Learn more about Search Results Twitter

- You may be interested
- スタビリティAIが安定したオーディオを導...
- 「大型言語モデルを使用して開発するため...
- ChatGPTでリードマグネットのアイデアをブ...
- AI/MLを活用した観測性の向上
- 「不確実な世界での自律的なイノベーション」
- 合成時系列データ生成としてのLLM
- AIベースのアプリケーションテストのトッ...
- ドメイン特化LLMの重要性
- ウィスコンシン大学の新しい研究では、ラ...
- 「テーマパークのシミュレーション:Rを使...
- ランダムウォークタスクにおける時差0(Tem...
- Google AIは、スケールで事前に訓練された...
- ジェイソン・アーボン:「百万年後、超パ...
- 「アノテーターのように考える:データセ...
- エンタープライズデータの力を活用するた...
PythonにおけるTwitterの感情分析- Sklearn | 自然言語処理
ChatGPTや他の同じようなアプリケーションの大量導入により、今日の業界における自然言語処理の重要性や影響を無視することは不可能です...

Twitter用の15の最高のChatGPTプロンプト(X)
急速に進化するソーシャルメディアの世界で、Twitter(X)は簡潔で効果的なコンテンツが最も重要視されるプラットフォームとして際立っていますブランドやインフルエンサーを含め、誰もがエンゲージメントと可視性を競っており、独自のコンテンツ作成のアプローチが必要ですChatGPTは、その多機能性を活かして、高品質で魅力的なTwitterコンテンツの作成を支援することができますこの[…]

X / Twitterでお金を稼ぐ方法
X(別名Twitter)は、クリエイターに広告収益の一部を支払い始めましたここでは、その一部を手に入れる方法を紹介します

「ChatGPTとZapierでTwitterの成長を自動化する」
「忙しい時でも、Twitterの観客との関係を維持しましょう」

「LangChain、Activeloop、およびDeepInfraを使用したTwitterアルゴリズムのリバースエンジニアリングのためのプレーンな英語ガイド」
このガイドでは、Twitterの推奨アルゴリズムを逆解析して、コードベースをより理解し、より良いコンテンツを作成するための洞察を提供します

「データサイエンスを使って、トップのTwitterインフルエンサーを特定する」
はじめに Twitter上のインフルエンサーマーケティングの重要性は無視できません。特にビジネスにとっての利益に関しては言うまでもありません。この記事では、データサイエンスとPythonを使用して、トップのTwitterインフルエンサーを見つけるという魅力的なコンセプトを探求します。この技術を用いることで、ビジネスはTwitter上で賢明な選択をし、報酬を得ることができます。科学的な手法とPythonの能力を活用することで、ビジネスは、広範なブランド露出とエンゲージメントをもたらすことができるインフルエンサーを特定する力を得るのです。 この記事では、インフルエンサーマーケティングに関するさまざまなトピックを取り上げています。それには、インフルエンサーの選択要因、Twitterデータの収集と整理、データサイエンス技術を用いたデータの分析、およびインフルエンサーの評価と順位付けにおける機械学習アルゴリズムの活用などが含まれます。 学習目標 この記事の目的は、読者が特定の学習目標を達成することです。この記事を読み終えることで、読者は以下のことができるようになります: Twitter上のインフルエンサーマーケティングの重要性とビジネスへの利益を理解する。 データサイエンスとPythonを使用して適切なインフルエンサーを見つける方法についての知識を得る。 Twitter上でインフルエンサーを特定する際に考慮すべき要素や側面を学ぶ。 Pythonと関連するツールを使用してTwitterデータを収集し整理する技術を習得する。 Pandasなどのデータサイエンス技術やPythonライブラリを使用してTwitterデータを分析するスキルを開発する。 インフルエンサーの特定と順位付けにおいて機械学習アルゴリズムの使用方法を探索する。 関連するメトリクスと質的要素に基づいてインフルエンサーを評価する技術をマスターする。 Twitter上でインフルエンサーを特定する際の制約と課題を理解する。 実際のインフルエンサーマーケティングの事例から洞察を得て、重要な教訓を学ぶ。 Pythonを使用して自身のビジネスに最適なインフルエンサーを特定するために獲得した知識とスキルを適用する。 この記事はData Science Blogathonの一環として公開されました。 プロジェクトの概要 このプロジェクトの目的は、Twitter上のインフルエンサーマーケティングの複雑な領域をナビゲートするために、読者に必要なスキルと知識を提供することです。インフルエンサーの選択基準の確立、関連するTwitterデータの収集と準備、データサイエンス技術を用いたデータの分析、および機械学習アルゴリズムを用いたインフルエンサーの評価と順位付けなど、いくつかの要素を詳しく調べます。この記事で提供される体系的アプローチにより、読者は貴重な洞察と実践的な戦略を身につけて、マーケティング活動を効率化することができます。 この記事を通じて、読者はインフルエンサーの特定プロセスとそのTwitter上でのブランドの可視性とエンゲージメントへの重要な役割について、深い理解を得ることができます。プロジェクトの最後には、読者は自身のビジネスに新たに獲得した知識を自信を持って適用し、Twitter上の影響力のある人物を活用してマーケティング戦略を最適化し、目標とするオーディエンスと効果的につながることができるのです。 問題の提示 Twitter上でビジネスにとって関連性のある影響力のあるインフルエンサーを特定することは、複雑な問題です。ビジネスは、膨大な量のデータと絶えず変化するソーシャルメディアの環境の中で、適切なインフルエンサーを見つけることに苦労することがよくあります。また、真のエンゲージメントと信頼性を持つインフルエンサーを特定することもさらに困難です。 ビジネスは、ターゲットオーディエンスとブランドの価値と一致するインフルエンサーを見つけるために、大量のTwitterデータを手動で選別する際に障害に直面します。インフルエンサーの真正性と影響力を判断することは、主観的で時間のかかる作業となることがあります。これらの課題は、チャンスの逃失と効果のないパートナーシップにつながり、リソースの浪費やマーケティング戦略の妥協を招くことがよくあります。…

「イーロン・マスクのxAIはTwitterのフィードでトレーニングされました」
テスラやSpaceXなどの企業を展開するビジョナリーであるイーロン・マスクは、人工知能(AI)の領域に再び目を向けています。彼の最新のベンチャーであるxAIは、ツイートの広範なリポジトリを活用してアルゴリズムを訓練することを目指しています。最近のTwitter Spacesの音声チャットで、マスクは好奇心旺盛で真実を追求するAIの構築をビジョンとし、データプライバシーや法的な問題についての疑問を投げかけました。本記事では、マスクの野心的なプロジェクトとAIの景色への潜在的な影響について探っています。 また読む:イーロン・マスク、中国における超知能の台頭に警鐘を鳴らす xAI:イーロン・マスクの新しいAI企業 イーロン・マスクのxAIの発表は、テクノロジー界に波紋を広げました。テスラとTwitterのCEOであるマスクは、AIの力を「宇宙を理解する」ために活用する意図を持っています。画期的なイノベーションの実績を持つ彼の最新のベンチャーは、テクノロジー愛好家やAI懐疑論者の注目を集めています。 また読む:イーロン・マスクのxAIがOpenAIのChatGPTと対決 ツイートを使ったAIのトレーニング:物議を醸す動き xAIのトレーニングデータについてのマスクの開示は、プライバシー擁護派やTwitterユーザーの間で懸念を引き起こしました。同社は公開ツイートをアルゴリズムのデータセットとして使用する予定です。公開ツイートは技術的には誰でもアクセスできるものですが、ユーザー生成コンテンツをAIのトレーニングに利用する倫理的な問題が浮上します。 また読む:すべてのオンライン投稿はAIの所有物になる、Googleが発表 AIの好奇心と真実性 xAIの開発の重要な側面の1つは、マスクが「最大限の好奇心と最大限の真実性」を持つAIを作り出すという欲望です。この野心的な目標は、AIの能力の限界を em>超え、単なるツールではなく、知識を追求し、正確性を保ちながら意識的で倫理的な存在にすることを目指しています。 また読む:イーロン・マスクが真実を追求するAI「TruthGPT」を発表 テスラとの連携:シナジスティックなアプローチ イーロン・マスクは、xAIがテスラを含む他のベンチャーと協力して動作することを想像しています。この連携は、AI技術の進歩とテスラのソフトウェアおよび自動運転システムへのAIの統合の可能性を持っています。ただし、データ使用の重複や明確な境界の必要性についても懸念が生じます。 また読む:Sanctuary AIのPhoenix Robotとテスラの最新製品Optimusとの出会い! AI企業が直面する法的な課題 データ使用に関する法的な課題については、AI業界はよく知っています。出版社は、適切な権限なしにニュース記事や他の知的財産をAI企業が使用することに対して、ますます反対しています。デイリーメールのオーナーとGoogleの間の迫り来る法的闘争は、AIデータトレーニングの論争の性質を物語っています。 また読む:Barry Diller対生成AI:著作権の法的闘争 トレーニングプロセス:AIに意思決定をさせる AIの開発の核心は、アルゴリズムがデータを解釈し、最終的に情報を持った意思決定を行う方法を学習するトレーニングプロセスです。xAIがTwitterの広範なデータセットから学習する可能性は、より洗練されたAIシステムへの道を開くかもしれませんが、データプライバシーやユーザーの同意に関する検証を招きます。…

Twitterでの感情分析を始める
センチメント分析は、テキストデータをその極性(ポジティブ、ネガティブ、ニュートラルなど)に基づいて自動的に分類するプロセスです。企業は、ツイートのセンチメント分析を活用して、顧客が自社製品やサービスについてどのように話しているかを把握し、ビジネスの意思決定に洞察を得ること、製品の問題や潜在的なPR危機を早期に特定することができます。 このガイドでは、Twitterでのセンチメント分析を始めるために必要なすべてをカバーします。コーダーと非コーダーの両方向けに、ステップバイステップのプロセスを共有します。コーダーの場合、Inference APIを使用してツイートのセンチメント分析を簡単なコード数行でスケールして行う方法を学びます。コーディング方法を知らない場合でも心配ありません!Zapierを使用してセンチメント分析を行う方法もカバーします。Zapierはツイートを収集し、Inference APIで分析し、最終的に結果をGoogle Sheetsに送信するためのノーコードツールです⚡️ 一緒に読んで興味があるセクションにジャンプしてください🌟: センチメント分析とは何ですか? コーディングを使用したTwitterセンチメント分析の方法は? コーディングを使用せずにTwitterセンチメント分析を行う方法は? 準備ができたら、楽しんでください!🤗 センチメント分析とは何ですか? センチメント分析は、機械学習を使用して人々が特定のトピックについてどのように話しているかを自動的に識別する方法です。センチメント分析の最も一般的な用途は、テキストデータの極性(つまり、ツイートや製品レビュー、サポートチケットが何かについてポジティブ、ネガティブ、またはニュートラルに話しているかを自動的に識別すること)の検出です。 例として、@Salesforceをメンションしたいくつかのツイートをチェックして、センチメント分析モデルによってどのようにタグ付けされるかを確認してみましょう: “The more I use @salesforce the more I dislike it. It’s…
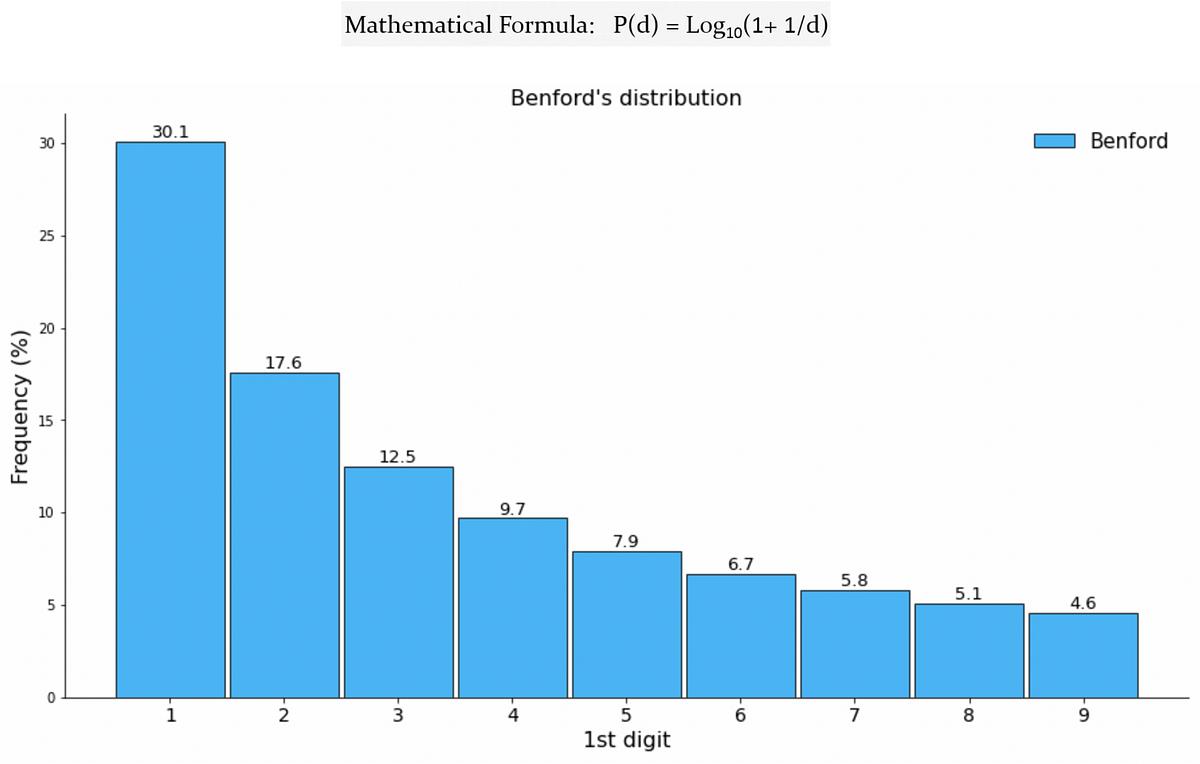
Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタル領域において、ユーザーの真正性は最も重要な懸念事項ですTwitterなどのプラットフォームが成長するにつれ、フェイクアカウントの増加も増えていますこれらのアカウントは本物のアカウントを模倣します
MetaのTwitterライバルアプリ「Threads」に1000万人が登録
Twitterのようなマイクロブログ体験からは、Meta Platformsがプラットフォームに直接挑戦する準備を進めていることが示唆されています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.