Learn more about Search Results Vaswani et al. (2017)

- You may be interested
- ソウル国立大学の研究者たちは、効率的か...
- [GPT-4V-Actと出会いましょう:GPT-4V(isi...
- 畳み込みニューラルネットワーク ― 直感的...
- エンターテイメントデータサイエンス:ス...
- 「複雑さを排除したデータレイクテーブル...
- コマンドラインインターフェイスのsysargv...
- 「もしも、視覚のみのモデルを、わずかな...
- 2023年にディープラーニングのためのマル...
- 「データエンジニアリングの面接質問」
- 「MITとNVIDIAの研究者が、要求の厳しい機...
- 「受賞者たちは創造的AIのハイプを超えて...
- 「18/9から24/9までの週のトップ重要コン...
- VQ-Diffusion
- 水中ロボットが科学者に南極の氷の融解を...
- 安定した拡散:生成AIの基本的な直感
「自然言語処理の技術比較:RNN、トランスフォーマー、BERT」
RNN、Transformer、BERTは、シーケンスモデリング、並列化、下流のタスクのための事前トレーニングにおいて、トレードオフを持った人気のあるNLP技術です

「トランスフォーマーベースのエンコーダーデコーダーモデル」
!pip install transformers==4.2.1 !pip install sentencepiece==0.1.95 トランスフォーマーベースのエンコーダーデコーダーモデルは、Vaswani et al.によって有名なAttention is all you need論文で紹介され、現在では自然言語処理(NLP)におけるデファクトスタンダードのエンコーダーデコーダーアーキテクチャです。 最近、T5、Bart、Pegasus、ProphetNet、Margeなど、トランスフォーマーベースのエンコーダーデコーダーモデルの異なる事前学習目的に関する多くの研究が行われていますが、モデルのアーキテクチャはほとんど変わっていません。 このブログ記事の目的は、トランスフォーマーベースのエンコーダーデコーダーアーキテクチャがシーケンス対シーケンスの問題をどのようにモデル化しているかを詳細に説明することです。アーキテクチャによって定義された数学モデルとそのモデルを推論に使用する方法に焦点を当てます。途中で、NLPのシーケンス対シーケンスモデルについての背景をいくつか説明し、トランスフォーマーベースのエンコーダーとデコーダーのパーツに分解します。多くのイラストを提供し、トランスフォーマーベースのエンコーダーデコーダーモデルの理論と🤗Transformersにおける実際の使用方法のリンクを確立します。なお、このブログ記事ではそのようなモデルをトレーニングする方法については説明していません。これについては将来のブログ記事のテーマです。 トランスフォーマーベースのエンコーダーデコーダーモデルは、表現学習とモデルアーキテクチャに関する数年にわたる研究の成果です。このノートブックでは、ニューラルエンコーダーデコーダーモデルの歴史の簡単な概要を提供します。詳細については、Sebastion Ruder氏の素晴らしいブログ記事を読むことをお勧めします。また、セルフアテンションアーキテクチャの基本的な理解も推奨されます。以下のJay Alammar氏のブログ記事は、元のトランスフォーマーモデルの復習として役立ちます。 このノートブックの執筆時点では、🤗Transformersには、T5、Bart、MarianMT、Pegasusのエンコーダーデコーダーモデルが含まれており、これらはモデルの要約についてはドキュメントで要約されています。 このノートブックは4つのパートに分かれています: 背景 – ニューラルエンコーダーデコーダーモデルの短い歴史がRNNベースのモデルに焦点を当てて与えられます。 エンコーダーデコーダー…

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。 BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。 Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。 このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et…

エネルギーフォレンジックスにおける高度なAIアルゴリズムの開発:消費パターンを通じたスマートグリッド盗難検出のためのTransformerモデルのPythonガイド
ドイツのエネルギーデータからの洞察:小規模設定における消費パターンとオンラインデータサポートアナリティクスに関するステファニー・ネスによるガイド広大なデータの海の中で、各キロワット時はその物語をささやきます複雑な消費パターンの奥深くには異常、エネルギー盗難の秘話が潜んでいるかもしれませんこれらの物語は、頻繁にありふれていることが多いですが、時には高らかに響くこともあります...消費パターンを通じたスマートグリッドの盗難検出のためのトランスフォーマーモデルに関するエネルギーフォレンジクスの高度なAIアルゴリズム開発:Pythonガイドを読む»
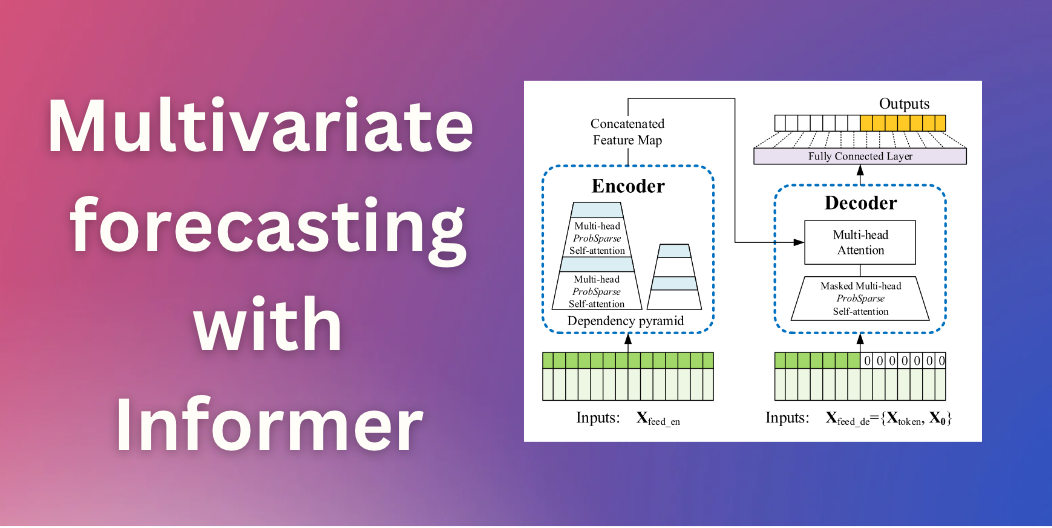
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

T5 テキストからテキストへのトランスフォーマー(パート2)
BERT [5] の提案により、自然言語処理(NLP)のための転移学習手法の普及がもたらされましたインターネット上での未ラベル化されたテキストの広範な利用可能性により、私たちは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.