拓いています。本記事では、GlueGenの変革的なポテンシャルについて掘り下げ、X-to-image(X2I)生成の進化におけるその役割を探求します。 拡散プロセスに基づく既存のT2I生成手法は、特にユーザが提供するキャプションに基づいて画像を生成する点で、著しい成功を収めています。しかし、これらのモデルは、テキストエンコーダを画像デコーダときちんと結びつけるという課題を抱えており、修正やアップグレードが煩雑となっています。他のT2Iアプローチへの参照としては、GANベースの方法(Generative Adversarial Nets(GANs)、Stack-GAN、Attn-GAN、SD-GAN、DM-GAN、DF-GAN、LAFITE)や、DALL-E、CogViewなどの自己回帰トランスフォーマーモデル、さらにはGLIDE、DALL-E 2、Imagenなどの拡散モデルが用いられています。 アルゴリズムの改善と広範なトレーニングデータによって、T2I生成モデルは大きく進化しています。拡散ベースのT2Iモデルは画像の品質に優れていますが、制御性と構成性に苦労し、望ましい結果を得るために即座のエンジニアリングを必要とすることがしばしばあります。また、英語のテキストキャプションでの訓練が主流であることも制約となっています。 GlueGenフレームワークは、異なるシングルモーダルまたはマルチモーダルのエンコーダの特徴を既存のT2Iモデルの潜在空間と調整するためのGlueNetを導入しています。彼らのアプローチは、平行コーパスを使用した新しいトレーニング目的を用いて、異なるエンコーダ間の表現空間を整合させるものです。GlueGenの機能は、非英語のキャプションから高品質な画像生成を可能にするXLM-Robertaなどの多言語言語モデルをT2Iモデルと調整することにも広がります。さらに、音声から画像の生成を可能にするAudioCLIPなどのマルチモーダルエンコーダをStable Diffusionモデルと調整することもできます。 GlueGenは、多様な特徴表現を整列させる能力を提供し、既存のT2Iモデルに新しい機能をシームレスに統合することができます。これは、非英語のキャプションから高品質な画像を生成するためにXLM-Robertaのような多言語言語モデルをT2Iモデルと整列させることにより実現します。また、音声から画像の生成を可能にするAudioCLIPなどのマルチモーダルエンコーダをStable Diffusionモデルと整列させることもGlueGenが行うことができます。この方法は、提案された目的リウェイト技術により、バニラのGlueNetに比べて画像の安定性と精度も向上させます。評価はFIDスコアとユーザースタディによって行われます。 まとめると、GlueGenは、さまざまな特徴表現を整列させることで、既存のT2Iモデルの適応性を向上させる解決策を提供します。多言語言語モデルやマルチモーダルエンコーダを整列させることにより、T2Iモデルの能力を拡張し、さまざまなソースから高品質な画像を生成することができます。GlueGenの効果は、提案された目的リウェイト技術によって支えられる画像の安定性と精度の向上によって示されます。さらに、T2Iモデルにおけるテキストエンコーダと画像デコーダの緊密な結び付きを破るという課題にも取り組み、簡単なアップグレードと置換を可能にしています。全体として、GlueGenはX-to-image生成機能を進化させる有望な手法を提案しています。
「多言語音声技術の障壁の克服:トップ5の課題と革新的な解決策」
「Siri、Alexa、Googleアシスタントなどの音声アシスタントは一般的な名前ですが、まだ多言語環境ではうまく機能しませんこの記事では、まず音声アシスタントの動作の概要を説明し、次に、優れた多言語対応を提供する際の音声アシスタントのトップ5の課題について詳しく説明します...」

チューリッヒ大学の研究者たちは、スイスの4つの公用語向けの多言語言語モデルであるSwissBERTを開発しました
有名なBERTモデルは、最近の自然言語処理の主要な言語モデルの1つです。この言語モデルは、入力シーケンスを出力シーケンスに変換するいくつかのNLPタスクに適しています。BERT(Bidirectional Encoder Representations from Transformers)は、Transformerのアテンションメカニズムを使用しています。アテンションメカニズムは、テキストのコーパス内の単語やサブワード間の文脈的な関係を学習します。BERT言語モデルは、NLPの進歩の最も顕著な例の1つであり、自己教師あり学習の技術を使用しています。 BERTモデルを開発する前、言語モデルは訓練時にテキストシーケンスを左から右に解析したり、左から右および右から左の組み合わせで解析することがありました。この一方向のアプローチは、次の単語を予測してシーケンスに追加し、それを繰り返して完全な意味のある文を生成するためにうまく機能しました。BERTでは、双方向のトレーニングが導入され、以前の言語モデルと比較して言語の文脈と流れのより深い理解が得られました。 元々のBERTモデルは英語向けにリリースされました。その後、フランス語向けのCamemBERTやイタリア語向けのGilBERToなど、他の言語モデルが開発されました。最近、チューリッヒ大学の研究者チームがスイスのための多言語言語モデルを開発しました。SwissBERTと呼ばれるこのモデルは、スイス標準ドイツ語、フランス語、イタリア語、ロマンシュグリシュンで21,000万以上のスイスのニュース記事をトレーニングし、合計120億トークンでトレーニングされました。 SwissBERTは、スイスの研究者が多言語タスクを実行することができないという課題に対処するために導入されました。スイスは主に4つの公用語、ドイツ語、フランス語、イタリア語、ロマンシュ語を持っており、各言語ごとに個別の言語モデルを組み合わせて多言語タスクを実行することは困難です。また、第4の国語であるロマンシュ語のための独立したニューラル言語モデルはありません。NLPの分野では多言語タスクの実装がやや困難であるため、SwissBERTの前にスイスの国語のための統一されたモデルは存在しませんでした。SwissBERTは、これらの言語の記事を単純に組み合わせて、共通のエンティティとイベントを暗黙的に利用して多言語表現を作成することで、この課題を克服します。 SwissBERTモデルは、81の言語で共に事前トレーニングされたクロスリンガルモジュラープリトレーニング(X-MOD)トランスフォーマーからリモデルされました。研究者は、カスタム言語アダプタをトレーニングすることで、プリトレーニング済みのX-MODトランスフォーマーを自分たちのコーパスに適応させました。彼らはSwissBERTのためのスイス固有のサブワード語彙を作成し、その結果得られたモデルは総パラメータ数が1億5300万にもなります。 研究チームは、SwissBERTのパフォーマンスを様々なタスクで評価しました。これには、現代のニュース(SwissNER)での固有名詞の認識や、スイスの政治に関するユーザー生成コメントでの立場の検出などが含まれます。SwissBERTは、一般的なベースラインを上回り、XLM-Rに比べて立場の検出においても改善が見られました。また、ロマンシュ語でのモデルの能力を評価した結果、SwissBERTは、言語でトレーニングされていないモデルに比べて、ゼロショットのクロスリンガル転送やドイツ語-ロマンシュ語の単語や文の整列において優れたパフォーマンスを発揮しました。ただし、モデルは、歴史的なOCR処理されたニュースでの固有名詞の認識にはあまり優れていませんでした。 研究者は、SwissBERTをダウンストリームタスクのファインチューニングのための例と共に公開しました。このモデルは将来の研究や非営利目的においても有望です。さらなる適応により、ダウンストリームタスクはモデルの多言語性の恩恵を受けることができます。

インターネット上でのディープラーニング:言語モデルの共同トレーニング
Quentin LhoestさんとSylvain Lesageさんの追加の助けを得ています。 現代の言語モデルは、事前学習に多くの計算リソースを必要とするため、数十から数百のGPUやTPUへのアクセスなしでは入手することが不可能です。理論的には、複数の個人のリソースを組み合わせることが可能かもしれませんが、実際には、インターネット上の接続速度は高性能GPUスーパーコンピュータよりも遅いため、このような分散トレーニング手法は以前は限定的な成功しか収めていませんでした。 このブログ記事では、参加者のネットワークとハードウェアの制約に適応することができる新しい協力的な分散トレーニング方法であるDeDLOCについて説明します。私たちは、40人のボランティアを使ってベンガル語の言語モデルであるsahajBERTの事前学習を行うことで、実世界のシナリオでの成功を示します。ベンガル語の下流タスクでは、このモデルは数百の高級アクセラレータを使用したより大きなモデルとほぼ同等のクオリティを実現しています。 オープンコラボレーションにおける分散深層学習 なぜやるべきなのか? 現在、多くの高品質なNLPシステムは大規模な事前学習済みトランスフォーマーに基づいています。一般的に、その品質はサイズとともに向上します。パラメータ数をスケールアップし、未ラベルのテキストデータの豊富さを活用することで、自然言語理解や生成において類を見ない結果を実現することができます。 残念ながら、これらの事前学習済みモデルを使用するのは、便利なだけではありません。大規模なデータセットでのトランスフォーマーのトレーニングに必要なハードウェアリソースは、一般の個人やほとんどの商業または研究機関には手の届かないものです。例えば、BERTのトレーニングには約7000ドルかかると推定され、GPT-3のような最大のモデルでは、この数は1200万ドルにもなります!このリソースの制約は明らかで避けられないもののように思えますが、広範な機械学習コミュニティにおいて事前学習済みモデル以外の代替手段は本当に存在しないのでしょうか? ただし、この状況を打破する方法があるかもしれません。解決策を見つけるために、周りを見渡すだけで十分かもしれません。求めている計算リソースは既に存在している可能性があるかもしれません。たとえば、多くの人々は自宅にゲームやワークステーションのGPUを搭載したパワフルなコンピュータを持っています。おそらく、私たちがFolding@home、Rosetta@home、Leela Chess Zero、または異なるBOINCプロジェクトのように、ボランティアコンピューティングを活用することで、彼らのパワーを結集しようとしていることはお分かりいただけるかもしれませんが、このアプローチはさらに一般的です。たとえば、いくつかの研究所は、自身の小規模なクラスタを結集して利用することができますし、低コストのクラウドインスタンスを使用して実験に参加したい研究者もいるかもしれません。 疑い深い考え方をすると、ここで重要な要素が欠けているのではないかと思うかもしれません。分散深層学習においてデータ転送はしばしばボトルネックとなります。複数のワーカーから勾配を集約する必要があるためです。実際、インターネット上での分散トレーニングへの単純なアプローチは必ず失敗します。ほとんどの参加者はギガビットの接続を持っておらず、いつでもネットワークから切断される可能性があるためです。では、家庭用のデータプランで何かをトレーニングする方法はどうすればいいのでしょうか? 🙂 この問題の解決策として、私たちは新しいトレーニングアルゴリズム、Distributed Deep Learning in Open Collaborations(またはDeDLOC)を提案しています。このアルゴリズムの詳細については、最近公開されたプレプリントで詳しく説明しています。では、このアルゴリズムの中核となるアイデアについて見てみましょう! ボランティアと一緒にトレーニングする 最も頻繁に使用される形態の分散トレーニングにおいては、複数のGPUを使用したトレーニングは非常に簡単です。ディープラーニングを行う場合、通常はトレーニングデータのバッチ内の多くの例について損失関数の勾配を平均化します。データ並列の分散DLの場合、データを複数のワーカーに分割し、個別に勾配を計算し、ローカルのバッチが処理された後にそれらを平均化します。すべてのワーカーで平均勾配が計算されたら、モデルの重みをオプティマイザで調整し、モデルのトレーニングを続けます。以下に、実行されるさまざまなタスクのイラストを示します。 多くの場合、同期の量を減らし、学習プロセスを安定化させるために、ローカルのバッチを平均化する前にNバッチの勾配を蓄積することができます。これは実際のバッチサイズをN倍にすることと同等です。このアプローチは、最先端の言語モデルのほとんどが大規模なバッチを使用しているという観察と組み合わせることで、次のようなシンプルなアイデアに至りました。各オプティマイザステップの前に、すべてのボランティアのデバイスをまたいで非常に大規模なバッチを蓄積しましょう!この方法は、通常の分散トレーニングと完全に等価であり、簡単にスケーラビリティを実現するだけでなく、組み込みの耐障害性も持っています。以下に、それを説明する例を示します。 共同の実験中に遭遇する可能性のあるいくつかの故障ケースを考えてみましょう。今のところ、最も頻繁なシナリオは、1人または複数の参加者がトレーニング手続きから切断されることです。彼らは不安定な接続を持っているか、単に自分のGPUを他の用途に使用したいだけかもしれません。この場合、トレーニングにはわずかな遅れが生じますが、これらの参加者の貢献は現在蓄積されているバッチサイズから差し引かれます。しかし、他の参加者が彼らの勾配でそれを補ってくれるでしょう。また、さらに多くの参加者が加わる場合、目標のバッチサイズは単純により速く達成され、トレーニング手続きは自然にスピードアップします。これを以下のビデオでデモンストレーションしています。…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…
🤗 Transformersを使用して、低リソースASRのためにXLSR-Wav2Vec2を微調整する
新着(11/2021):このブログ投稿は、XLSRの後継であるXLS-Rを紹介するように更新されました。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。Wav2Vec2の優れた性能が、ASRの最も人気のある英語データセットであるLibriSpeechで示されるとすぐに、Facebook AIはWav2Vec2の多言語版であるXLSRを発表しました。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習できる能力を指します。 XLSRの後継であるXLS-R(「音声用のXLM-R」という意味)は、Arun Babu、Changhan Wang、Andros Tjandraなどによって2021年11月にリリースされました。XLS-Rは、自己教師付き事前学習のために128の言語で約500,000時間のオーディオデータを使用し、パラメータ数が30億から200億までのサイズで提供されています。事前学習済みのチェックポイントは、🤗 Hubで見つけることができます: Wav2Vec2-XLS-R-300M Wav2Vec2-XLS-R-1B Wav2Vec2-XLS-R-2B BERTのマスクされた言語モデリング目的と同様に、XLS-Rは自己教師付き事前学習中に特徴ベクトルをランダムにマスクしてからトランスフォーマーネットワークに渡すことで、文脈化された音声表現を学習します(左側の図)。 ファインチューニングでは、事前学習済みネットワークの上に単一の線形層が追加され、音声認識、音声翻訳、音声分類などのラベル付きデータでモデルをトレーニングします(右側の図)。 XLS-Rは、公式論文のTable 3-6、Table 7-10、Table 11-12で、以前の最先端の結果に比べて音声認識、音声翻訳、話者/言語識別の両方で印象的な改善を示しています。 セットアップ このブログでは、XLS-R(具体的には事前学習済みチェックポイントWav2Vec2-XLS-R-300M)をASRのためにファインチューニングする方法について詳しく説明します。 デモンストレーションの目的で、我々は低リソースなASRデータセットのCommon Voiceでモデルをファインチューニングします。このデータセットには検証済みのトレーニングデータが約4時間しか含まれていません。…

🤗 Hubでのスーパーチャージド検索
huggingface_hubライブラリは、ホスティングエンドポイント(モデル、データセット、スペース)を探索するためのプログラム的なアプローチを提供する軽量なインタフェースです。 これまでは、このインタフェースを介してハブでの検索は難しく、ユーザーは「知っているだけ」で慣れなければならない多くの側面がありました。 この記事では、huggingface_hubに追加されたいくつかの新機能を紹介し、ユーザーにJupyterやPythonインタフェースを離れずに使用したいモデルやデータセットを検索するためのフレンドリーなAPIを提供します。 始める前に、システムに最新バージョンのhuggingface_hubライブラリがない場合は、次のセルを実行してください: !pip install huggingface_hub -U 問題の位置づけ: まず、自分がどのようなシナリオにいるか想像してみましょう。テキスト分類のためにハブでホストされているすべてのモデルを見つけたいとします。これらのモデルはGLUEデータセットでトレーニングされ、PyTorchと互換性があります。 https://huggingface.co/models を単に開いてそこにあるウィジェットを使用することもできます。しかし、これによりIDEを離れて結果をスキャンする必要がありますし、必要な情報を得るためにはいくつかのボタンクリックが必要です。 もしもIDEを離れずにこれを解決する方法があったらどうでしょうか?プログラム的なインタフェースであれば、ハブを探索するためのワークフローにも簡単に組み込めるかもしれません。 ここでhuggingface_hubが登場します。 このライブラリに慣れている方は、すでにこの種のモデルを検索できることを知っているかもしれません。しかし、クエリを正しく取得することは試行錯誤の痛ましいプロセスです。 それを簡略化することはできるでしょうか?さあ、見てみましょう! 必要なものを見つける まず、HfApiをインポートします。これはHugging Faceのバックエンドホスティングと対話するのに役立つクラスです。モデル、データセットなどを通じて対話することができます。さらに、いくつかのヘルパークラスもインポートします:ModelFilterとModelSearchArguments from huggingface_hub import HfApi, ModelFilter,…

最適なパイプラインとトランスフォーマーパイプラインによる高速推論
推論は、Hugging Face TransformersパイプラインをサポートしてOptimumに追加されました。これには、ONNX Runtimeを使用したテキスト生成も含まれます。 BERTとTransformersの採用はますます拡大しています。Transformerベースのモデルは、自然言語処理だけでなく、コンピュータビジョン、音声、時間系列でも最先端の性能を発揮しています。💬 🖼 🎤 ⏳ 企業は、Transformerモデルを大規模なワークロードに使用するため、実験および研究フェーズから本番フェーズに移行しています。ただし、デフォルトでは、BERTおよびその関連製品は、従来の機械学習アルゴリズムと比較して、比較的遅くて大きくて複雑なモデルです。 この課題を解決するために、私たちはOptimumを作成しました。これは、BERTなどのTransformerモデルのトレーニングと推論を高速化するためのHugging Face Transformersの拡張機能です。 このブログ投稿では、次のことを学びます: 1. Optimumとは何ですか?ELI5 2. 新しいOptimum推論とパイプラインの機能 3. RoBERTaの質問応答を加速するためのエンドツーエンドチュートリアル、量子化、最適化を含む 4. 現在の制限事項 5. Optimum推論FAQ 6.…
Hugging Faceにおける推論ソリューションの概要
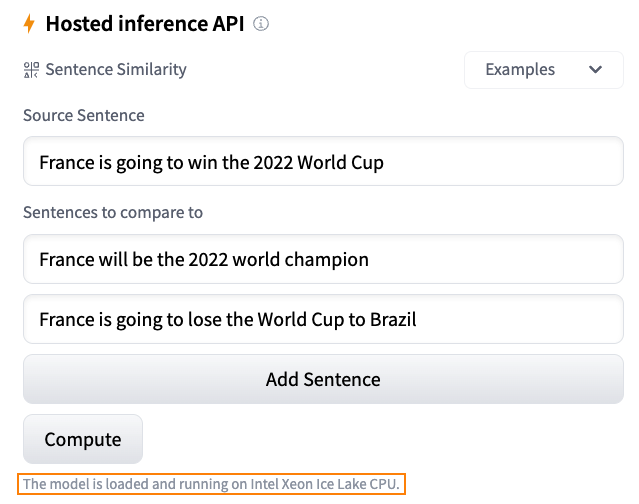
毎日、開発者や組織はHugging Faceでホストされたモデルを採用し、アイデアを概念実証デモに、デモを本格的なアプリケーションに変えています。例えば、Transformerモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習(ML)アプリケーションの人気のあるアーキテクチャとなりました。最近では、ディフューザーがテキストから画像または画像から画像を生成するための人気のあるアーキテクチャとなりました。他のアーキテクチャも他のタスクで人気があり、私たちはそれらをすべてHF Hubでホストしています! Hugging Faceでは、最新のモデルを最小限の摩擦でテストおよび展開できる能力は、MLプロジェクトのライフサイクル全体で重要です。コストとパフォーマンスの比率を最適化することも同様に重要であり、無料のCPUベースの推論ソリューションを提供していただいたインテルの友人に感謝申し上げます。これは私たちのパートナーシップにおけるさらなる大きな一歩です。また、Intel Xeon Ice Lakeアーキテクチャによる高速化を無料でお楽しみいただけるため、ユーザーコミュニティの皆様にとっても素晴らしいニュースです。 さあ、Hugging Faceでの推論オプションを見てみましょう。 無料推論ウィジェット Hugging Faceハブでの私のお気に入りの機能の1つは、推論ウィジェットです。モデルページにある推論ウィジェットを使用すると、サンプルデータをアップロードして1クリックで予測することができます。 以下は、sentence-transformers/all-MiniLM-L6-v2モデルを使用した文の類似性の例です: モデルの動作、出力、およびデータセットのいくつかのサンプルでのパフォーマンスを素早く把握する最良の方法です。モデルはサーバー上でオンデマンドでロードされ、必要なくなるとアンロードされます。コードを書く必要はありませんし、この機能は無料です。どこが好きではないですか? 無料推論API 推論APIは、推論ウィジェットの内部で動作しています。単純なHTTPリクエストで、ハブの任意のモデルをロードし、数秒でデータを予測することができます。モデルのURLと有効なハブトークンが必要です。 以下は、xlm-roberta-baseモデルを1行でロードして予測する方法です: curl https://api-inference.huggingface.co/models/xlm-roberta-base \ -X POST \…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.