Learn more about Search Results Replicate

- You may be interested
- ToolQAとは 外部ツールを使用した質問応答...
- ETHチューリッヒの研究者が、バイオミメテ...
- 「PandasAIを使用してデータを自動的に探...
- 「大規模な言語モデルの探索-パート3」
- 「ジュリアプログラミング言語の探求:統...
- 人工知能(AI)エージェント進化のフロン...
- 「SOCKS5プロキシ vs HTTPプロキシ どちら...
- 「DeepMindがデスクトップコンピュータ上...
- 新しい価格設定をご紹介します
- アデプトAIはFuyu-8Bをオープンソース化し...
- 「Python タイムスタンプ:初心者のための...
- ディープラーニングによる触媒性能の秘密...
- (Note Since HTML is a markup language, ...
- 「EU AI法案:AIの未来における有望な一歩...
- 商品化されたサービス101:フリーランサー...

「NVIDIAがゲームチェンジャーとマーケットメーカーへの投資でAI革命を推進する方法」
偉大な企業は物語によって繁栄します。NVIDIAのベンチャーキャピタル担当であるシド・サイディックは、これをよく知っています。 サイディックは、最初の仕事のひとつで、投資家のミーティングからプレゼン資料を運び回り、トレーラーでの仕事中に、ドアが開くと「揺れる」トレーラーで、スタートアップのCEOとマネジメントチームが物語を伝えるのを手伝いました。 そのCEOはJensen Huangであり、スタートアップはNVIDIAでした。 サイディックは、投資家と起業家として働いた経験から、顧客やパートナー、従業員や投資家など、会社の物語を早い段階で共有するために適切な人々を見つけることがどれほど重要かを知っています。 この原則こそが、NVIDIAが次世代イノベーションを支援するために取り組んでいる多面的なアプローチの基盤です。この戦略は、NVIDIAの企業開発責任者であるヴィシャル・バグワティも支持しています。 この取り組みは、今年に入ってこれまでに2ダース以上の投資を果たしました。AIと加速コンピューティングのイノベーションのペースが加速するにつれ、さらに加速しています。 AIエコシステムを支援するNVIDIAの三本の戦略 NVIDIAがエコシステムを投資する方法は3つあります。まず、バグワティが監督するNVIDIAの企業投資によるもの。次に、サイディックが率いる私たちのベンチャーキャピタル部門であるNVenturesによるもの。そして最後に、ベンチャーキャピタルとスタートアップを結び付ける私たちのNVIDIA Inceptionです。 PwCによれば、AIだけで2030年までに世界経済に15兆ドル以上の寄与ができる可能性があります。したがって、現在AIと加速コンピューティングに取り組んでいる場合、NVIDIAは手助けする準備ができています。あらゆる業界の開発者が加速コンピューティングアプリケーションを作成しています。そして、まだ始まったばかりです。 その結果、AIの物語を日々進化させている企業のコレクションが生まれました。Cohere、CoreWeave、Hugging Face、Inflection、Inceptiveなどが含まれます。私たちは彼らと一緒にいます。 「NVIDIAと提携することはゲームチェンジャーです」とMachina LabsのCEOであるEd Mehrは言いました。 「彼らの類まれな専門知識が、私たちのAIとシミュレーション能力を飛躍的に向上させます」。 企業投資:エコシステムの成長 NVIDIAの企業投資部門は戦略的な協力に焦点を当てています。これらのパートナーシップは共同イノベーションを促進し、NVIDIAプラットフォームを強化し、エコシステムを拡大します。2023年の始め以来、14件の投資に関する発表が行われています。 これらのターゲット企業には、チップ間の光接続に特化したAyar Labsや、先進的なAIモデルのハブであるHugging Faceなどがあります。 ポートフォリオには、次世代のエンタープライズソリューションも含まれています。Databricksは、機械学習のための業界をリードするデータプラットフォームを提供しており、CohereはAIを通じた企業自動化を提供しています。他の注目すべき企業にはRecursion、Kore.ai、Utilidataなどがあり、それぞれが薬物発見、会話型AI、スマート電力グリッドのユニークなソリューションを提供しています。 消費者サービスも投資の焦点です。Inflectionは、クリエイティブ表現のためのパーソナルAIを作り上げており、Runwayは生成AIを通じたアートと創造性のプラットフォームとして機能しています。…

「デベロッパー用の15以上のAIツール(2023年12月)」
“`html GitHub Copilot GitHub Copilotは、市場をリードするAIによるコーディングアシスタントです。開発者が効率的に優れたコードを作成できるように設計され、CopilotはOpenAIのCodex言語モデルを基に動作します。このモデルは自然言語と公開コードの広範なデータベースの両方でトレーニングされており、洞察に満ちた提案を行うことができます。コードの行や関数を完全に補完するだけでなく、コメント作成やデバッグ、セキュリティチェックの支援など、開発者にとって大変貴重なツールとなっています。 Amazon CodeWhisperer AmazonのCodeWhispererは、Visual StudioやAWS Cloud9などのさまざまなIDEでリアルタイムのコーディング推奨事項を提供する、機械学習に基づくコード生成ツールです。大規模なオープンソースコードのデータセットでトレーニングされており、スニペットから完全な関数までを提案し、繰り返しのタスクを自動化し、コードの品質を向上させます。効率とセキュリティを求める開発者にとって大変便利です。 Notion AI Notionのワークスペース内で、AIアシスタントのNotionがさまざまな執筆関連のタスクをサポートします。創造性、改訂、要約などの作業を助け、メール、求人募集、ブログ投稿などの作成をスピードアップさせます。Notion AIは、ブログやリストからブレストセッションや創造的な執筆まで、幅広い執筆タスクの自動化に使用できるAIシステムです。NotionのAI生成コンテンツは、ドラッグアンドドロップのテキストエディタを使用して簡単に再構成や変換ができます。 Stepsize AI Stepsize AIは、チームの生産性を最適化するための協力ツールです。プロジェクトの履歴管理やタスク管理の役割を果たし、Slack、Jira、GitHubなどのプラットフォームと統合して更新を効率化し、コミュニケーションのミスを防ぎます。主な機能には、活動の統一した概要、質問への即時回答、堅牢なデータプライバシーコントロールが含まれます。 Mintlify Mintlifyは、お気に入りのコードエディタで直接コードのドキュメントを自動生成する時間の節約ツールです。Mintlify Writerをクリックするだけで、関数のための良く構造化された、コンテキストに即した説明を作成します。開発者やチームにとって理想的であり、複雑な関数の正確なドキュメントを生成することで効率と正確性が高く評価されています。 Pieces for Developers…

「OpenAIモデルに対するオープンソースの代替手段の探索」
序文 AIの領域では、11月はドラマチックな展開がありました。GPTストアやGPT-4-turboのローンチ、そしてOpenAIの騒動まで、まさに忙しい一ヶ月でした。しかし、ここで重要な問題が浮かび上がります:クローズドモデルとその背後にいる人々はどれだけ信頼できるのでしょうか?自分が実際に運用しているモデルが内部の企業ドラマに巻き込まれて動作停止するのは快適な体験とは言えません。これはオープンソースモデルでは起こらない問題です。展開するモデルには完全な管理権限があります。データとモデルの両方に対して主権を持っています。しかし、OSモデルをGPTと置き換えることは可能でしょうか?幸いなことに、既に多くのオープンソースモデルが、GPT-3.5モデル以上の性能を発揮しています。本記事では、オープンソースのLLM(Large Language Models)およびLMM(Large Multi-modal Models)の最高の代替品をいくつか紹介します。 学習目標 オープンソースの大規模言語モデルについての議論。 最新のオープンソース言語モデルとマルチモーダルモデルについての探求。 大規模言語モデルを量子化するための簡易な導入。 LLMをローカルおよびクラウド上で実行するためのツールやサービスについて学ぶ。 この記事は、データサイエンスブログマラソンの一環として公開されました。 オープンソースモデルとは何ですか モデルがオープンソースと呼ばれるのは、モデルの重みとアーキテクチャが自由に利用できる状態にあるからです。これらの重みは、例えばMeta’s Llamaのような大規模言語モデルの事前訓練パラメータです。これらは通常、ファインチューニングされていないベースモデルやバニラモデルです。誰でもこれらのモデルを使用し、カスタムデータでファインチューニングして下流のアクションを実行することができます。 しかし、それらはオープンなのでしょうか?データはどうなっているのでしょうか?多くの研究所は、著作権に関する懸念やデータの機密性の問題などの理由から、ベースモデルの訓練データを公開しません。これはまた、モデルのライセンスに関する部分にも関連しています。すべてのオープンソースモデルは、他のオープンソースソフトウェアと同様のライセンスが付属しています。Llama-1などの多くのベースモデルは非商用ライセンスとなっており、これらのモデルを利用して収益を上げることはできません。しかし、Mistral7BやZephyr7Bなどのモデルは、Apache-2.0やMITライセンスが付属しており、どこでも問題なく使用することができます。 オープンソースの代替品 Llamaのローンチ以来、オープンソースの領域ではOpenAIモデルに追いつこうとする競争が繰り広げられています。そしてその結果は今までにないものでした。GPT-3.5のローンチからわずか1年で、より少ないパラメータでGPT-3.5と同等またはそれ以上のパフォーマンスを発揮するモデルが登場しました。しかし、GPT-4は依然として理性や数学からコード生成までの一般的なタスクには最も優れたモデルです。オープンソースモデルのイノベーションと資金調達のペースを見ると、GPT-4のパフォーマンスに近づくモデルが間もなく登場するでしょう。とりあえず、これらのモデルの素晴らしいオープンソースの代替品について話しましょう。 Meta’s Llama 2 Metaは今年7月にLlama-2という彼らの最高のモデルをリリースし、その印象的な能力により一瞬で人気を集めました。MetaはLlama-7b、Llama-13b、Llama-34b、Llama-70bの4つの異なるパラメータサイズのLlama-2モデルをリリースしました。これらのモデルは、それぞれのカテゴリにおいて他のオープンモデルを上回る性能を発揮しました。しかし、現在ではmistral-7bやZephyr-7bのような複数のモデルが、多くのベンチマークで小さなLlamaモデルを上回る性能を発揮しています。Llama-2 70bはまだそのカテゴリーで最高のモデルの一つであり、要約や機械翻訳などのタスクにおいてGPT-4の代替モデルとして価値があります。 Llama-2はGPT-3.5よりも多くのベンチマークで優れたパフォーマンスを発揮し、GPT-4に迫ることもできました。以下のグラフは、AnyscaleによるLlamaとGPTモデルのパフォーマンス比較です。…

「LoRAを使用してAmazon SageMakerでWhisperモデルを微調整する」
「ウィスパーは、ウェブ上の言語とタスクの幅広いデータを使用してトレーニングされた、自動音声認識(ASR)モデルですしかし、マラーティー語やドラヴィダ語などの資源の少ない言語においては、性能が低下するという制約がありますこの制約は、ファインチューニングによって解消できますしかし、ウィスパーのファインチューニング […]」

ハスデックスとステーブルディフュージョン:2つのAI画像生成モデルを比較
「HasdxとStable Diffusionは、さまざまなユースケース、コスト、機能などを考慮して、最高のテキストから画像への変換モデルの一部として、どのように優れているのか」

チャットアプリのLLMを比較する:LLaMA v2チャット対Vicuna
チャットアプリケーションにおいて、LLaMA v2 ChatとVicunaのどちらを使用するべきですか?2つのLLMの詳細な比較、それぞれの利点と欠点、そして勝者を選ぶためのヒューリスティックについて詳しく解説します

「🧨 JAXを使用したCloud TPU v5eでの高速で安定したXL推論の拡散を加速する」
生成AIモデルであるStable Diffusion XL(SDXL)などは、幅広い応用において高品質でリアルなコンテンツの作成を可能にします。しかし、このようなモデルの力を利用するには、大きな課題や計算コストが伴います。SDXLは、そのUNetコンポーネントがモデルの以前のバージョンのものよりも約3倍大きい大きな画像生成モデルです。このようなモデルを実稼働環境に展開することは、増加したメモリ要件や推論時間の増加などの理由から難しいです。今日、私たちはHugging Face DiffusersがJAX on Cloud TPUsを使用してSDXLをサポートすることを発表できることを大いに喜んでいます。これにより、高性能でコスト効率の良い推論が可能になります。 Google Cloud TPUsは、大規模なAIモデルのトレーニングや推論を含む、最先端のLLMsや生成AIモデルなどのために最適化されたカスタムデザインのAIアクセラレータです。新しいCloud TPU v5eは、大規模AIトレーニングや推論に必要なコスト効率とパフォーマンスを提供するよう特別に設計されています。TPU v4の半分以下のコストで、より多くの組織がAIモデルのトレーニングと展開が可能になります。 🧨 Diffusers JAX連携は、XLAを介してTPU上でSDXLを実行する便利な方法を提供します。それに対応するデモも作成しました。このデモは、時間のかかる書式変換や通信時間、フロントエンド処理を含めて約4秒で4つの大きな1024×1024の画像を提供するために複数のTPU v5e-4インスタンス(各インスタンスに4つのTPUチップがあります)で実行されます。実際の生成時間は2.3秒です。以下で詳しく見ていきましょう! このブログ記事では、 なぜJAX + TPU + DiffusersはSDXLを実行するための強力なフレームワークなのかを説明します。…

「推論APIを使用してAIコミックファクトリーを展開する」
最近、私たちは「PROsのための推論」という新しいオファリングを発表しました。これにより、より広範なユーザーがより大規模なモデルを利用することが可能になります。この機会が、Hugging Faceをプラットフォームとして使用してエンドユーザーアプリケーションを実行する新たな可能性をもたらします。 そのようなアプリケーションの例としては、「AIコミック工場」があります。これは非常に人気があります。数千人のユーザーがAIコミックパネルを作成するために試しており、独自のコミュニティも形成されています。彼らは自分の作品を共有し、いくつかはプルリクエストを公開しています。 このチュートリアルでは、AIコミック工場をフォークして設定し、長い待ち時間を避け、推論APIを使用して独自のプライベートスペースに展開する方法を紹介します。高い技術的スキルは必要ありませんが、API、環境変数の知識、そしてLLMsとStable Diffusionの一般的な理解が推奨されます。 はじめに まず、PRO Hugging Faceアカウントにサインアップして、Llama-2とSDXLモデルへのアクセス権を取得する必要があります。 AIコミック工場の仕組み AIコミック工場は、Hugging Face上で実行される他のスペースとは少し異なります。それはNextJSアプリケーションで、Dockerを使用して展開され、クライアント-サーバーアプローチに基づいています。2つのAPIが必要です: 言語モデルAPI(現在はLlama-2) Stable Diffusion API(現在はSDXL 1.0) スペースの複製 AIコミック工場を複製するには、スペースに移動し、「複製」をクリックします: スペースの所有者、名前、可視性がすでに入力されていることに気付くでしょう。そのままで構いません。 スペースのコピーは、リソースを多く必要としないDockerコンテナ内で実行されますので、最小のインスタンスを使用できます。公式のAIコミック工場スペースは、多くのユーザーベースを対象としているため、より大きなCPUインスタンスを使用しています。 AIコミック工場を自分のアカウントで操作するには、Hugging Faceトークンを設定する必要があります: LLMとSDエンジンの選択…

「チャットモデル対決:GPT-4 vs. GPT-3.5 vs. LLaMA-2によるシミュレートされた討論会-パート1」
最近、MetaがGPT-4と競合するチャットモデルを開発する計画を発表し、AnthropicがClaude2を発売したことにより、どのモデルが最も優れているかについての議論がますます激化しています...
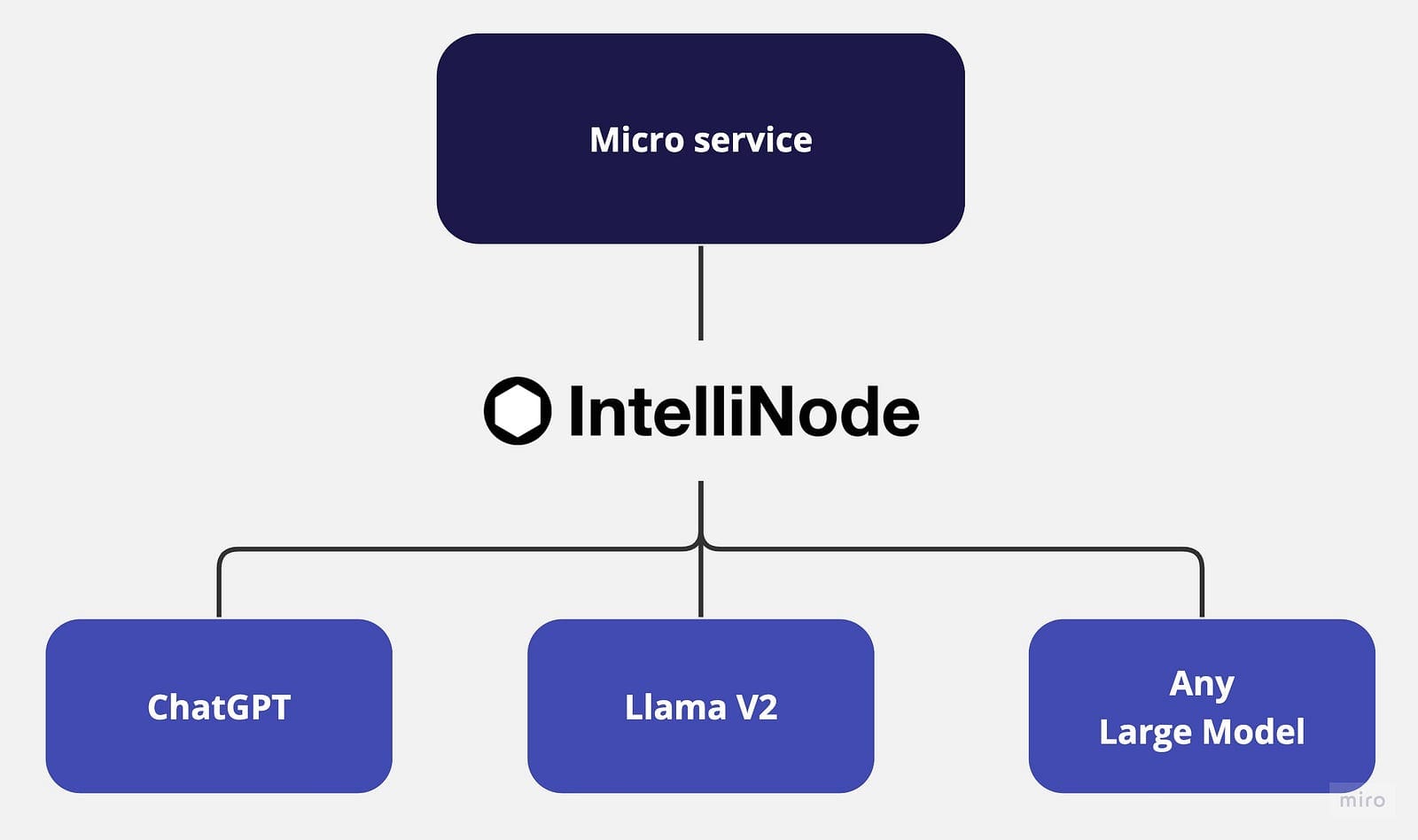
ラマとChatGPTを使用してマルチチャットバックエンドのマイクロサービスを構築する
LLM(Language Model)が進化し続けるにつれて、複数のモデルを統合したり、それらを切り替えることはますます困難になっていますこの記事では、モデルの統合をビジネスアプリケーションから分離し、プロセスを単純化するために、マイクロサービスアプローチを提案しています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.