Learn more about Search Results VQGAN

- You may be interested
- 「ODSC West 2023で機械学習をより良くす...
- 「ステーブル拡散」は実際にどのように機...
- マイクロソフトとETHチューリッヒの研究者...
- クラウドファーストデータサイエンス:デ...
- 機械学習の時代がコードとして到来しました
- スタビリティAIは、ステーブルディフュー...
- Diffusersライブラリの開発に関する倫理ガ...
- 合成データ生成のマスタリング:応用とベ...
- 「Ntropyの共同創設者兼CEO、ナレ・ヴァル...
- 最適なパイプラインとトランスフォーマー...
- JAXを使用してRL環境をベクトル化・並列化...
- 「Googleの研究者が球面上でのディープラ...
- スコルテックとAIRIの研究者は、ニューラ...
- 高度な顔認識のためのDeepFace
- 「Web Speech API:何がうまく機能してい...

「Q*とLVM LLMのAGIの進化」
「Q*とLVMによるAIの未来を探求し、論理的な推論とビジョンAIのためのLLMを高度化させて、AGIへの道を開拓してください」

「Würstchenをご紹介します:高速かつ効率的な拡散モデルで、テキスト条件付きコンポーネントは画像の高圧縮潜在空間で動作します」
テキストから画像を生成することは、テキストの説明から画像を作成する人工知能の難しい課題です。この問題は計算量が多く、訓練コストもかかります。高品質な画像の必要性は、これらの課題をさらに悪化させます。研究者たちは、この領域において計算効率と画像の忠実度のバランスを取ろうとしてきました。 テキストから画像を効率的に生成するために、研究者たちはWürstchenという革新的なソリューションを導入しました。このモデルは、ユニークな2段階の圧縮手法を採用することで、この分野で際立っています。ステージAではVQGANが使用され、ステージBではDiffusion Autoencoderが使用されます。これらの2つのステージをまとめてデコーダと呼びます。彼らの主な機能は、高度に圧縮された画像をピクセル空間にデコードすることです。 Würstchenの特筆すべき点は、その卓越した空間圧縮能力です。従来のモデルでは一般的に4倍から8倍の圧縮率を達成していましたが、Würstchenは驚異的な42倍の空間圧縮を実現しています。この画期的な成果は、16倍の空間圧縮後に詳細な画像を正確に再構築するのが難しい一般的な手法の制限を超える、その新しい設計の証明です。 Würstchenの成功は、2段階の圧縮プロセスに起因しています。ステージAのVQGANは、画像データを高度に圧縮された潜在空間に量子化する重要な役割を果たします。この初期の圧縮により、後続のステージに必要な計算リソースが大幅に削減されます。ステージBのDiffusion Autoencoderは、この圧縮された表現をさらに洗練し、驚くほどの忠実度で画像を再構築します。 これら2つのステージを組み合わせることで、テキストのプロンプトから効率的に画像を生成するモデルが実現されます。これにより、訓練の計算コストが削減され、推論がより高速に行えるようになります。重要なのは、Würstchenが画像の品質を犠牲にすることなく、さまざまなアプリケーションにとって魅力的な選択肢となっていることです。 さらに、WürstchenはステージCであるPriorも導入しており、高度に圧縮された潜在空間で訓練されています。これにより、Würstchenは新しい画像解像度に迅速に適応することができ、異なるシナリオに対する微調整の計算負荷を最小限に抑えることができます。この適応性により、さまざまな解像度の画像を扱う研究者や組織にとって、多目的なツールとなっています。 Würstchenの訓練コストの削減は、Würstchen v1が512×512の解像度で訓練された場合、同じ解像度でStable Diffusion 1.4に必要とされる150,000 GPU時間の一部である9,000 GPU時間だけで済んだという事実によって示されています。この大幅なコスト削減は、研究者の実験において恩恵をもたらし、このようなモデルのパワーを活用する組織にとってもよりアクセスしやすくなります。 まとめると、Würstchenはテキストから画像を生成するという長年の課題に対する画期的なソリューションを提供しています。革新的な2段階の圧縮手法と驚異的な空間圧縮率により、この領域の効率性の新基準が確立されました。訓練コストの削減とさまざまな画像解像度への迅速な適応性により、Würstchenはテキストから画像を生成する研究やアプリケーション開発を加速する価値あるツールとなっています。

「Würstchenの紹介:画像生成のための高速拡散」
Würstchenとは何ですか? Würstchenは、テキスト条件付きの成分が画像の高度に圧縮された擬似モデルです。なぜこれが重要なのでしょうか?データの圧縮により、トレーニングと推論の両方の計算コストを桁違いに削減することができます。1024×1024の画像でのトレーニングは、32×32の画像でのトレーニングよりも遥かに高価です。通常、他の研究では比較的小規模な圧縮(4倍から8倍の空間圧縮)を使用しますが、Würstchenはこれを極限まで高めました。新しいデザインにより、42倍の空間圧縮を実現しました!これは以前には見られなかったものです。なぜなら、一般的な手法では16倍の空間圧縮後に詳細な画像を忠実に再構築することができないからです。Würstchenは2段階の圧縮、ステージAとステージBを採用しています。ステージAはVQGANであり、ステージBはディフュージョンオートエンコーダーです(詳細は論文を参照)。ステージAとBはデコーダーと呼ばれ、圧縮された画像をピクセル空間に戻します。高度に圧縮された潜在空間で学習される第3のモデル、ステージCも存在します。このトレーニングでは、現在の最高性能モデルに比べてずっと少ない計算リソースが必要であり、より安価で高速な推論が可能です。ステージCを事前モデルと呼んでいます。 なぜ別のテキストから画像へのモデルが必要なのですか? それは非常に高速かつ効率的です。Würstchenの最大の利点は、Stable Diffusion XLなどのモデルよりもはるかに高速に画像を生成でき、メモリの使用量も少ないことです!A100が手元にない私たち全員にとって、これは便利なツールです。以下は、異なるバッチサイズでのSDXLとの比較です: さらに、Würstchenの大幅な利点として、トレーニングコストの削減があります。512×512で動作するWürstchen v1は、わずか9,000時間のGPUでトレーニングされました。これを、Stable Diffusion 1.4に費やされた150,000時間のGPUと比較すると、コストが16倍も削減されていることがわかります。これにより、研究者が新しい実験を行う際にだけでなく、より多くの組織がこのようなモデルのトレーニングを行うことができるようになります。Würstchen v2は24,602時間のGPUを使用しました。解像度が1536まで上がっても、これはSD1.4の6倍安価です。SD1.4は512×512でのみトレーニングされました。 詳しい説明ビデオは次のリンクでご覧いただけます: Würstchenの使用方法 こちらのデモを使用して試すこともできます: または、モデルはDiffusersライブラリを介して利用可能なため、既に慣れているインターフェースを使用することができます。例えば、AutoPipelineを使用して推論を実行する方法は次のとおりです: import torch from diffusers import AutoPipelineForText2Image from diffusers.pipelines.wuerstchen import…

「HuggingFace Diffusersにおける拡散モデルの比較と説明」
「画像生成を含む生成型AIへのますます高まる関心を受けて、多くの優れたリソースが利用可能となりつつあります以下でいくつかのハイライトを紹介しますが、私の経験に基づくと...」
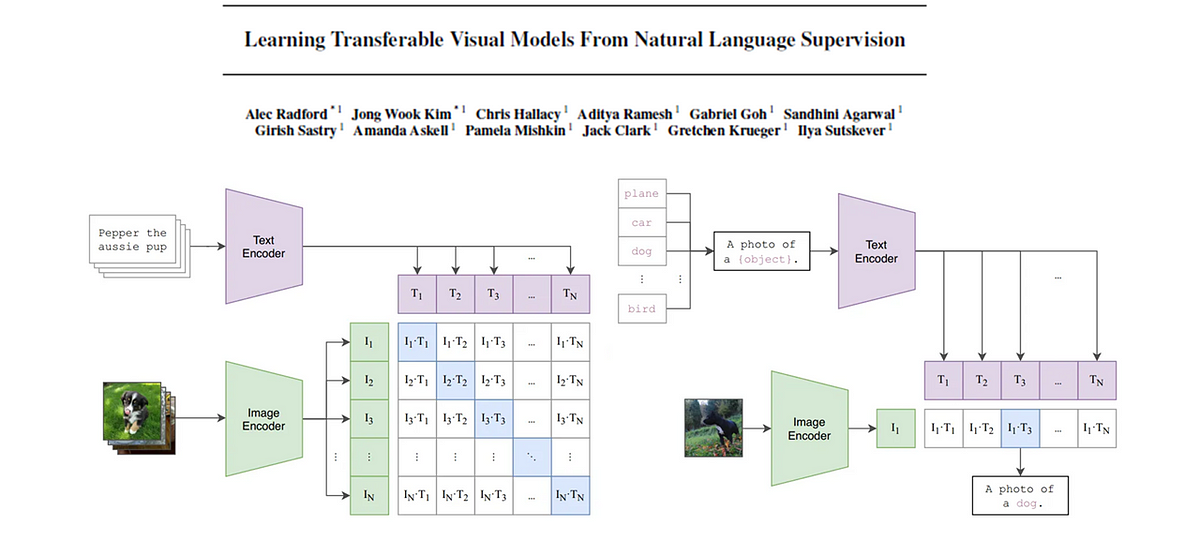
CLIP基礎モデル
この記事では、CLIP(対照的な言語画像事前学習)の背後にある論文を詳しく解説しますキーコンセプトを抽出し、わかりやすく解説しますさらに、画像...

「2023年に試してみるべき20の中間旅行の代替案」
Shutterstock.AI Shutterstock.AIは、使いやすいAI生成の画像作成および編集プラットフォームです。OpenAIとLGがサポートし、Shutterstockから収集された包括的かつ倫理的な画像を使用しています。シンプルな単語や動詞からより詳細な説明まで、画像検索機能で使用できます。感情的な言語やカメラスタイル、視点などの視覚的なシグナルも取り上げられています。ユーザーはShutterstock.AIのCreative Flowプラットフォームの助けを借りて、簡単にAIの写真を作成し、編集することができます。これにより、個人が自分の想像力からオリジナルで個性的なグラフィックを生成する道が開かれます。 Artbreeder Artbreederは、革命的なAI駆動のアート作成ツールです。コラージュや合成写真の作成を共有する繁盛するAIアートコミュニティがあります。ユーザーはCollagerツールを使用して、形や画像から素早くコラージュを作成し、質問に対する回答としてそれを説明することができます。その後、Artbreederはそれを生き返らせ、視覚的な探求の世界と自分自身の絵画、肖像画、風景の創造の機会を提供します。Splicerは既存の画像を組み合わせて新しい写真を作成するツールです。ユーザーは自分の作品を共有し、お気に入りのアーティストをフォローすることができます。Artbreederではコンセプトアート、歴史的な再現、ミュージックビデオなどが作られています。無料から「Champion」まで様々な有料のティアがあり、それぞれ高解像度の画像やアニメーションフレームのアップロードやダウンロードなどの特典があります。 Stablecog Stablecogは、プロフェッショナルな芸術作品を作成するためにStable Diffusionを使用する無料かつオープンソースの人工知能画像生成ツールです。複数の言語で利用でき、ユーザーフレンドリーに作られています。アニメ、3Dレンダリング、アニメーション映画、3Dコミックなどのデジタルアート作品の作成に適している多くの機能とカスタマイズオプションを備えています。プログラムにはプレミアムな機能と強化されたグラフィックのカスタマイズオプションへのアクセスを提供する「Pro」エディションも含まれています。瞬時に目を引くイメージを手軽に作成するための素晴らしいプログラムです。 Mage 最先端のAIと無料で迅速かつフィルタリングされていないMage Stable Diffusionツールを使用して、ユーザーは自分の夢に思い描いたものを作成することができます。Stable Diffusion v1.5およびv2.1、Openjourney、Analog、DucHaitenAIArt、Deliberate、DreamShaper、Double Exposure、Redshift、Arcane、Archer、Disney Pixar、SynthwavePunk、Vector Art、Pixel Scenery、Pixel Characters、Anything v3.0、Eimis、Waifu、Grapefruit、PFG、Realistic Vision、F222、PPPなど、多くのAIモデルが含まれています。写実主義、3Dアート、NSFW、ファンタジーなどは、各モデルの多くの用途の一部です。アスペクト比、ステップ、命令スケール、シード、ネガティブプロンプト、プライバシーなど、顧客が調整できるパラメーターもあります。 Catbird マルチモデル画像生成ツールを使用して、ユーザーは単一のクエリでさまざまなAIモデルから画像を生成することができます。このプログラムは、15以上のモデルからの出力を提供することで、さまざまな画像生成の可能性を提供します。画像生成のためのさらなる可能性が約束されていますが、現時点では、このツールはOpenjourney、Dreamlike Diffusion、Stable…
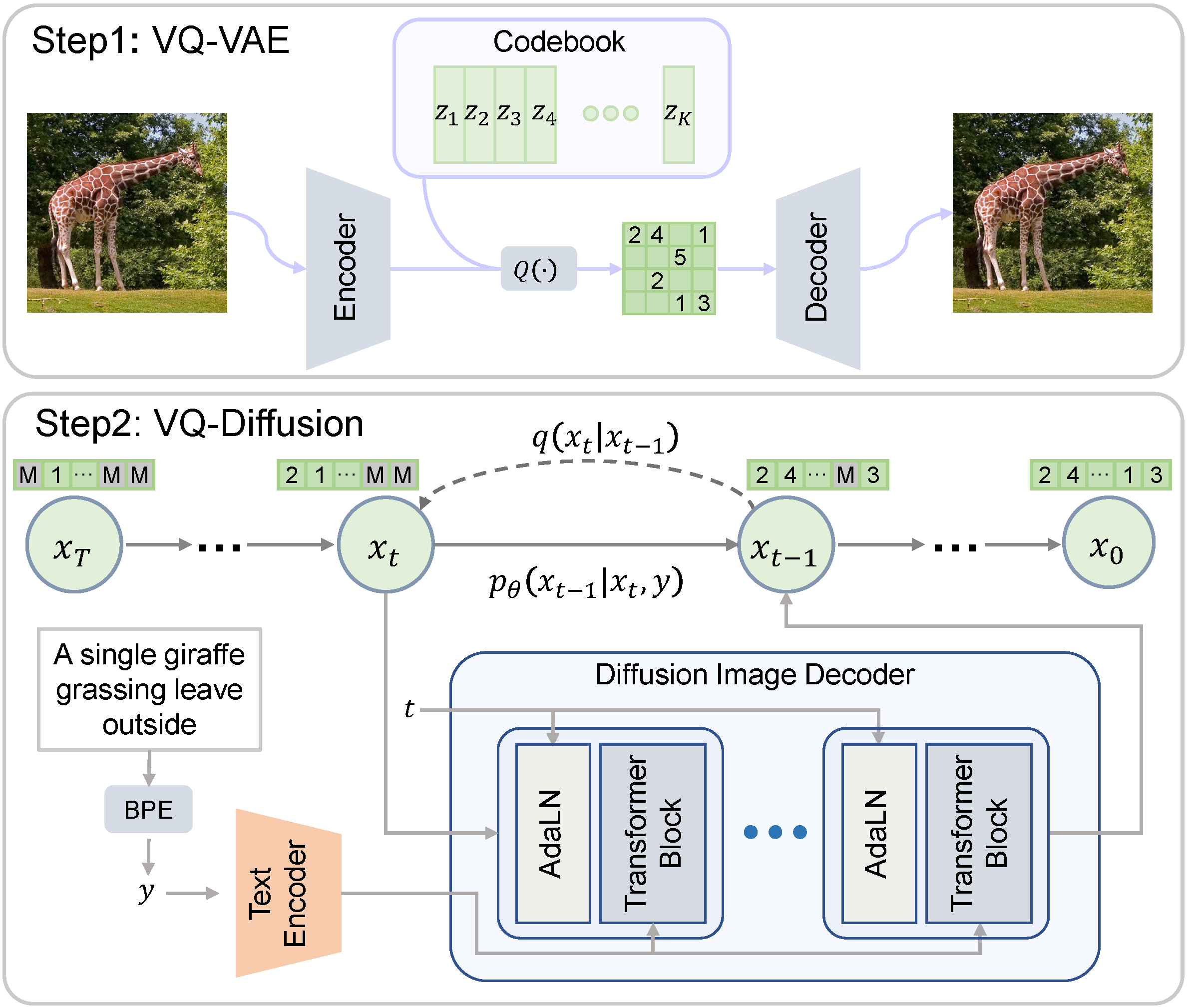
VQ-Diffusion
ベクトル量子化拡散(VQ-Diffusion)は、中国科学技術大学とMicrosoftによって開発された条件付き潜在拡散モデルです。一般的に研究されている拡散モデルとは異なり、VQ-Diffusionのノイジングとデノイジングのプロセスは量子化された潜在空間で動作します。つまり、潜在空間は離散的なベクトルの集合で構成されています。離散的な拡散モデルは、連続的な対応物と比較する興味深い比較対象を提供します。 Hugging Faceモデルカード Hugging Face Spaces オリジナルの実装 論文 デモ 🧨 Diffusersを使用すると、わずか数行のコードでVQ-Diffusionを実行できます。 依存関係をインストールする pip install 'diffusers[torch]' transformers ftfy パイプラインをロードする from diffusers import VQDiffusionPipeline pipe =…

テキストからビデオへのモデルの深掘り
ModelScopeで生成されたビデオサンプルです。 テキストからビデオへの変換は、生成モデルの驚くべき進歩の長いリストの中で次に来るものです。その名前の通り、テキストからビデオへの変換は、時間的にも空間的にも一貫性のある画像のシーケンスをテキストの説明から生成する、比較的新しいコンピュータビジョンのタスクです。このタスクは、テキストから画像への変換と非常によく似ているように思えるかもしれませんが、実際にははるかに難しいものです。これらのモデルはどのように動作し、テキストから画像のモデルとはどのように異なり、どのようなパフォーマンスが期待できるのでしょうか? このブログ記事では、テキストからビデオモデルの過去、現在、そして未来について論じます。まず、テキストからビデオとテキストから画像のタスクの違いを見直し、条件付きと非条件付きのビデオ生成の独特の課題について話し合います。さらに、テキストからビデオモデルの最新の開発について取り上げ、これらの方法がどのように機能し、どのような能力があるのかを探ります。最後に、Hugging Faceで取り組んでいるこれらのモデルの統合と使用を容易にするための取り組みや、Hugging Face Hub内外でのクールなデモやリソースについて話します。 さまざまなテキストの説明を入力として生成されたビデオの例、Make-a-Videoより。 テキストからビデオ対テキストから画像 最近の開発が非常に多岐にわたるため、テキストから画像の生成モデルの現在の状況を把握することは困難かもしれません。まずは簡単に振り返りましょう。 わずか2年前、最初のオープンボキャブラリ、高品質なテキストから画像の生成モデルが登場しました。VQGAN-CLIP、XMC-GAN、GauGAN2などの最初のテキストから画像のモデルは、すべてGANアーキテクチャを採用していました。これらに続いて、2021年初めにOpenAIの非常に人気のあるトランスフォーマーベースのDALL-E、2022年4月のDALL-E 2、Stable DiffusionとImagenによって牽引された新しい拡散モデルの新たな波が続きました。Stable Diffusionの大成功により、DreamStudioやRunwayML GEN-1などの多くの製品化された拡散モデルや、Midjourneyなどの既存製品との統合が実現しました。 テキストから画像生成における拡散モデルの印象的な機能にもかかわらず、拡散および非拡散ベースのテキストからビデオモデルは、生成能力においてはるかに制約があります。テキストからビデオは通常、非常に短いクリップで訓練されるため、長いビデオを生成するためには計算コストの高いスライディングウィンドウアプローチが必要です。そのため、これらのモデルは展開とスケーリングが困難であり、文脈と長さに制約があります。 テキストからビデオのタスクは、さまざまな面で独自の課題に直面しています。これらの主な課題のいくつかには以下があります: 計算上の課題:フレーム間の空間的および時間的な一貫性を確保することは、長期的な依存関係を伴い、高い計算コストを伴います。そのため、このようなモデルを訓練することは、ほとんどの研究者にとって手の届かないものです。 高品質なデータセットの不足:テキストからビデオの生成のためのマルチモーダルなデータセットは希少で、しばしばスパースに注釈が付けられているため、複雑な動きのセマンティクスを学ぶのが難しいです。 ビデオのキャプションに関する曖昧さ:モデルが学習しやすいようにビデオを記述する方法は未解決の問題です。完全なビデオの説明を提供するためには、複数の短いテキストプロンプトが必要です。生成されたビデオは、時間の経過に沿って何が起こるかを物語る一連のプロンプトやストーリーに基づいて条件付ける必要があります。 次のセクションでは、テキストからビデオへの進展のタイムラインと、これらの課題に対処するために提案されたさまざまな手法について別々に議論します。高レベルでは、テキストからビデオの作業では以下のいずれかを提案しています: 学習しやすいより高品質なデータセットの作成。 テキストとビデオのペアデータなしでこのようなモデルを訓練する方法。 より計算効率の良い方法で長く、高解像度のビデオを生成する方法。 テキストからビデオを生成する方法…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.