Learn more about Search Results WebGPT

- You may be interested
- 「AIアラインメントの二つの側面」
- クラウド移行のマスタリング:成功させる...
- 「データを分析するためにOpenAIのコード...
- 表現力豊かなブール式を使用した説明可能なAI
- オープンLLMリーダーボード:DROPディープ...
- 「LangChain、Activeloop、およびDeepInfr...
- マイクロソフトが「オルカ2」をリリース:...
- 清華大学の研究者たちは、潜在意味モデル...
- 「Anthropic Releases Claude 2.1:拡張さ...
- GraphStormによる高速グラフ機械学習:企...
- エネルギー省が新興技術を加速させます
- ヒットパウ写真エンハンサーレビュー:最...
- AIによるテキストメッセージングの変革:...
- 偽のレビューがオンラインで横行していま...
- Pythonでインタラクティブなデータビジュ...

「2023年、オープンLLMの年」
2023年には、大型言語モデル(Large Language Models、LLMs)への公衆の関心が急増しました。これにより、多くの人々がLLMsの定義と可能性を理解し始めたため、オープンソースとクローズドソースの議論も広範な聴衆に届くようになりました。Hugging Faceでは、オープンモデルに大いに興味を持っており、オープンモデルは研究の再現性を可能にし、コミュニティがAIモデルの開発に参加できるようにし、モデルのバイアスや制約をより簡単に評価できるようにし、チェックポイントの再利用によってフィールド全体の炭素排出量を低減するなど、多くの利点があります(その他の利点もあります)。 では、オープンLLMsの今年を振り返ってみましょう! 文章が長くなりすぎないようにするために、コードモデルには触れません。 Pretrained Large Language Modelの作り方 まず、大型言語モデルはどのようにして作られるのでしょうか?(もし既に知っている場合は、このセクションをスキップしてもかまいません) モデルのアーキテクチャ(コード)は、特定の実装と数学的な形状を示しています。モデルのすべてのパラメータと、それらが入力とどのように相互作用するかがリストとして表されます。現時点では、大部分の高性能なLLMsは「デコーダーのみ」トランスフォーマーアーキテクチャのバリエーションです(詳細は元のトランスフォーマーペーパーをご覧ください)。訓練データセットには、モデルが訓練された(つまり、パラメータが学習された)すべての例と文書が含まれています。したがって、具体的には学習されたパターンが含まれます。ほとんどの場合、これらの文書にはテキストが含まれており、自然言語(例:フランス語、英語、中国語)、プログラミング言語(例:Python、C)またはテキストとして表現できる構造化データ(例:MarkdownやLaTeXの表、方程式など)のいずれかです。トークナイザは、訓練データセットからテキストを数値に変換する方法を定義します(モデルは数学的な関数であり、したがって入力として数値が必要です)。トークン化は、テキストを「トークン」と呼ばれるサブユニットに変換することによって行われます(トークン化方法によっては単語、サブワード、または文字になる場合があります)。トークナイザの語彙サイズは、トークナイザが知っている異なるトークンの数を示しますが、一般的には32kから200kの間です。データセットのサイズは、これらの個々の「原子論的」単位のシーケンスに分割された後のトークンの数としてよく測定されます。最近のデータセットのサイズは、数千億から数兆のトークンに及ぶことがあります!訓練ハイパーパラメータは、モデルの訓練方法を定義します。新しい例ごとにパラメータをどれだけ変更すべきですか?モデルの更新速度はどのくらいですか? これらのパラメータが選択されたら、モデルを訓練するためには1)大量の計算パワーが必要であり、2)有能な(そして優しい)人々が訓練を実行し監視する必要があります。訓練自体は、アーキテクチャのインスタンス化(訓練用のハードウェア上での行列の作成)および上記のハイパーパラメータを使用して訓練データセット上の訓練アルゴリズムの実行からなります。その結果、モデルの重みが得られます。これらは学習後のモデルパラメータであり、オープンな事前学習モデルへのアクセスに関して多くの人々が話す内容です。これらの重みは、推論(つまり、新しい入力の予測やテキストの生成など)に使用することができます。 事前学習済みLLMsは、重みが公開されると特定のタスクに特化または適応することもあります。それらは、「ファインチューニング」と呼ばれるプロセスを介して、ユースケースやアプリケーションの出発点として使用されます。ファインチューニングでは、異なる(通常はより専門化された小規模な)データセット上でモデルに追加の訓練ステップを適用して、特定のアプリケーションに最適化します。このステップには、計算パワーのコストがかかりますが、モデルをゼロから訓練するよりも財政的および環境的にはるかにコストがかかりません。これは、高品質のオープンソースの事前学習モデルが非常に興味深い理由の一つです。コミュニティが限られたコンピューティング予算しか利用できない場合でも、自由に使用し、拡張することができます。 2022年 – サイズの競争からデータの競争へ 2023年以前、コミュニティで利用可能だったオープンモデルはありましたか? 2022年初頭まで、機械学習のトレンドは、モデルが大きければ(つまり、パラメータが多ければ)、性能が良くなるというものでした。特に、特定のサイズの閾値を超えるモデルは能力が向上するという考えがあり、これらの概念はemergent abilitiesとscaling lawsと呼ばれました。2022年に公開されたオープンソースの事前学習モデルは、主にこのパラダイムに従っていました。 BLOOM(BigScience Large Open-science…

チャットGPTプラグインとの安全なインタラクションの変換ガイド
イントロダクション かつては静的なコンテンツの領域であったChatGPTは、ChatGPTプラグインの注入によって革命的な変革を遂げています。これらのプラグインは仮想の鍵として機能し、デジタルストーリーテリングの未踏の領域を開拓し、ユーザーエンゲージメントを再構築しています。このガイドでは、ChatGPTプラグインがブログの世界にシームレスに統合される過程を探求し、創造性を育み、コミュニティを構築し、絶えず変化する景観での進歩を予測する可能性を明らかにします。 学習目標 ChatGPTプラグインを有効化およびインストールする手順を学び、言語モデルの機能を向上させる方法を理解する。 ChatGPTプラグインのアクティブなステータスを確認し、シームレスなユーザーエクスペリエンスのためにそのパフォーマンスを監視する方法を理解する。 APIキーの取得と必要なパッケージのインストールを含む、アプリケーションにChatGPTプラグインを統合するための簡略化されたガイドを探索する。 医療、金融、製造などの実際の応用に焦点を当て、ChatGPTプラグインが効率と意思決定に与える影響を示す。 この記事はデータサイエンスブログマラソンの一環として公開されました。 ChatGPTプラグインの世界に飛び込むことは、会話ツールキットに個人のタッチを加えることと同じです。これらのモジュール拡張機能は、ユーザーが相互作用を調整し、特定のブログ目標を達成する力を与えています。コンテンツを生成するだけでなく、オーディエンスに対してユニークでダイナミックな体験を作り上げることに関わるのです。 ChatGPTプラグインの変革的な役割 ChatGPTプラグインの変革的な役割について掘り下げることで、ユーザーエンゲージメントへのその変革的な影響が明らかになります。ChatGPTは単体の形態で印象的な自然言語処理を提供しますが、プラグインは専門機能を導入することにより、その体験をさらに向上させます。これらの機能は、トリガーされる応答や文脈に気を配った相互作用から外部APIによるリアルタイム情報の取得まで、さまざまなものです。 この革新的なダイナミックは、静的な会話モデルから多目的かつ適応性のあるツールへの進化を示しており、ChatGPTとの相互作用の方法において新たな次元を開くものです。これらのプラグインの具体的な内容に探求していくことで、会話型AIの世界を再構築する可能性がますます明らかになります。 プラグインの影響を活用する 私たちの探求では、これらの多才なツールの深い意義と安定性を慎重に検証します。ChatGPTプラグインが重要であり続ける理由を探求し、ユーザーとの相互作用の形成と豊かさを探ります。 このセクションでは、ChatGPTフレームワーク内でChatGPTプラグインの安定性を詳細に検証し、その信頼性と堅牢性について洞察を提供します。これらのプラグインの影響を探ることによって、さまざまな会話シナリオでの安定したパフォーマンスと重要性について包括的な理解を提供することを目指しています。 制約と技術の理解 実践的な側面について見てみましょう。安定性と制約は重要な考慮事項です。これらのプラグインはChatGPTフレームワーク内でどのように動作するのでしょうか?ニュアンスを理解し、エクスペリエンスを最適化し、情報を得るための情報を得るための知識を活用しましょう。同時に使用できるプラグインの数にはどのような制約がありますか?効果的なカスタマイズに関する実践的な考慮事項を探索しましょう。 ChatGPTプラグインの能力とパフォーマンスに影響を与える、GPT-4の興味深い影響について。基礎となるモデルの次のイテレーションとして、GPT-4の進歩はプラグインの機能に影響を与えます。この探求により、技術の発展がChatGPTプラグインの機能にどのように影響するかが示されます。 これらの制約と技術的なニュアンスを包括的に理解することで、ユーザーはChatGPTプラグインの領域を知識を活用して安全かつ効果的に進めることができます。 安全性とモニタリング 安全性は最重要です。ChatGPTプラグインに関連する安全性について掘り下げ、安全な相互作用のための対策を概説します。安全性に関するよくある質問について、簡潔なFAQ形式で説明し、分かりやすさと安全性を築き上げます。 ChatGPTプラグインの安全性に焦点を当てたよくある質問(FAQ)を提示します。これらはChatGPT体験にプラグインを組み込むことに関するユーザーの疑問をカバーします。FAQは、安全に関する側面に関する明確化を求めるユーザーにとって貴重なリソースとなります。 このステップバイステップの検証ガイドにより、ユーザーは自分のプラグインが会話に積極的に貢献していることを確認できるようになります。安全性を重視し、効果的なモニタリングのためのツールを提供することで、このセクションではユーザーがChatGPTプラグインの世界を安全かつ自信を持って進むために必要な知識を提供します。 費用、アクセス、およびインストール…

「AVIS内部:Googleの新しい視覚情報検索LLM」
「マルチモダリティは、基礎モデルの研究において最も注目されている分野の一つですGPT-4などのモデルがマルチモーダルなシナリオで驚異的な進歩を示しているにもかかわらず、まだ多くの課題がありますが、...」
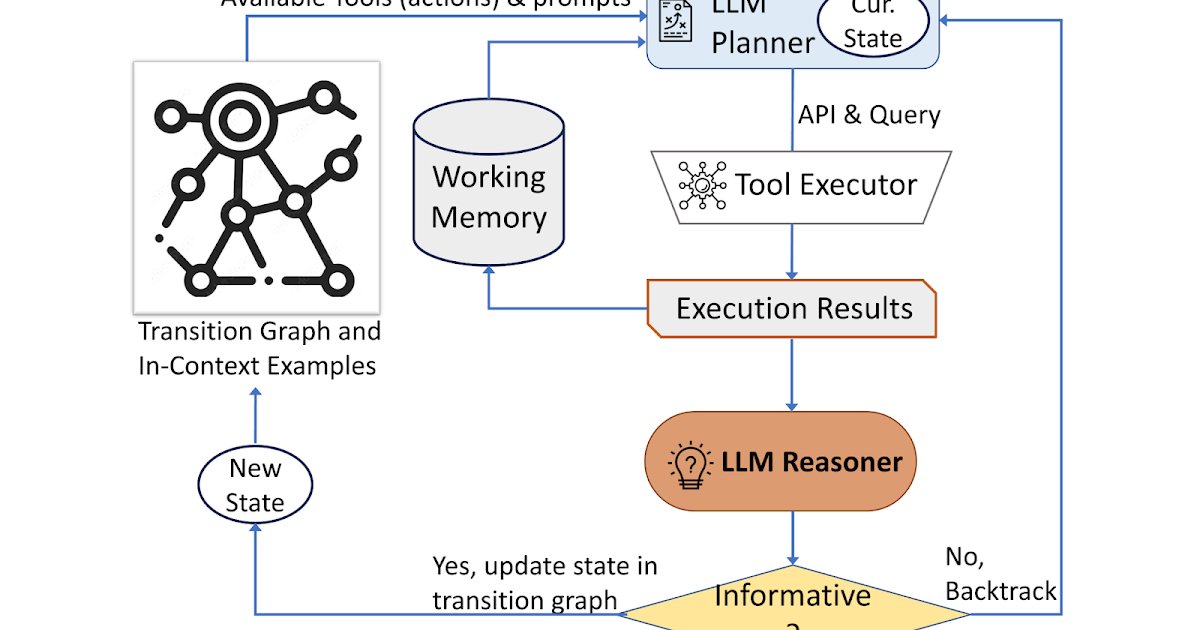
大規模な言語モデルを使用した自律型の視覚情報検索
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team 大規模言語モデル(LLM)を多様な入力に適応させるための進展があり、画像キャプショニング、ビジュアルな質問応答(VQA)、オープンボキャブラリ認識などのタスクにおいても進展が見られています。しかし、現在の最先端のビジュアル言語モデル(VLM)は、InfoseekやOK-VQAなどのビジュアル情報検索データセットにおいて、外部の知識が必要な質問に対して十分な性能を発揮できません。 外部の知識が必要なビジュアル情報検索のクエリの例。画像はOK-VQAデータセットから取得されています。 「AVIS:大規模言語モデルによる自律型ビジュアル情報検索」という論文では、ビジュアル情報検索タスクにおいて最先端の結果を達成する新しい手法を紹介しています。この手法は、LLMと3種類のツールを統合しています:(i)画像からビジュアル情報を抽出するためのコンピュータビジョンツール、(ii)オープンワールドの知識と事実を検索するためのWeb検索ツール、および(iii)視覚的に類似した画像に関連するメタデータから関連情報を得るための画像検索ツール。AVISは、LLMパワードのプランナーを使用して各ステップでツールとクエリを選択します。また、LLMパワードの推論エンジンを使用してツールの出力を分析し、重要な情報を抽出します。ワーキングメモリコンポーネントはプロセス全体で情報を保持します。 難しいビジュアル情報検索の質問に回答するためのAVISの生成されたワークフローの例。入力画像はInfoseekデータセットから取得されています。 以前の研究との比較 最近の研究(例:Chameleon、ViperGPT、MM-ReAct)では、LLMにツールを追加して多様な入力を扱うことを試みています。これらのシステムは2つのステージのプロセスに従います:プランニング(質問を構造化プログラムや命令に分解する)および実行(情報を収集するためにツールを使用する)。基本的なタスクでは成功していますが、このアプローチは複雑な実世界のシナリオではしばしば失敗します。 また、LLMを自律エージェントとして適用することに関心が高まっています(例:WebGPT、ReAct)。これらのエージェントは環境と対話し、リアルタイムのフィードバックに基づいて適応し、目標を達成します。ただし、これらの方法では各ステージで呼び出すことができるツールに制限がなく、膨大な検索空間が生じます。その結果、現在の最先端のLLMでも無限ループに陥ったり、エラーを伝播させることがあります。AVISは、ユーザースタディからの人間の意思決定に影響を受けたガイド付きLLMの使用によってこれを解決します。 ユーザースタディによるLLMの意思決定への情報提供 InfoseekやOK-VQAなどのデータセットに含まれる多くのビジュアルな質問は、人間にとっても難しい課題であり、さまざまなツールやAPIの支援が必要とされます。以下にOK-VQAデータセットの例の質問を示します。私たちは外部ツールの使用時の人間の意思決定を理解するためにユーザースタディを実施しました。…

「Retroformer」をご紹介します:プラグインの回顧モデルを学習することで、大規模な言語エージェントの反復的な改善を実現する優れたAIフレームワーク
大規模な言語モデル(LLM)を強化して、単にユーザーの質問に応答するのではなく、目標のために独立して活動できる自律的な言語エージェントにするという、力強い新しいトレンドが浮上しています。React、Toolformer、HuggingGPT、生成エージェント、WebGPT、AutoGPT、BabyAGI、Langchainなどは、LLMを利用して自律的な意思決定エージェントを開発する実用性を効果的に実証したよく知られた研究です。これらの手法は、LLMを使用してテキストベースの出力とアクションを生成し、それを使用して特定の文脈でAPIにアクセスし、活動を実行します。 ただし、現在の言語エージェントの大部分は、パラメータ数の多いLLMの範囲が非常に広いため、環境の報酬関数に最適化された行動を持っていません。ReflexionやSelf-Refine、Generative Agentなど、同様のアプローチを取る他の多くの作品とは異なり、比較的新しい言語エージェントアーキテクチャである反省アーキテクチャは、過去の失敗から学ぶために、口頭フィードバック、具体的には自己反省を利用してエージェントを支援します。これらの反射エージェントは、環境のバイナリまたはスカラーの報酬を音声入力としてテキストの要約に変換し、言語エージェントのプロンプトにさらなる文脈を提供します。 自己反省フィードバックは、エージェントに特定の改善領域を指示することで、エージェントにとって意味的な信号となります。これにより、エージェントは過去の失敗から学び、同じ間違いを繰り返さずに次回の試行でより良い結果を出すことができます。ただし、自己反省操作によって反復的な改善が可能になるものの、事前に訓練された凍結LLMから有用な反省フィードバックを生成することは困難です(図1参照)。これは、LLMが特定の環境でエージェントの誤りを特定し、改善の提案を含む要約を生成する能力が必要だからです。 図1は、凍結LLMの情報のない自己反省のイラストです。エージェントは「Teen Titans」という回答ではなく、「Teen Titans Go」と回答するべきであり、これが前回の試行が失敗した主な理由です。一連の思考、行動、詳細な観察を通じて、エージェントは目標を見失いました。しかし、凍結LLMからの音声フィードバックは、以前のアクションシーケンスを新たな計画として提案するだけであり、次の試行でも同じ間違った行動につながります。 特定の状況でのタスクの信用割り当ての問題を専門にするために、凍結言語モデルを十分に調整する必要があります。また、現在の言語エージェントは、異なる可能な報酬に基づいて勾配ベースの学習からの思考や計画に一貫した方法で取り組んでいません。Salesforce Researchの研究者は、Retroformerというモラルフレームワークを紹介し、制約を解決するためのプラグインの後向きモデルを学習して言語エージェントを強化する方法を提案しています。Retroformerは、方策最適化を通じて環境からの入力に基づいて言語エージェントのプロンプトを自動的に改善します。 具体的には、提案されたエージェントアーキテクチャは、失敗した試行を反省し、将来の報酬に対してエージェントが実行したアクションにクレジットを割り当てることで、事前に訓練された言語モデルを反復的に改善します。これは、複数の環境とタスク全体にわたる任意の報酬情報から学習することによって行われます。HotPotQAなどのオープンソースのシミュレーションおよび実世界の設定(WikipediaのAPIに繰り返し問い合わせる必要があるWebエージェントのツール使用スキルを評価する)で実験を行います。HotPotQAは、検索ベースの質問応答タスクで構成されています。反省に対して、勾配を使用しない思考や計画を行わないRetroformerエージェントは、より速く学習し、より良い意思決定を行います。具体的には、Retroformerエージェントは、検索ベースの質問応答タスクのHotPotQAの成功率をわずか4回の試行で18%向上させ、多くの状態アクション空間を持つ環境でのツール使用における勾配ベースの計画と推論の価値を証明しています。 結論として、彼らが貢献した内容は次の通りです: • この研究では、大規模言語エージェントへのコンテキスト入力に基づいて提示されるプロンプトを反復的に洗練することで、学習速度とタスク完了を向上させるRetroformerを開発しました。提案された手法は、Actor LLMのパラメータにアクセスせず、勾配を伝播する必要もないため、言語エージェントアーキテクチャ内のレトロスペクティブモデルの強化に焦点を当てています。 • 提案された手法により、さまざまなタスクと環境のためのさまざまな報酬信号からの学習が可能となります。Retroformerは、その汎用性のため、GPTやBardなどのクラウドベースのLLMに適応可能なプラグインモジュールです。

人間のフィードバックからの強化学習(RLHF)の説明
この記事は以下の言語に翻訳されています:中国語(簡体字)とベトナム語。他の言語に翻訳に興味がありますか?nathan at huggingface.co までお問い合わせください。 言語モデルは、過去数年間に人間の入力プロンプトから多様で魅力的なテキストを生成する能力を示してきました。しかし、「良い」テキストとは何かは、主観的で文脈に依存するため、本質的に定義するのは難しいです。創造性を求める物語の執筆などの多くのアプリケーションでは、真実であるべき情報の断片、または実行可能なコードのスニペットなどが必要です。 これらの属性を捉えるための損失関数を作成することは困難であり、ほとんどの言語モデルはまだ単純な次のトークン予測の損失(例:クロスエントロピー)で訓練されています。損失自体の欠点を補うために、人々はBLEUやROUGEなど、人間の優先順位をより適切に捉えるように設計されたメトリクスを定義しています。これらのメトリクスは、パフォーマンスを測定する上で損失関数自体より適しているものの、生成されたテキストを単純なルールで参照テキストと比較するだけなので、制約もあります。生成されたテキストに対する人間のフィードバックをパフォーマンスの指標として使用するか、さらに進んでそのフィードバックを損失としてモデルを最適化することができれば、素晴らしいことではないでしょうか?それが「人間のフィードバックによる強化学習(RLHF)」のアイデアです。強化学習の手法を使用して、言語モデルを人間のフィードバックで直接最適化するのです。RLHFにより、言語モデルは一般的なテキストデータのコーパスで訓練されたモデルを複雑な人間の価値に合わせることができるようになりました。 RLHFの最近の成功例は、ChatGPTでの使用です。ChatGPTの印象的な能力を考慮して、RLHFについて説明してもらいました: それは驚くほどうまくいっていますが、すべてをカバーしているわけではありません。それらのギャップを埋めましょう! 人間のフィードバックによる強化学習(RL from human preferencesとも呼ばれます)は、複数のモデルのトレーニングプロセスと異なる展開の段階を伴うため、難しい概念です。このブログ記事では、トレーニングプロセスを次の3つの主要なステップに分解します: 言語モデル(LM)の事前トレーニング データの収集と報酬モデルのトレーニング 強化学習によるLMの微調整 まず、言語モデルの事前トレーニングについて見ていきましょう。 言語モデルの事前トレーニング RLHFの出発点として、クラシカルな事前トレーニング目標で既に事前トレーニングされた言語モデルを使用します(詳細については、このブログ記事を参照してください)。OpenAIは、最初の人気のあるRLHFモデルであるInstructGPTに対して、より小さなバージョンのGPT-3を使用しました。Anthropicは、このタスクのためにトレーニングされた1,000万から520億のパラメータを持つトランスフォーマーモデルを使用しました。DeepMindは、2800億のパラメータモデルGopherを使用しました。 この初期モデルは、追加のテキストや条件で微調整することもできますが、必ずしも必要ではありません。たとえば、OpenAIは「好ましい」とされる人間が生成したテキストを微調整し、Anthropicは彼らの「助けになり、正直で無害な」基準に基づいて元のLMを蒸留することで、RLHFのための初期LMを生成しました。これらは共に、私が高価な増強データと呼ぶものの一部ですが、RLHFを理解するために必要なテクニックではありません。 一般的に、「どのモデル」がRLHFの出発点として最適かは明確な答えがありません。このブログ記事では、RLHFのトレーニングにおけるオプションの設計空間が完全に探索されていないという共通のテーマになります。 次に、言語モデルが必要なデータを生成して、人間の優先順位がシステムに統合される「報酬モデル」をトレーニングする必要があります。 報酬モデルのトレーニング 人間の優先順位に合わせてキャリブレーションされた報酬モデル(RM、優先モデルとも呼ばれます)を生成することは、RLHFの比較的新しい研究の出発点です。その基本的な目標は、テキストのシーケンスを受け取り、数値で人間の優先順位を表すべきスカラー報酬を返すモデルまたはシステムを取得することです。システムはエンドツーエンドのLMであるか、報酬を出力するモジュラーシステム(例:モデルが出力をランク付けし、ランキングが報酬に変換される)である場合があります。出力がスカラーの報酬であることは、既存のRLアルゴリズムが後のRLHFプロセスにシームレスに統合されるために重要です。 報酬モデリングのためのこれらの言語モデルは、別の微調整された言語モデルまたは好みのデータでスクラッチからトレーニングされた言語モデルのいずれかです。例えば、Anthropicは、これらのモデルを事前トレーニング(好みモデルの事前トレーニング、PMP)の後に初期化するために専門の微調整方法を使用しています。彼らは、これが微調整よりもサンプル効率が高いと結論付けましたが、報酬モデリングのバリエーションの中で明確な最良の選択肢はありません。…

基礎モデルは人間のようにデータにラベルを付けることができますか?
ChatGPTの登場以来、Large Language Models(LLM)の開発に前例のない成長が見られ、特にプロンプト形式の指示に従うように微調整されたチャットモデルの開発が増えてきました。しかし、これらのモデルの比較は、その性能を厳密にテストするために設計されたベンチマークの不足により明確ではありません。指示とチャットモデルの評価は本質的に困難であり、ユーザーの好みの大部分は質的なスタイルに集約されていますが、過去のNLP評価ははるかに定義されていました。 このような状況で、新しい大規模言語モデル(LLM)が「モデルはChatGPTに対してN%の時間で優先される」という調子でリリースされるのはよくあることですが、その文から省かれているのは、そのモデルがGPT-4ベースの評価スキームで優先されるという事実です。これらのポイントが示そうとしているのは、異なる測定の代理となるものです:人間のラベラーが提供するスコア。人間のフィードバックから強化学習でモデルを訓練するプロセス(RLHF)は、2つのモデル補完を比較するためのインターフェースとデータを増やしました。このデータはRLHFプロセスで使用され、優先されるテキストを予測する報酬モデルを訓練するために使用されますが、モデルの出力を評価するための評価とランキングのアイデアは、より一般的なツールとなっています。 ここでは、ブラインドテストセットのinstructとcode-instructの分割それぞれからの例を示します。 反復速度の観点では、言語モデルを使用してモデルの出力を評価することは非常に効率的ですが、重要な要素が欠けています:下流のツールショートカットが元の測定形式と整合しているかどうかを調査することです。このブログ投稿では、オープンLLMリーダーボード評価スイートを拡張することで、選択したLLMから得られるデータラベルを信頼できるかどうかを詳しく調べます。 LLMSYS、nomic / GPT4Allなどのリーダーボードが登場し始めましたが、モデルの能力を比較するための完全なソースが必要です。一部のモデルは、既存のNLPベンチマークを使用して質問応答の能力を示すことができ、一部はオープンエンドのチャットからのランキングをクラウドソーシングしています。より一般的な評価の全体像を提示するために、Hugging Face Open LLMリーダーボードは、自動化された学術ベンチマーク、プロの人間のラベル、およびGPT-4の評価を含むように拡張されました。 目次 オープンソースモデルの評価 関連研究 GPT-4評価の例 さらなる実験 まとめとディスカッション リソースと引用 オープンソースモデルの評価 ヒトがデータをキュレートする必要があるトレーニングプロセスのどのポイントでもコストがかかります。これまでに、AnthropicのHHHデータ、OpenAssistantの対話ランキング、またはOpenAIのLearning to Summarize /…

GopherCite 検証済みの引用を使用して回答を支援するための言語モデルの教育
ゴーファーのような言語モデルは、信憑性があるように見えるが実際には偽りの情報を「幻覚」させることがありますこの問題に詳しい人々は、言語モデルの言うことを信じるのではなく、独自の事実確認を行うことを知っていますそうでない人々は、真実でないことを信じてしまう可能性があります本論文では、言語モデルの幻覚化の問題に対処することを目指したモデルであるゴーファーサイトについて説明していますゴーファーサイトは、すべての事実的な主張をウェブの証拠で裏付けることを試みます

中国の研究者グループが開発したWebGLM:汎用言語モデル(GLM)に基づくWeb強化型質問応答システム
大規模言語モデル(LLM)には、GPT-3、PaLM、OPT、BLOOM、GLM-130Bなどが含まれます。これらのモデルは、言語に関してコンピュータが理解し、生成できる可能性の限界を大きく押し上げています。最も基本的な言語アプリケーションの一つである質問応答も、最近のLLMの突破によって大幅に改善されています。既存の研究によると、LLMのクローズドブックQAおよびコンテキストに基づくQAのパフォーマンスは、教師ありモデルのものと同等であり、LLMの記憶容量に対する理解に貢献しています。しかし、LLMにも有限な容量があり、膨大な特別な知識が必要な問題に直面すると、人間の期待には及びません。したがって、最近の試みでは、検索やオンライン検索を含む外部知識を備えたLLMの構築に集中しています。 たとえば、WebGPTはオンラインブラウジング、複雑な問い合わせに対する長い回答、同等に役立つ参照を行うことができます。人気があるにもかかわらず、元のWebGPTアプローチはまだ広く採用されていません。まず、多数の専門家レベルのブラウジング軌跡の注釈、よく書かれた回答、および回答の優先順位のラベリングに依存しており、これらは高価なリソース、多くの時間、および広範なトレーニングが必要です。第二に、システムにウェブブラウザとのやり取り、操作指示(「検索」、「読む」、「引用」など)を与え、オンラインソースから関連する材料を収集させる行動クローニングアプローチ(すなわち、模倣学習)は、基本的なモデルであるGPT-3が人間の専門家に似ている必要があります。 最後に、ウェブサーフィンのマルチターン構造は、ユーザーエクスペリエンスに対して過度に遅いことがあり、WebGPT-13Bでは、500トークンのクエリに対して31秒かかります。本研究の清華大学、北京航空航天大学、Zhipu.AIの研究者たちは、10億パラメータのジェネラル言語モデル(GLM-10B)に基づく、高品質なウェブエンハンスド品質保証システムであるWebGLMを紹介します。図1は、その一例を示しています。このシステムは、効果的で、手頃な価格で、人間の嗜好に敏感であり、最も重要なことに、WebGPTと同等の品質を備えています。システムは、LLM-拡張検索器を含む、いくつかの新しいアプローチや設計を使用して、良好なパフォーマンスを実現しています。精製されたリトリーバーと粗い粒度のウェブ検索を組み合わせた2段階のリトリーバーである。 GPT-3のようなLLMの能力は、適切な参照を自発的に受け入れることです。これは、小型の密集リトリーバーを改良するために洗練される可能性があります。引用に基づく適切なフィルタリングを使用して高品質のデータを提供することで、LLMはWebGPTのように高価な人間の専門家に頼る必要がありません。オンラインQAフォーラムからのユーザーチャムアップシグナルを用いて教えられたスコアラーは、さまざまな回答に対する人間の多数派の嗜好を理解することができます。 図1は、WebGLMがオンラインリソースへのリンクを含むサンプルクエリに対する回答のスナップショットを示しています。 彼らは、適切なデータセットアーキテクチャがWebGPTの専門家ラベリングに比べて高品質のスコアラーを生成できることを示しています。彼らの定量的な欠損テストと詳細な人間評価の結果は、WebGLMシステムがどれだけ効率的かつ効果的かを示しています。特に、WebGLM(10B)は、彼らのチューリングテストでWebGPT(175B)を上回り、同じサイズのWebGPT(13B)よりも優れています。Perplexity.aiの唯一の公開可能なシステムを改善するWebGLMは、この投稿時点で最高の公開可能なウェブエンハンスドQAシステムの一つです。結論として、著者らは次のことを提供しています。・人間の嗜好に基づく、効果的なウェブエンハンスド品質保証システムであるWebGLMを構築しました。WebGPT(175B)と同等のパフォーマンスを発揮し、同じサイズのWebGPT(13B)よりもはるかに優れています。 WebGPTは、LLMsと検索エンジンによって動力を与えられた人気システムであるPerplexity.aiをも凌駕します。•彼らは、WebGLMの現実世界での展開における制限を特定しています。彼らは、ベースラインシステムよりも効率的でコスト効果の高い利点を実現しながら、高い精度を持つWebGLMを可能にするための新しい設計と戦略を提案しています。•彼らは、Web強化QAシステムを評価するための人間の評価メトリックを定式化しています。広範な人間の評価と実験により、WebGLMの強力な能力が示され、システムの将来的な開発についての洞察が生成されました。コードの実装はGitHubで利用可能です。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.