Learn more about Search Results ViT

- You may be interested
- 「ニューラルネットワークの多様性の力を...
- 「Amazon SageMakerを使用して、生成AIを...
- 「Amazon Personalizeを使用してリアルタ...
- 「Streamlit、OpenAI、およびElasticsearc...
- 大規模な言語モデル:DeBERTa — デコーデ...
- 「模倣モデルとオープンソースLLM革命」
- 「セグミンドの生成AIによるエンパワーリ...
- 文のトランスフォーマーを使用してプレイ...
- Pythonを使用したMann-Kendall傾向検定
- 「完璧なPythonデータ可視化のためのAIプ...
- 大ニュース:Google、ジェミニAIモデルの...
- リモートセンシング(衛星)画像とキャプ...
- 「Matplotlibを使用したプロットのスタイ...
- 「コイントスを毎回勝つ方法」
- 「Pythonにおけるサンプリング技術と比較...

「画像認識の再構想:GoogleのVision Transformer(ViT)モデルが視覚データ処理のパラダイムシフトを明らかにする」
画像認識において、研究者や開発者は常に革新的なアプローチを追求してコンピュータビジョンシステムの精度と効率を向上させようとしています。伝統的に、畳み込みニューラルネットワーク(CNN)は画像データの処理に使用されるモデルとして主要な選択肢であり、意味のある特徴を抽出し視覚情報を分類する能力を活用してきました。しかし、最近の進展により、トランスフォーマベースのモデルを視覚データ分析に統合することが促進され、代替アーキテクチャの探求が行われるようになりました。 そのような画期的な進展の一つが、ビジョントランスフォーマ(ViT)モデルであり、画像をパッチのシーケンスに変換し、標準のトランスフォーマエンコーダを適用して価値ある洞察を視覚データから抽出する方法を再考しています。セルフアテンションメカニズムを活用し、シーケンスベースの処理を利用することで、ViTは画像認識に新しい視点を提供し、伝統的なCNNの能力を超え、複雑な視覚課題の効果的な処理に新たな可能性を拓いています。 ViTモデルは、2D画像をフラット化された2Dパッチのシーケンスに変換することで、画像データの処理において伝統的な理解を再構築し、元々自然言語処理(NLP)タスクで考案された標準的なトランスフォーマーアーキテクチャを適用します。各層に焼きこまれた画像固有の帰納バイアスに大きく依存するCNNとは異なり、ViTはグローバルなセルフアテンションメカニズムを活用し、モデルが効果的に画像シーケンスを処理するための一定の潜在ベクトルサイズを使用します。また、モデルの設計では学習可能な1D位置埋め込みを統合し、埋め込みベクトルのシーケンス内で位置情報を保持することが可能になります。さらに、ViTはCNNの特徴マップからの入力シーケンス形成を受け入れるハイブリッドアーキテクチャを通じて、異なる画像認識タスクに対する適応性と汎用性を向上させます。 提案されたビジョントランスフォーマ(ViT)は、画像認識タスクでの優れたパフォーマンスを示し、精度と計算効率の面で従来のCNNベースのモデルに匹敵します。セルフアテンションメカニズムとシーケンスベースの処理の力を活かして、ViTは画像データ内の複雑なパターンと空間関係を効果的に捉え、CNNに内在する画像固有の帰納バイアスを超越します。モデルの任意のシーケンス長の処理能力と画像パッチの効率的な処理により、ViTはImageNet、CIFAR-10/100、Oxford-IIIT Petsなどの人気のある画像分類データセットを含むさまざまなベンチマークで優れた結果を収めることができます。 研究チームによって実施された実験は、JFT-300Mなどの大規模データセットで事前学習を行った場合、ViTが最先端のCNNモデルを圧倒し、事前学習には大幅に少ない計算リソースを使用することを示しています。さらに、モデルは自然な画像分類から幾何学的理解を必要とする特殊なタスクまで幅広いタスクを扱う能力を示し、堅牢かつスケーラブルな画像認識ソリューションとしての潜在能力を確立しています。 まとめると、ビジョントランスフォーマ(ViT)モデルは、Transformerベースのアーキテクチャの力を活用して視覚データを効果的に処理する、画像認識における画期的なパラダイムシフトを提案しています。伝統的な画像解析アプローチを再構築し、シーケンスベースの処理フレームワークを採用することにより、ViTは従来のCNNベースのモデルを上回るパフォーマンスを示し、計算効率を維持しながら、さまざまな画像分類ベンチマークで優れた結果を収めます。グローバルなセルフアテンションメカニズムと適応的なシーケンス処理を活用することにより、ViTは複雑な視覚タスクを処理するための新たな展望を開き、コンピュータビジョンシステムの未来に向けた有望な方向性を提供します。

「ElaiのCEO&共同創業者、Vitalii Romanchenkoについてのインタビューシリーズ」
ヴィタリー・ロマンチェンコは、ElaiのCEO兼共同創設者であり、マイク、カメラ、俳優、スタジオの必要なく、個人が一流のビデオを制作できるAIビデオジェネレータープラットフォームを提供していますあなたはいくつかのスタートアップを創設したシリアルアントレプレナーですが、どのような企業がありましたか?私はテック業界で15年間を過ごしました

韓国の研究者がVITS2を提案:自然さと効率性の向上のためのシングルステージのテキスト読み上げモデルにおける飛躍的な進歩
この論文では、以前のモデルのさまざまな側面を改善することにより、より自然な音声を合成する単一ステージのテキストから音声へのモデルであるVITS2が紹介されています。このモデルは、不自然さの断続的な問題、計算効率、音素変換への依存性といった問題に取り組んでいます。提案手法は、自然さの向上、マルチスピーカーモデルにおける音声特性の類似性、トレーニングおよび推論効率を向上させます。 以前の研究では音素変換への強い依存度が大幅に低下し、完全なエンドツーエンドの単一ステージアプローチが可能になりました。 以前の手法: 2段階のパイプラインシステム:これらのシステムは、入力テキストから波形を生成するプロセスを2つの段階に分割しました。最初の段階は、入力テキストからメルスペクトログラムや言語特徴などの中間音声表現を生成しました。2番目の段階では、これらの中間表現に基づいて生の波形を生成しました。これらのシステムには、最初の段階から2番目の段階へのエラー伝播、メルスペクトログラムなどの人間によって定義された特徴への依存、中間特徴の生成に必要な計算などの制限がありました。 単一ステージのモデル:最近の研究では、入力テキストから直接波形を生成する単一ステージのモデルが積極的に探求されています。これらのモデルは、2段階のシステムを上回るだけでなく、人間の音声とほとんど区別できない高品質の音声を生成する能力も示しています。 J. Kim、J. Kong、J. Sonによるエンドツーエンドのテキストから音声への条件付き変分オートエンコーダによる敵対的学習は、単一ステージのテキストから音声への合成の分野での重要な先行研究でした。この以前の単一ステージアプローチは大きな成功を収めましたが、断続的な不自然さ、デュレーション予測の効率の低さ、複雑な入力形式、マルチスピーカーモデルにおける不十分な話者の類似性、トレーニングの遅さ、音素変換への強い依存性などの問題がありました。 本論文の主な貢献は、以前の単一ステージモデルで見つかった問題、特に上記の成功したモデルで言及された問題に取り組み、テキストから音声合成の品質と効率を向上させる改良を導入することです。 ディープニューラルネットワークベースのテキストから音声への変換は、大きな進歩を遂げています。連続的な波形への不連続なテキストの変換と、高品質の音声オーディオの確保が課題です。以前の解決策は、テキストから中間音声表現を生成し、それらの表現に基づいて生の波形を生成する2つの段階にプロセスを分割しました。単一ステージのモデルは積極的に研究され、2段階のシステムを上回っています。この論文では、以前の単一ステージモデルで見つかった問題に取り組むことを目指しています。 本論文では、デュレーション予測、正規化フローを持つ拡張変分オートエンコーダ、アライメントサーチ、話者条件付きテキストエンコーダの4つの領域で改善点が説明されています。敵対的学習を通じてトレーニングされた確率的なデュレーション予測器が提案されています。モノトニックアライメントサーチ(MAS)は、品質向上のための修正を加えたアライメントに使用されます。モデルは、長期依存関係を捉えるために正規化フローにTransformerブロックを導入します。話者条件付きテキストエンコーダは、各話者のさまざまな音声特性をより良く模倣するために設計されています。 LJ SpeechデータセットとVCTKデータセットで実験が行われました。モデルの入力として音素シーケンスと正規化されたテキストの両方が使用されました。ネットワークはAdamWオプティマイザを使用してトレーニングされ、トレーニングはNVIDIA V100 GPUで実施されました。合成音声の自然さを評価するためにクラウドソーシングされた平均意見スコア(MOS)テストが実施されました。提案手法は、以前のモデルと比較して合成音声の品質において大きな改善が示されました。提案手法の妥当性を検証するために削除研究が行われました。最後に、著者は実験、品質評価、計算速度の測定を通じて提案手法の妥当性を示しましたが、音声合成の分野にはまだ解決すべきさまざまな問題が存在し、彼らの研究が将来の研究の基盤となることを期待しています。

Googleの研究者たちは、RO-ViTを紹介しますこれは、オープンボキャブラリー検出の改善のため、リージョンに意識を向けた方法でビジョントランスフォーマーを事前トレーニングするためのシンプルなAI手法です
最近の進歩により、コンピュータは人間の視覚のように、世界から視覚情報を解釈し理解することができるようになりました。画像と動画から情報を処理、分析、抽出することを含みます。コンピュータビジョンは、視覚解釈を必要とするタスクの自動化を実現し、手作業の介入を減らすことができます。オブジェクト検出は、画像やビデオフレーム内の複数の興味深いオブジェクトを識別し、位置を特定するコンピュータビジョンのタスクです。 オブジェクト検出は、シーン内に存在するオブジェクトを判別し、それらが画像内のどこに位置しているかに関する情報を提供することを目指しています。ほとんどの現代のオブジェクト検出器は、領域とクラスラベルの手動注釈に依存していますが、これにより語彙サイズが制限され、さらなるスケーリングが高価になります。 代わりに、画像レベルの事前学習とオブジェクトレベルのファインチューニングのギャップを埋めるために、ビジョン-言語モデル(VLM)を使用することができます。ただし、そのようなモデルの事前学習プロセスでオブジェクト/領域の概念を適切に活用する必要があります。 Google Brainの研究者らは、画像レベルの事前学習とオブジェクトレベルのファインチューニングのギャップを埋めるためのシンプルなモデルを提案しています。彼らは、領域に意識を持たせたオープンボキャブラリービジョントランスフォーマー(RO-ViT)を提案しています。 RO-ViTは、オープンボキャブラリーオブジェクト検出のために、ビジョントランスフォーマーを領域に意識した方法で事前学習するためのシンプルな手法です。通常の事前学習では、画像全体の位置埋め込みが必要ですが、研究者は、全画像の位置埋め込みの代わりに、ランダムに領域の位置埋め込みを切り取り、リサイズすることを提案しています。これを「切り取られた位置埋め込み」と呼びます。 研究チームは、焦点損失を使用した画像テキストの事前学習が既存のソフトマックスCE損失よりも効果的であることを示しています。また、さまざまな新しいオブジェクト検出技術も提案しています。彼らは、既存のアプローチでは、オブジェクトの候補のステージで新しいオブジェクトを見逃すことがよくあると主張しています。なぜなら、候補はよりバランスが取れる必要があるからです。 チームは、モデルRO-ViTが最先端のLVISオープンボキャブラリー検出ベンチマークを達成していると述べています。その統計によると、イメージテキスト検索ベンチマークの12メトリックのうち9つでそれを達成しているとのことです。これは、学習された表現が領域レベルで有益であり、オープンボキャブラリー検出で非常に効果的であることを反映しています。 オブジェクト検出技術の進歩に伴い、責任ある開発、展開、規制が重要になります。その正の影響を最大化し、潜在的なリスクを軽減するためです。全体として、オブジェクト検出技術の持続的な進歩は、産業の革新、安全性と生活の質の向上、かつてはSFと考えられていたイノベーションを実現することによって、より明るい未来に貢献することが期待されています。 論文とGoogleブログをチェックしてください。この研究に関しては、このプロジェクトの研究者によるものです。また、最新のAI研究ニュース、クールなAIプロジェクトなどを共有している29k+のML SubReddit、40k+のFacebookコミュニティ、Discordチャンネル、Emailニュースレターにもぜひ参加してください。 私たちの業績が気に入ったら、ニュースレターも気に入るでしょう。 この記事はMarkTechPostで最初に公開されました。Googleの研究者は、オープンボキャブラリー検出を改善するために、リージョンに意識した方法でビジョントランスフォーマーを事前学習する単純なAI手法、RO-ViTを紹介しました。
ビジュアルトランスフォーマー(ViT)モデルのコードに深く潜る
ビジョン・トランスフォーマー(ViT)は、コンピュータビジョンの進化における重要な節目として位置づけられていますViTは、画像を最も適切に処理する手法として一般的に認識されていた畳み込み層を否定します...

Google DeepMindは、NaViTという新しいViTモデルを導入しましたこのモデルは、トレーニング中にシーケンスパッキングを使用して、任意の解像度やアスペクト比の入力を処理します
ビジョントランスフォーマ(ViT)は、そのシンプルさ、柔軟性、スケーラビリティのために、畳み込みベースのニューラルネットワークを迅速に置き換えます。画像はパッチにセグメント化され、各パッチはトークンに線形にプロジェクションされ、このモデルの基礎を形成します。入力写真は通常、正方形に整列し、使用する前に一定数のパッチに分割されます。 最近の研究では、このモデルからの潜在的な逸脱を調査しています。 FlexiViTは、連続的なシーケンス長の範囲を許容し、したがって1つの設計内でさまざまなパッチサイズに対応するためにコストを計算します。これは、各トレーニングイテレーションでパッチサイズをランダムに選択し、初期の畳み込み埋め込みで多数のパッチサイズを収容するためのスケーリング技術を使用することによって実現されます。 Pix2Structの代替パッチング手法は、アスペクト比を維持することで、グラフやドキュメントの理解などの作業には貴重です。 NaViTは、Googleの研究者が開発した代替手法です。パッチn’パックは、異なる解像度を維持しながらアスペクト比を保つための手法で、異なる画像から多数のパッチを単一のシーケンスにまとめることができます。このアイデアは、「例のパッキング」と呼ばれる自然言語処理で使用される技術に基づいており、複数のインスタンスを1つのシーケンスに組み合わせることで、長さの異なる入力で効率的にモデルをトレーニングするためのものです。科学者たちは、ランダムな解像度をサンプリングすることで、大幅なトレーニング時間の短縮が可能であることを発見しました。 NaViTは、幅広い解決策で優れたパフォーマンスを実現し、推論時に滑らかなコストパフォーマンスのトレードオフを容易に実現し、新しいジョブに対して低コストで簡単に適応できます。 アスペクト比を保った解像度サンプリング、可変トークン削除率、適応計算などの研究アイデアは、例のパッキングによって可能になった固定バッチ形状から生じます。 NaViTは、事前トレーニング中の計算効率が特に印象的であり、微調整を通じて持続します。単一のNaViTを異なる解像度に適用することに成功することで、パフォーマンスと推論コストの間の滑らかなトレードオフが可能になります。 トレーニング中および操作中のディープニューラルネットワークにデータを供給する際には、バッチで行うことが一般的です。その結果、コンピュータビジョンアプリケーションでは、最適なパフォーマンスを確保するために、予め決められたバッチサイズとジオメトリを使用する必要があります。このため、畳み込みニューラルネットワークの固有のアーキテクチャ制約とともに、画像を予め決められたサイズにリサイズまたはパッドすることが一般的な慣行となっています。 NaViTは、元のViTに基づいていますが、理論上はパッチのシーケンスを処理できるあらゆるViTのバリアントを使用することができます。研究者たちは、Patch n’ Packをサポートするために以下の構造的な変更を実装しています。 Patch n’ Packは、研究コミュニティによって証明されたように、視覚トランスフォーマにシーケンスパッキングをシンプルに適用することでトレーニング効率を劇的に向上させます。結果として得られるNaViTモデルは、柔軟であり、銀行を破ることなく新しいジョブに簡単に適応することができます。パッチn’パックによって可能になった固定バッチ形式の必要性によって以前は妨げられていた、適応計算やトレーニングと推論の効率を向上させるための新しいアルゴリズムなどの研究も行われています。彼らはまた、NaViTを、ほとんどのコンピュータビジョンモデルの従来のCNN設計の入力とモデリングパイプラインからの変更を表しているため、ViTにとって正しい方向に進む一歩と見ています。
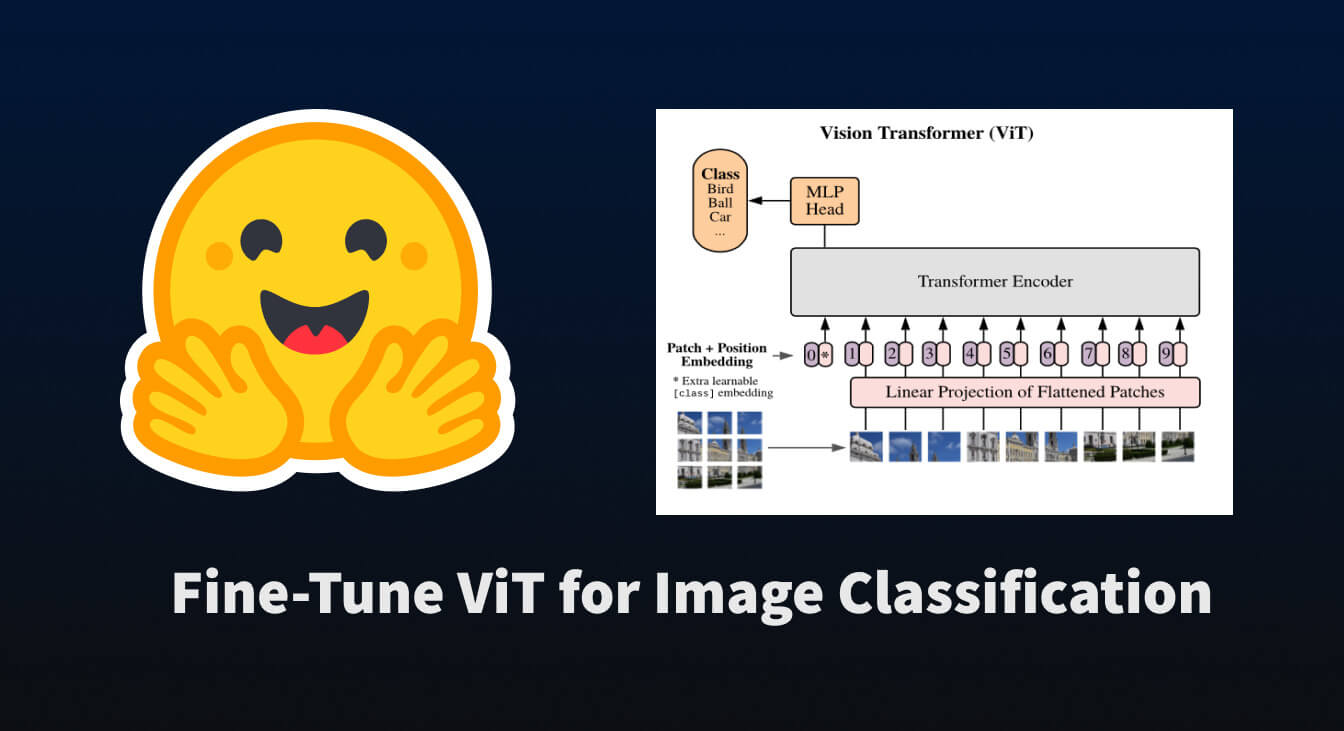
🤗 Transformersを使用して、画像分類のためにViTを微調整する
トランスフォーマーベースのモデルがNLPを革命化したように、我々は今、それらを他のさまざまな領域に適用する論文の爆発を目撃しています。その中でも最も革命的なものの一つが「Vision Transformer(ViT)」です。これは、Google Brainの研究チームによって2021年6月に紹介されました。 この論文では、文をトークン化するように画像をトークン化する方法を探求しており、それによってトランスフォーマーモデルにトレーニング用のデータとして渡すことができます。実際には非常にシンプルな概念です… 画像をサブ画像パッチのグリッドに分割する 各パッチを線形変換で埋め込む 各埋め込まれたパッチがトークンとなり、埋め込まれたパッチのシーケンスがモデルに渡される 上記の手順を実行すると、NLPのタスクと同様にトランスフォーマーを事前学習および微調整することができることがわかります。かなり便利です 😎。 このブログポストでは、🤗 datasets を使用して画像分類データセットをダウンロードおよび処理し、それを使用して事前学習済みの ViT を 🤗 transformers を使用して微調整する方法について説明します。 まずは、それらのパッケージをインストールしましょう。 pip install datasets transformers データセットの読み込み まずは、小規模な画像分類データセットを読み込んで、その構造を確認しましょう。…
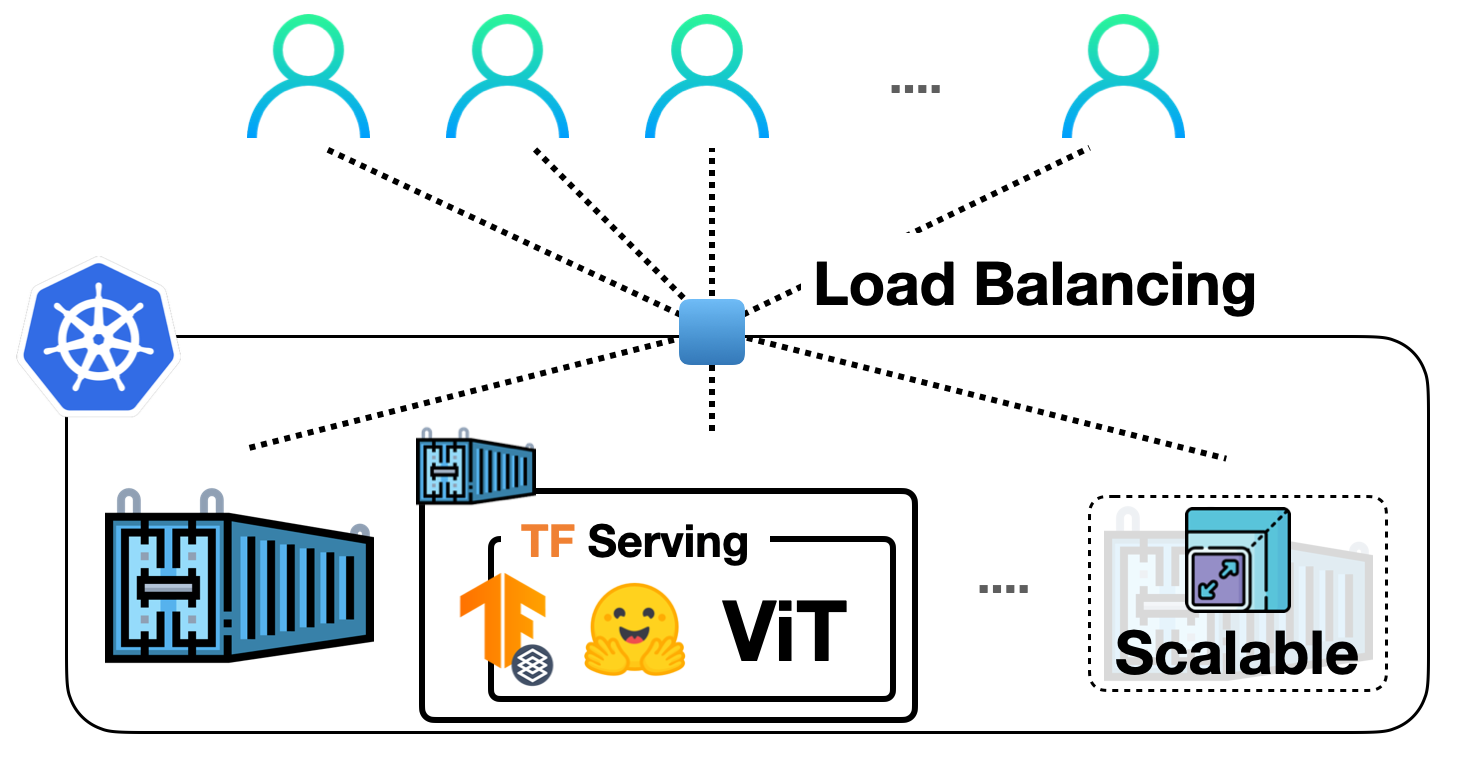
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…
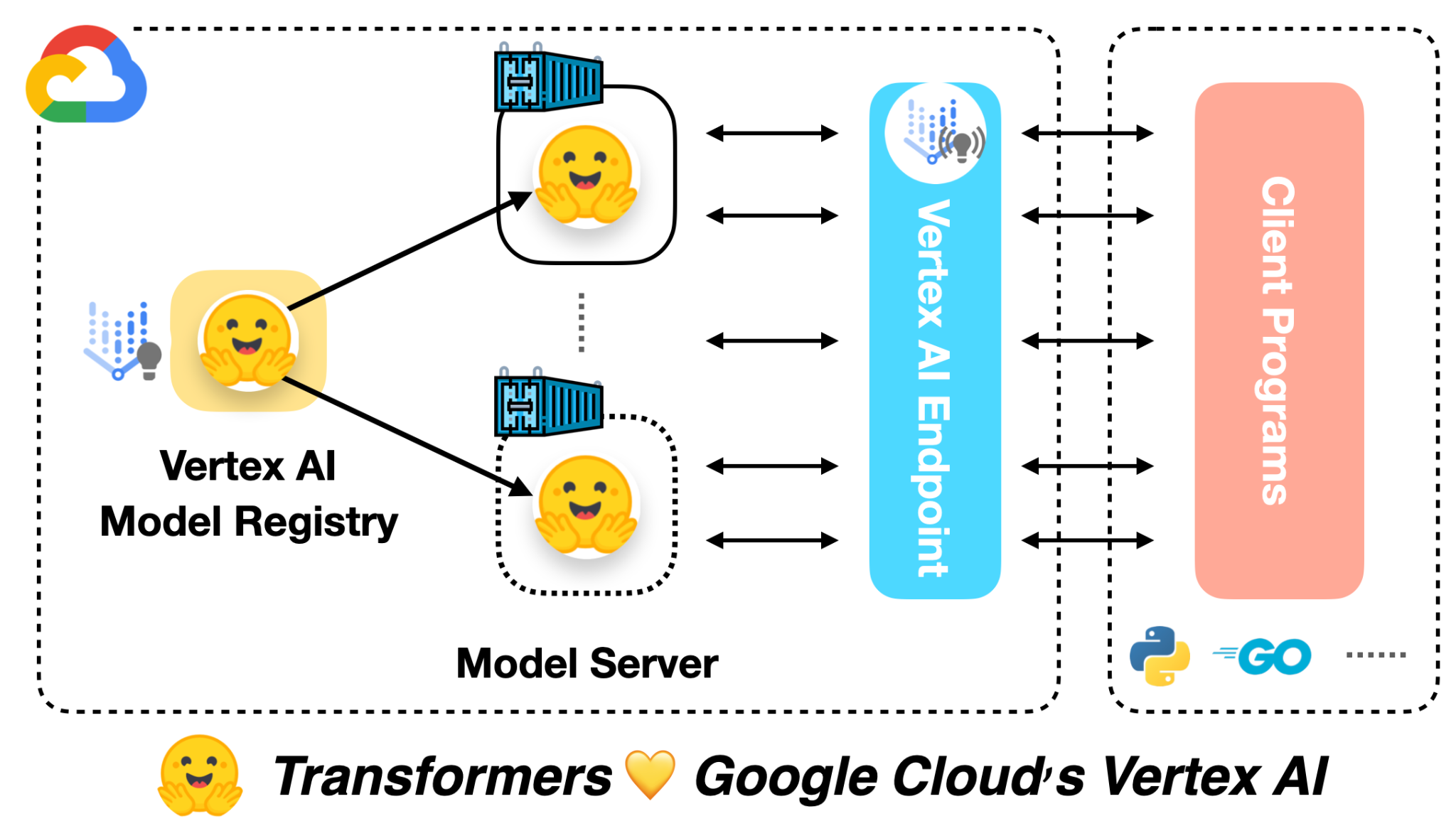
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…

カカオブレインからの新しいViTとALIGNモデル
Kakao BrainとHugging Faceは、新しいオープンソースの画像テキストデータセットCOYO(700億ペア)と、それに基づいてトレーニングされた2つの新しいビジュアル言語モデル、ViTとALIGNをリリースすることを発表しました。ALIGNモデルが無料かつオープンソースで公開されるのは初めてであり、ViTとALIGNモデルのリリースにトレーニングデータセットが付属するのも初めてです。 Kakao BrainのViTとALIGNモデルは、オリジナルのGoogleモデルと同じアーキテクチャとハイパーパラメータに従っていますが、オープンソースのCOYOデータセットでトレーニングされています。GoogleのViTとALIGNモデルは、巨大なデータセット(ViTは3億枚の画像、ALIGNは18億の画像テキストペア)でトレーニングされていますが、データセットが公開されていないため、複製することはできません。この貢献は、データへのアクセスも含めて、視覚言語モデリングを再現したい研究者にとって特に価値があります。Kakao ViTとALIGNモデルの詳細な情報は、こちらで確認できます。 このブログでは、新しいCOYOデータセット、Kakao BrainのViTとALIGNモデル、およびそれらの使用方法について紹介します!以下が主なポイントです: 史上初のオープンソースのALIGNモデル! オープンソースのデータセットCOYOでトレーニングされた初のViTとALIGNモデル Kakao BrainのViTとALIGNモデルは、Googleのバージョンと同等のパフォーマンスを示します ViTとALIGNのデモはHFで利用可能です!選んだ画像サンプルでオンラインでViTとALIGNのデモを試すことができます! パフォーマンスの比較 Kakao BrainのリリースされたViTとALIGNモデルは、Googleが報告した内容と同等またはそれ以上のパフォーマンスを示します。Kakao BrainのALIGN-B7-Baseモデルは、トレーニングペアが少ない(700億ペア対18億ペア)にもかかわらず、Image KNN分類タスクではGoogleのALIGN-B7-Baseと同等のパフォーマンスを発揮し、MS-COCO検索の画像からテキスト、テキストから画像へのタスクではより優れた結果を示します。Kakao BrainのViT-L/16は、モデル解像度384および512でImageNetとImageNet-ReaLで評価された場合、GoogleのViT-L/16と同様のパフォーマンスを発揮します。つまり、コミュニティはKakao BrainのViTとALIGNモデルを使用して、特にトレーニングデータへのアクセスが必要な場合に、GoogleのViTとALIGNリリースを再現することができます。最先端の性能を発揮しつつ、オープンソースで透明性のあるこれらのモデルのリリースを見ることができるのはとても興奮します! COYOデータセット これらのモデルのリリースの特徴は、モデルが無料かつアクセス可能なCOYOデータセットでトレーニングされていることです。COYOは、GoogleのALIGN 1.8B画像テキストデータセットに似た700億ペアの画像テキストデータセットであり、ウェブページから取得した「ノイズのある」代替テキストと画像のペアのコレクションですが、オープンソースです。COYO-700MとALIGN 1.8Bは「ノイズのある」データセットですが、最小限のフィルタリングが適用されています。COYOは、他のオープンソースの画像テキストデータセットであるLAIONとは異なり、以下の点が異なります。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.