Learn more about Search Results TCS

- You may be interested
- AIにおける事実性の向上 このAI研究は、よ...
- 「研究者がドメイン固有の科学チャットボ...
- 「LLaMaTabに会おう:ブラウザ内で完全に...
- 音楽の探索の未来:検索対生成
- 「AIによるPaytmによるインド経済の保護:...
- 「Rust拡張機能でPythonコードを強化する」
- データサイエンスにおけるデータクリーニ...
- データを持っていますか?SMOTEとGANが合...
- 犯罪者が自分たちのChatGPTクローンを作成...
- 「2023年の写真とビデオのための10のAIデ...
- 「AIは医療セキュリティにおいて重要である」
- DeepMindの最新研究(ICLR 2023)
- 「成功したプロンプトの構造の探索」
- 大規模な言語モデルは本当に数学をできる...
- 「Pandas DataFrame内の値を効率的に置換...

「人工知能と気候変動」
「多くの場合、私たちは気候変動に関連付けられた雑誌やニュースの天候エピソードを見たり、聞いたり、読んだりしますが、すべての出来事がこの現象と関連しているわけではありませんたとえば、…」

北京大学とマイクロソフトの研究者がCOLEを紹介:シンプルな意図プロンプトを高品質なグラフィックデザインに変換する効果的な階層生成フレームワーク
最近の品質の顕著な向上により、自然な写真制作はプロの写真と同等になりました。この進歩は、DALL·E3、SDXL、およびImagenなどのテクノロジーの創造に起因します。これらの開発を推進する主要な要素は、強力な大規模言語モデル(LLM)をテキストエンコーダとして使用し、トレーニングデータセットを拡大し、モデルの複雑さを増すこと、より良いサンプリング戦略の設計、およびデータの品質向上です。研究チームは、特にブランディング、マーケティング、広告において重要な機能を持つグラフィックデザインにおいて、よりプロフェッショナルなイメージの開発に焦点を当てる時期だと感じています。 グラフィックデザインは、明確なメッセージを特定の社会グループに伝えるために視覚コミュニケーションの力を利用する専門分野です。それは想像力、独創性、迅速な思考を要求する領域です。グラフィックデザインでは、テキストとビジュアルをデジタルまたはマニュアルの方法で組み合わせて、視覚的に魅力的なストーリーを作成します。その主な目的は、データを整理し、概念に意味を与え、人間の経験を文書化するオブジェクトに表現と感情を提供することです。グラフィックデザインでは、書体の創造的な使用、テキストの配列、装飾、および画像によって、言葉だけでは表現できないアイデア、感情、態度を許容します。一流のデザインを生み出すには、高い想像力、独創性、斬新な思考が必要です。 現在の研究によると、画期的なDALL·E3は、図1で見られるように、魅力的なレイアウトとグラフィックを特徴とする高品質のデザイン画像を生み出す非凡なスキルを持っています。ただし、これらの画像には欠点もあります。彼らの持続的な課題には、しばしばビジュアルテキストが不適切に表示されたり、追加の文字が入ったりするミスレンダリングが含まれます。また、これらの作成された画像は編集できないため、セグメンテーション、消去、およびインペインティングのような複雑な手順が必要です。ユーザーが包括的なテキストプロンプトを提供する要件も重要な制約です。視覚デザインの制作において良いプロンプトを作成するには、高いプロフェッショナルスキルが必要です。 図1: DALL·E3によって作成されたデザイン画像を示すためにDESIGNERINTENTIONを使用しています(GPT-4で増強)。 図2に示すように、DALL·E3とは異なり、彼らのCOLEシステムは基本的な要求だけで優れた品質のグラフィックデザイン画像を生み出すことができます。研究チームによると、これらの3つの制約は、グラフィックデザイン画像の品質を深刻に損なっています。高品質でスケーラブルな視覚デザイン生成システムは、柔軟な編集領域を提供し、さまざまな用途に適した正確で高品質なタイポグラフィック情報を生成し、ユーザーに低い努力を要求する必要があります。ユーザーはさらに結果を向上させるために必要に応じて人間のスキルを使用することができます。この取り組みは、ユーザーの意図プロンプトから優れたグラフィックデザイン画像を生成できる安定かつ効果的な自律型のテキスト-デザインシステムを確立することを目指しています。 図2: COLEシステムによって生成された画像の視覚的な表現が上記に示されています。興味深いことに、システムが受け取る唯一の入力はテキストの意図的な説明です。残りの要素であるテキスト、デザイングラフィック、およびフォントタイプ、サイズ、位置などの関連するタイポグラフィックのプロパティは、すべてインテリジェントシステムによって独立して生成されます。 マイクロソフトリサーチアジアと北京大学の研究チームは、グラフィックデザイン画像の作成プロセスを簡素化するための階層的生成アプローチであるCOLEを提案しています。このプロセスでは、異なるサブタスクに取り組むいくつかの専門的な生成モデルが関与しています。 まず第一に、想像力に重点を置いたデザインと解釈、特に意図の理解に焦点を当てています。これは、最新のLLM、具体的にはLlama2-13Bを使用し、100,000点近くの選り抜かれた意図-JSONペアリングの大規模なデータセットを用いて最適化することによって達成されます。テキストの説明、アイテムのキャプション、背景のキャプションなど、デザインに関連する重要な情報は、JSONファイルに含まれています。研究チームは、オブジェクトの位置などの追加の目的のためにオプションのパラメーターも提供しています。 次に、ビジュアルの配置と改善に焦点を当てており、ビジュアルのコンポーネントの作成とタイポグラフィの特徴の2つのサブタスクが含まれています。さまざまなビジュアルの特徴を作成するには、DeepFloyd/IFなどの特化したカスケード拡散モデルの微調整が必要です。これらのモデルは、レイヤー化されたオブジェクトの画像と装飾された背景などのコンポーネント間のスムーズな移行が保証されるように構築されています。その後、研究チームは、LLaVA-1.5-13Bを使用して構築されたタイポグラフィJSONファイルを予測します。これには、Design LLMからの予測されたJSONファイル、拡散モデルからの予測された背景画像、およびカスケード拡散モデルからの予測されたオブジェクト画像が使用されます。そして、ビジュアルレンダラーが予測されたJSONファイル内で見つかったレイアウトを使用してこれらのコンポーネントを組み立てます。 第三に、プロセスの最後に品質保証とコメントが提供され、デザイン全体の品質を向上させます。反射LLMは丹念に調整する必要があり、包括的かつ多面的な品質評価のためにGPT-4V(ision)を使用する必要があります。この最後の段階では、テキストボックスのサイズや位置など、必要に応じてJSONファイルを微調整することが容易になります。最後に、研究チームは、さまざまなカテゴリにまたがる約200のプロのグラフィックデザイン意図プロンプトと約20のクリエイティブなプロンプトからなるDESIGNERINTENTIONを構築し、システムの能力を評価しました。そして、現在使用されている最先端の画像生成システムとのアプローチの比較、各生成モデルについての抜本的な消去実験、システムによって生成されたグラフィックデザインの徹底的な分析、そしてグラフィックデザイン画像生成の欠点と潜在的な将来の方向についての議論を行いました。

「2024年に注目すべきトップ10のソフトウェアアウトソーシング企業」
2024年のトップ10ソフトウェア委託革新者を探索し、ソフトウェア開発の成長と変革を推進してください

StableSRをご紹介します:事前トレーニング済み拡散モデルの力を活用した新たなAIスーパーレゾリューション手法
コンピュータビジョンの分野では、様々な画像合成タスクのための拡散モデルの開発において、重要な進展が見られています。以前の研究は、Stable Diffusionなどの合成モデルに拡散先行モデルを統合することが、画像や動画の編集などの幅広い下流コンテンツ作成タスクに対して適用可能であることを示しています。 本記事では、コンテンツ作成を超えて、拡散先行モデルを超解像タスクに適用することの潜在的な利点を探求します。超解像は低レベルのビジョンタスクであり、高い画像の忠実度を要求するため、拡散モデルの固有の確率的な性質とは対照的な追加の課題をもたらします。 この課題への一般的な解決策は、スクラッチから超解像モデルをトレーニングすることです。これらの手法では、低解像度(LR)画像を追加の入力として組み込むことで、出力空間を制約し、忠実度を保持することを目指しています。これらのアプローチは優れた結果を達成していますが、拡散モデルのトレーニングにはかなりの計算リソースが必要です。また、ネットワークのトレーニングをゼロから開始することは、合成モデルで捉えられた生成先行モデルを損なう可能性があり、ネットワークのパフォーマンスが最適でない結果になる可能性があります。 これらの制限に対応するために、別のアプローチが検討されています。この代替アプローチでは、事前にトレーニングされた合成モデルの逆拡散プロセスに制約を導入することが含まれます。このパラダイムにより、モデルのトレーニングを繰り返す必要がなくなり、拡散先行モデルの利点を活用することができます。ただし、これらの制約を設計するには、通常は画像の劣化に関する事前知識が必要であり、複雑なものでもあります。そのため、このような手法は一般化が制限されることが示されています。 上記の制限に対処するため、研究者たちはStableSRを導入しました。StableSRは、画像の劣化について明示的な仮定を必要とせずに、事前にトレーニングされた拡散先行モデルを保持するように設計された手法です。以下に、提示された手法の概要が示されています。 従来のアプローチでは、低解像度(LR)画像を中間出力に連結することが必要であり、スクラッチから拡散モデルをトレーニングする必要がありました。一方、StableSRでは、超解像(SR)タスクに特化した軽量のタイムアウェアエンコーダといくつかのフィーチャモジュレーション層の微調整が行われます。 エンコーダには、タイムエンベディングレイヤが組み込まれており、異なるイテレーションで拡散モデル内のフィーチャを適応的に変調するためのタイムアウェアフィーチャを生成します。これにより、トレーニング効率が向上し、生成先行モデルの整合性も維持されます。さらに、タイムアウェアエンコーダは、復元プロセス中に適応的なガイダンスを提供し、初期のイテレーションではより強力なガイダンスを、後のステージではより弱いガイダンスを行い、パフォーマンスの向上に大きく寄与します。 拡散モデルの固有のランダム性とオートエンコーダのエンコードプロセス中の情報損失を解決するために、StableSRでは制御可能なフィーチャラッピングモジュールを適用しています。このモジュールは、調整可能な係数を導入し、エンコーダのマルチスケール中間フィーチャを残差的な方法でデコードプロセス中の拡散モデルの出力を洗練します。調整可能な係数により、忠実度とリアリズムの間の連続的なトレードオフが可能となり、幅広い劣化レベルに対応します。 さらに、任意の解像度の超解像タスクに対して拡散モデルを適応させることは、過去に課題を提起してきました。これを克服するために、StableSRはプログレッシブな集約サンプリング戦略を導入しています。このアプローチでは、画像を重なり合うパッチに分割し、各拡散イテレーションでガウスカーネルを使用してそれらを融合します。その結果、境界部分でより滑らかな遷移が得られ、より一貫した出力が確保されます。 元の記事で提示されたStableSRの一部の出力サンプルと、最先端のアプローチとの比較結果は、以下の図に示されています。 まとめると、StableSRは、実世界の画像超解像の課題に対して生成ベースの事前知識を適応させるためのユニークな解決策を提供します。このアプローチは、劣化について明示的な仮定をすることなく、事前学習済みの拡散モデルを活用し、時間感知エンコーダ、制御可能な特徴ラッピングモジュール、および進行的な集約サンプリング戦略を組み込むことで、忠実度と任意の解像度の問題に対処します。StableSRは堅牢なベースラインとして機能し、拡散事前知識を復元タスクに応用する将来の研究をインスピレーションとして提供します。 興味があり、さらに詳しく知りたい場合は、以下に引用されたリンクを参照してください。

このAI研究論文は、視覚の位置推定とマッピングのための深層学習に関する包括的な調査を提供しています
もし私があなたに「今どこにいるの?」または「周りの様子はどうですか?」と尋ねたら、人間の多感覚知覚という独特な能力のおかげで、あなたはすぐに答えることができるでしょう。この能力により、あなたは自分の動きと周囲の環境を知覚し、完全な空間認識を持つことができます。しかし、同じ質問がロボットに対して投げかけられた場合、どのようにアプローチするでしょうか。 問題は、このロボットが地図を持っていない場合、自分がどこにいるかわからないし、周りの様子も知らなければ地図も作成できないということです。要するに、これは「先に来たのは鶏か卵か?」という問題であり、機械学習の世界ではこの文脈で「位置推定と地図作成の問題」と呼ばれています。 「位置推定」とは、ロボットの動きに関連する内部システム情報を取得する能力であり、位置、方向、速度などが含まれます。一方、「地図作成」とは、周囲の環境条件を知覚する能力であり、周囲の形状、視覚的特徴、意味属性などが含まれます。これらの機能は独立して動作することもあり、一方が内部状態に焦点を当て、他方が外部条件に焦点を当てることもあります。また、同時位置推定と地図作成(SLAM)として知られる単一のシステムとして連携することもあります。 画像ベースの再配置、視覚的オドメトリ、SLAMなどのアルゴリズムには、センサーの測定の不完全さ、動的なシーン、不利な照明条件、現実世界の制約など、実用化を妨げる要素があります。上記の画像は、個々のモジュールが深層学習ベースのSLAMシステムに統合される様子を示しています。この研究では、深層学習ベースのアプローチと従来のアプローチの両方について包括的な調査を行い、次の2つの重要な質問に同時に答えます。 深層学習は、視覚的位置推定と地図作成に有望ですか? 研究者たちは、将来の汎用SLAMシステムにおいて、深層学習が独自の方向性を持つと考えています。以下にリストアップされた3つの特性がその理由です。 第一に、深層学習は、視覚的SLAMフロントエンドに統合される強力な知覚ツールを提供します。これにより、オドメトリ推定や再配置のための難しい領域で特徴を抽出し、地図作成のための密な深度を提供することができます。 第二に、深層学習はロボットに高度な理解力と相互作用能力を与えます。ニューラルネットワークは、マッピングやSLAMシステム内で場面の意味をラベリングするなど、一般的に数学的な方法では説明が難しい抽象概念と人間の理解可能な用語を結びつけることに優れています。 最後に、学習手法により、SLAMシステムや個別の位置推定/地図作成アルゴリズムが経験から学び、新しい情報を積極的に活用することができます。 深層学習は、視覚的位置推定と地図作成の問題を解決するためにどのように適用されるのでしょうか? 深層学習は、SLAMのさまざまな側面をモデリングするための多目的なツールです。たとえば、画像から姿勢を直接推定するエンドツーエンドのニューラルネットワークモデルを作成するために使用することができます。これは、特徴のない領域、動的な照明、モーションブラーなどの厳しい条件を扱う際に特に有益です。 深層学習は、SLAMの関連付け問題を解決するために使用されます。画像を地図に接続し、ピクセルに意味を付け、以前の訪問時の関連シーンを認識することで、再配置、意味マッピング、ループクロージャ検出を支援します。 深層学習は、興味のあるタスクに関連する特徴を自動的に発見するために活用されます。例えば、幾何学的制約などの先行知識を利用することで、SLAMのための自己学習フレームワークが構築され、入力画像に基づいてパラメータを自動的に更新することができます。 深層学習技術は、意味のあるパターンを抽出するために大規模かつ正確にラベル付けされたデータセットに依存しますが、不慣れな環境に対して一般化することが困難な場合があります。これらのモデルは解釈可能性に欠けており、しばしばブラックボックスとして機能します。また、位置推定と地図作成システムは計算量が多く、高度に並列化可能ですが、モデルの圧縮技術が適用されていない限り、計算負荷が高くなる場合があります。
「OpenAIのWebクローラーとFTCのミスステップ」
「OpenAIは、デフォルトでオプトイン型のクローラーを起動してインターネットをスクレイピングする一方で、FTCは不明瞭な消費者の欺瞞調査を追求しています」

新しい研究によって、テキストをスムーズに音声化することができるようになりました | Google
テキスト音声(マルチモーダルモデル)のトレーニングには独自の問題がありますオーディオサンプルレートが高い場合、オーディオのシーケンス長は対応するテキストよりもはるかに長くなりますテキストと…

「Googleのトレイルブレイザーのインスピレーションに満ちた旅」
はじめに 技術の巨人たちの絶え間なく進化する世界で、勝利と達成の物語はしばしば現れ、大きな夢を抱き、献身的に働いて目標を達成した個人の驚くべき旅を示しています。そのような物語の中心には、Googleの副主任である方がいます。彼のインスピレーションに満ちた成功ストーリーは、テック業界が提供する献身、革新、そして無限の可能性を証明しています。本記事では、Googleの開拓者であり、謙虚な出自から重要な存在となり、その貢献が彼らのキャリアだけでなく、テクノロジーの世界やそれを超えても不可欠なものとなったMr. Mani Garlapatiの驚くべき旅について探求します。 AV: Googleの副主任としての現在のポジションに至るまでの学歴について教えていただけますか? Mr. Mani: 私はBITS Pilaniでテックファイナンスの統合修士号と学士号を取得し、テクノロジーとファイナンスの堅固な基礎を築きました。その後、テクノロジー業界での後続の役割で優れた成果を上げることができたので、これが役に立ったと考えられます。 JP Morgan Chase、Mu Sigma、TCS Innovation Labs、WalmartLabsでの経験により、銀行業界、IoT、テレマティクス、テキストマイニング、ソーシャルメディア分析、ウェブ分析、NLP、価格設定、サプライチェーン、グローバルソーシング、人事分析など、さまざまな領域で専門知識を得ることができました。 これらの多様な経験により、問題解決能力、分析能力、チームでの働き方、異なる環境への適応能力が磨かれたと考えられます。 私の現在のGoogleでの役割は、技術領域での大規模な不正行為および詐欺検出に関連するプロジェクトの監督と管理を担当しています。以前のさまざまな領域での経験は、この役割の複雑さに対処し、チームの成功に貢献するために必要なスキルを身につけることができました。 全体として、私の学歴と職業経験は、Googleの副主任としての私の成功に貢献し、テクノロジー業界におけるキャリアパスを形作り続けています。 成長のまとめ 私はテクノロジーとファイナンスの分野で成功する決意を持っていました。私はBITS Pilaniに通い、テックファイナンスの統合修士号と学士号を5年間で取得しました。 卒業後、JP Morgan…

「現代の自然言語処理:詳細な概要パート3:BERT」
「トランスフォーマーとGPTについての以前の記事では、NLPのタイムラインと開発の体系的な分析を行ってきましたシーケンス対シーケンスモデリングからドメインがどのように進化したかを見てきました...」
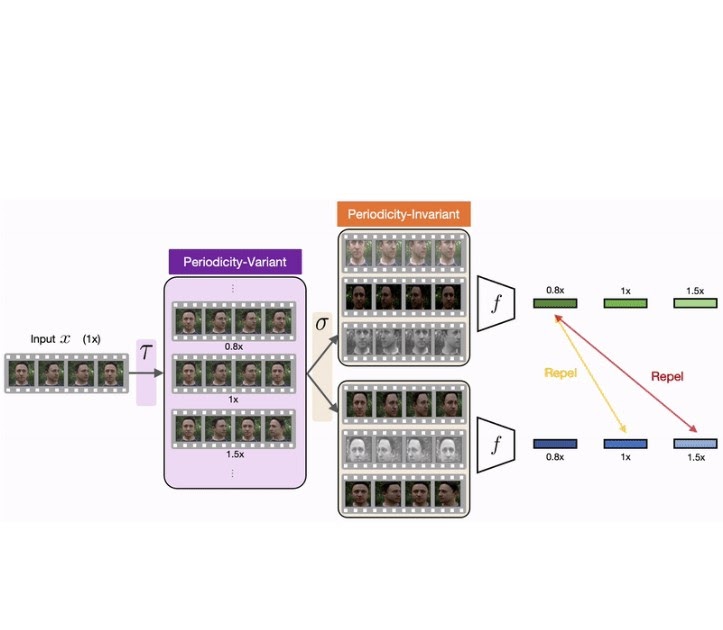
SimPer:周期的なターゲットの簡単な自己教示学習
Googleのスタッフ研究者であるDaniel McDuffと学生研究者のYuzhe Yangによって投稿されました。 周期的なデータ(心拍や地球表面の日々の気温変化など、繰り返される信号)から学ぶことは、天候システムの監視から生体徴候の検出まで、多くの実世界のアプリケーションにとって重要です。例えば、環境遠隔検出の領域では、降水パターンや地表温度などの環境変化のナウキャスティングを可能にするために周期的な学習がしばしば必要です。健康領域では、ビデオ測定から学んだ結果、心房細動や睡眠時無呼吸などの(準)周期的な生体徴候を抽出することが示されています。 RepNetなどのアプローチは、これらのタスクの重要性を強調し、単一のビデオ内で繰り返されるアクティビティを認識する解決策を提供しています。ただし、これらは教師ありのアプローチであり、繰り返されるアクティビティを捉えるために大量のデータと、アクションが繰り返された回数を示すラベルが必要です。このようなデータのラベリングは、しばしば難しくリソースを消費するため、研究者は興味の対象のモダリティ(ビデオや衛星画像など)と同期したゴールドスタンダードの時間的計測を手動でキャプチャする必要があります。 代わりに、自己教師あり学習(SSL)の手法(SimCLRやMoCo v2など)は、周期的または準周期的な時間的ダイナミクスを捉える表現を学習するためにラベルの付いていない大量のデータを活用することで、分類タスクの解決に成功しています。しかし、これらの手法は、データの固有の周期性(つまり、フレームが周期的なプロセスの一部であるかどうかを識別する能力)を見落とし、周期的な属性や周波数属性を捉える堅牢な表現を学習することができません。これは、周期的な学習が一般的な学習タスクとは異なる特性を持つためです。 周期的表現の文脈での特徴の類似性は、静的な特徴(例えば画像)とは異なります。例えば、短い時間遅れでオフセットされたビデオや反転されたビデオは、元のサンプルと類似しているべきです。一方、ビデオのアップサンプリングやダウンサンプリングは、元のサンプルから因子xで異なるはずです。 これらの課題に対処するために、私たちは「SimPer: Simple Self-Supervised Learning of Periodic Targets」という論文で、データ内の周期的な情報を学習するための自己教師ありの対照的なフレームワークを紹介しました。具体的には、SimPerは周期性不変および周期性変動の拡張によって、同じ入力インスタンスから正例と負例のサンプルを取得することで、周期性のあるターゲットの時間的特性を活用します。周期的な特徴の類似性を提案し、周期的な学習の文脈で類似性を測定する方法を明示的に定義します。さらに、古典的なInfoNCE損失をソフト回帰バリアントに拡張した汎用の対照的な損失を設計し、連続したラベル(周波数)を対照することを可能にします。次に、SimPerが最新のSSL手法と比較して効果的に周期的な特徴表現を学習することを示し、データの効率性、誤った相関に対する堅牢性、分布のシフトに対する一般化能力など、その興味深い特性を強調します。最後に、私たちはSimPerのコードリポジトリを研究コミュニティと共有することを楽しみにしています。 SimPerフレームワーク SimPerは、時間的な自己対照的学習フレームワークを導入します。正例と負例のサンプルは、周期性不変および周期性変動の拡張によって同じ入力インスタンスから取得されます。時間的なビデオの例では、周期性不変の変更にはトリミング、回転、反転があり、周期性変動の変更にはビデオの速度の増減が含まれます。 周期的な学習の文脈で類似性を測定する方法を明示的に定義するために、SimPerは周期的な特徴の類似性を提案します。この構成により、トレーニングを対照的な学習タスクとして定式化することができます。モデルはラベルのないデータでトレーニングされ、必要に応じて学習された特徴を特定の周波数値にマッピングするために微調整されることができます。 入力シーケンスxが与えられた場合、関連する周期的な信号が存在することがわかります。そして、xを変換して速度や周波数が変化したサンプルのシリーズを作成し、基になる周期的なターゲットを変更し、異なる負のビューを作成します。元の周波数は不明ですが、ラベルのない入力xに対して擬似的な速度や周波数のラベルを効果的に考案します。 従来の類似性尺度(例:コサイン類似度)は、2つの特徴ベクトル間の厳密な近接性を強調し、インデックスがシフトした特徴(異なるタイムスタンプを表す)、逆転した特徴、および周波数が変化した特徴に対して敏感です。一方、周期的な特徴類似性は、時間的なシフトが小さく、または逆転したインデックスがあるサンプルに対して高くなるべきであり、特徴の周波数が変化する際に連続的な類似性の変化を捉えるべきです。これは、フーリエ変換間の距離など、周波数領域の類似度尺度によって実現できます。 周波数領域で増強されたサンプルの固有の連続性を活用するために、SimPerは一般化された対照的損失を設計します。この損失は、古典的なInfoNCE損失をソフト回帰のバリアントに拡張し、連続的なラベル(周波数)に対して対比を可能にします。これにより、心拍などの連続信号を回復するという回帰タスクに適しています。 SimPerは、周波数領域でデータのネガティブビューを構築することによって、データの変換を行います。入力シーケンスxには、関連する周期的な信号があります。SimPerは、xを変換して速度や周波数が変化したサンプルのシリーズを作成します。これにより、基礎となる周期的なターゲットが変わり、異なるネガティブビューが作成されます。元の周波数は不明ですが、未ラベルの入力xに対して疑似的な速度や周波数ラベル(周期性変数の増強τ)を効果的に設計します。SimPerは、入力の識別を変更しない変換を取り、これらを周期性に関して不変な増強σと定義し、サンプルの異なるポジティブビューを作成します。そして、これらの増強ビューをエンコーダfに送り、対応する特徴を抽出します。 結果 SimPerの性能を評価するために、人間の行動分析、環境リモートセンシング、および医療の共通の実世界タスクに対して、SimPerを最新のSSLスキーム(例:SimCLR、MoCo…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.