Learn more about Search Results PEGASUS

- You may be interested
- 「データセットに欠損値がありますか?何...
- Scikit-Learn vs TensorFlow どちらを選ぶ...
- 現代の時代において、信頼性のある量子コ...
- 「3Dディスプレイがデジタル世界にタッチ...
- ライトオンAIは、Falcon-40Bをベースにし...
- 「太陽エネルギーが新たな展開を迎える」
- TensorFlowとXLAを使用した高速なテキスト...
- 「AIが研究論文内の問題のある画像を見つ...
- 『ChatGPTや他のチャットボットの安全コン...
- 数千の著者がAI企業に対し、無断での作品...
- 「アナコンダのCEO兼共同創業者、ピーター...
- Pythonで美しく(かつ有用な)スパゲッテ...
- 「データ注釈は機械学習の成功において不...
- 複雑なタスクの実行におけるロボットの強...
- 「深層学習を用いた深層オブジェクト:Zoe...

言語モデルを使用したドキュメントの自動要約のテクニック
要約は、大量の情報をコンパクトで意味のある形式に短縮する技術であり、情報豊かな時代における効果的なコミュニケーションの基盤となっていますデータの溢れる世界で、長いテキストを短い要約にまとめることで時間を節約し、的確な意思決定を支援します要約は内容を短縮して提示することにより、時間を節約し、明確さを向上させる役割を果たします

「生成AIにおける高度なエンコーダとデコーダの力」
はじめに 人工知能のダイナミックな領域では、技術と創造性の融合が人間の想像力の限界を押し上げる革新的なツールを生み出しています。この先駆的な進歩の中には、生成型AIにおけるエンコーダーとデコーダーの洗練された世界が存在します。この進化は、芸術、言語、さらには現実との関わり方を根本的に変革します。 出典 – IMerit 学習目標 生成型AIにおけるエンコーダーとデコーダーの役割と創造的なアプリケーションへの重要性を理解する。 BERT、GPT、VAE、LSTM、CNNなどの高度なAIモデルと、データのエンコードとデコードにおける実践的な使用方法を学ぶ。 エンコーダーとデコーダーのリアルタイムアプリケーションをさまざまな分野で探求する。 AIによって生成されたコンテンツの倫理的な考慮と責任ある使用についての洞察を得る。 高度なエンコーダーとデコーダーを応用することによって創造的な協力とイノベーションのポテンシャルを認識する。 この記事はData Science Blogathonの一環として公開されました。 エンコーダーとデコーダーの台頭 テクノロジーの絶え間ない進化の中で、エンコーダーとデコーダーは人工知能(AI)と生成型AIにクリエイティブな転機をもたらしています。それらはAIが芸術、テキスト、音声などを理解し、解釈し、創造するために使用する魔法の杖のような存在です。 ここがポイントです:エンコーダーは非常に注意深い探偵のようなものです。画像、文章、音声など、様々な物事を詳細に分析します。さまざまな小さな詳細やパターンを探し、クルーを組み立てる探偵のような役割を果たします。 一方、デコーダーはクリエイティブな魔術師のような存在です。エンコーダーが見つけた情報を新たでドキドキするものへと変えます。それは魔術師が魔法の呪文に変え、芸術、詩、さらには別の言語まで作り出すようなものです。エンコーダーとデコーダーの組み合わせは、創造的な可能性の扉を開きます。 <p p="" 簡単に言えば、aiのエンコーダーとデコーダーは、探偵と魔術師が共同で働いているようなものです。探偵が世界を理解し、魔術師がその理解を素晴らしい創造物に変えます。これが芸術、言語、さらには他の様々な分野でゲームを変えつつある方法で、技術が革新的でありながらも卓越した創造性を備えていることを示しています。 構成要素:エンコーダーとデコーダー 生成型AIの核心には、データを一つの形式から別の形式に変換するエンコーダーとデコーダーという基本的な構成要素があり、これが創造的AIの核心となります。彼らの役割を理解することで、彼らが解き放つ膨大な創造力の可能性を把握する助けになります。 エンコーダー:…

「ドメイン特化LLMの潜在能力の解放」
イントロダクション 大規模言語モデル(LLM)は世界を変えました。特にAIコミュニティにおいて、これは大きな進歩です。テキストを理解し、返信することができるシステムを構築することは、数年前には考えられなかったことでした。しかし、これらの機能は深さの欠如と引き換えに得られます。一般的なLLMは何でも屋ですが、どれも専門家ではありません。深さと精度が必要な領域では、幻覚のような欠陥は高価なものになる可能性があります。それは医学、金融、エンジニアリング、法律などのような領域がLLMの恩恵を受けることができないことを意味するのでしょうか?専門家たちは、既に同じ自己教師あり学習とRLHFという基礎的な技術を活用した、これらの領域に特化したLLMの構築を始めています。この記事では、領域特化のLLMとその能力について、より良い結果を生み出すことを探求します。 学習目標 技術的な詳細に入る前に、この記事の学習目標を概説しましょう: 大規模言語モデル(LLM)とその強みと利点について学びます。 一般的なLLMの制限についてさらに詳しく知ります。 領域特化のLLMとは何か、一般的なLLMの制限を解決するためにどのように役立つのかを見つけます。 法律、コード補完、金融、バイオ医学などの分野におけるパフォーマンスにおけるその利点を示すためのさまざまな領域特化言語モデルの構築について、例を交えて探求します。 この記事はData Science Blogathonの一部として公開されました。 LLMとは何ですか? 大規模言語モデル(LLM)とは、数億から数十億のパラメータを持つ人工知能システムであり、テキストを理解し生成するために構築されます。トレーニングでは、モデルにインターネットのテキスト、書籍、記事、ウェブサイトなどからの多数の文を提示し、マスクされた単語または文の続きを予測するように教えます。これにより、モデルはトレーニングされたテキストの統計パターンと言語的関係を学びます。LLMは、言語翻訳、テキスト要約、質問応答、コンテンツ生成など、さまざまなタスクに使用することができます。トランスフォーマーの発明以来、無数のLLMが構築され、公開されてきました。最近人気のあるLLMの例には、Chat GPT、GPT-4、LLAMA、およびStanford Alpacaなどがあり、画期的なパフォーマンスを達成しています。 LLMの強み LLMは、言語理解、エンティティ認識、言語生成の問題など、言語に関するさまざまな課題のためのソリューションとして選ばれるようになりました。GLUE、Super GLUE、SQuAD、BIGベンチマークなどの標準的な評価データセットでの優れたパフォーマンスは、この成果を反映しています。BERT、T5、GPT-3、PALM、GPT-4などが公開された時、それらはすべてこれらの標準テストで最新の結果を示しました。GPT-4は、BARやSATのスコアで平均的な人間よりも高得点を獲得しました。以下の図1は、大規模言語モデルの登場以来、GLUEベンチマークでの大幅な改善を示しています。 大規模言語モデルのもう一つの大きな利点は、改良された多言語対応の能力です。たとえば、104の言語でトレーニングされたマルチリンガルBERTモデルは、さまざまな言語で優れたゼロショットおよびフューショットの結果を示しています。さらに、LLMの活用コストは比較的低くなっています。プロンプトデザインやプロンプトチューニングなどの低コストの方法が登場し、エンジニアはわずかなコストで既存のLLMを簡単に活用することができます。そのため、大規模言語モデルは、言語理解、エンティティ認識、翻訳などの言語に基づくタスクにおけるデフォルトの選択肢となっています。 一般的なLLMの制限 Web、書籍、Wikipediaなどからのさまざまなテキストリソースでトレーニングされた上記のような一般的なLLMは、一般的なLLMと呼ばれています。これらのLLMには、Bing ChatのGPT-4、PALMのBARDなどの検索アシスタント、マーケティングメール、マーケティングコンテンツ、セールスピッチなどのコンテンツ生成タスク、個人チャットボット、カスタマーサービスチャットボットなど、さまざまなアプリケーションがあります。 一般的なAIモデルは、さまざまなトピックにわたるテキストの理解と生成において優れたスキルを示していますが、専門分野にはさらなる深さとニュアンスが必要な場合があります。たとえば、「債券」とは金融業界での借入の形態ですが、一般的な言語モデルはこの独特なフレーズを理解せず、化学や人間同士の債券と混同してしまうかもしれません。一方、領域特化のLLMは、特定のユースケースに関連する専門用語を専門的に理解し、業界固有のアイデアを適切に解釈する能力があります。 また、一般的なLLMには複数のプライバシーの課題があります。たとえば、医療LLMの場合、患者データは非常に重要であり、一般的なLLMに機械学習強化学習(RLHF)などの技術が使用されることで、機密データの公開がプライバシー契約に違反する可能性があります。一方、特定のドメインに特化したLLMは、データの漏洩を防ぐために閉じたフレームワークを確保します。…

「Amazon SageMakerを使用したヘルスケアの要約オプションの探索」
現在の急速に進化する医療の現場では、医師は介護者のメモ、電子健康記録、画像報告書など、さまざまな情報源から大量の臨床データに直面しています患者のケアには不可欠なこの情報の富は、医療専門家にとっても圧倒的で時間のかかるものになります効率的に要約し、抽出することは、

「トランスフォーマーベースのエンコーダーデコーダーモデル」
!pip install transformers==4.2.1 !pip install sentencepiece==0.1.95 トランスフォーマーベースのエンコーダーデコーダーモデルは、Vaswani et al.によって有名なAttention is all you need論文で紹介され、現在では自然言語処理(NLP)におけるデファクトスタンダードのエンコーダーデコーダーアーキテクチャです。 最近、T5、Bart、Pegasus、ProphetNet、Margeなど、トランスフォーマーベースのエンコーダーデコーダーモデルの異なる事前学習目的に関する多くの研究が行われていますが、モデルのアーキテクチャはほとんど変わっていません。 このブログ記事の目的は、トランスフォーマーベースのエンコーダーデコーダーアーキテクチャがシーケンス対シーケンスの問題をどのようにモデル化しているかを詳細に説明することです。アーキテクチャによって定義された数学モデルとそのモデルを推論に使用する方法に焦点を当てます。途中で、NLPのシーケンス対シーケンスモデルについての背景をいくつか説明し、トランスフォーマーベースのエンコーダーとデコーダーのパーツに分解します。多くのイラストを提供し、トランスフォーマーベースのエンコーダーデコーダーモデルの理論と🤗Transformersにおける実際の使用方法のリンクを確立します。なお、このブログ記事ではそのようなモデルをトレーニングする方法については説明していません。これについては将来のブログ記事のテーマです。 トランスフォーマーベースのエンコーダーデコーダーモデルは、表現学習とモデルアーキテクチャに関する数年にわたる研究の成果です。このノートブックでは、ニューラルエンコーダーデコーダーモデルの歴史の簡単な概要を提供します。詳細については、Sebastion Ruder氏の素晴らしいブログ記事を読むことをお勧めします。また、セルフアテンションアーキテクチャの基本的な理解も推奨されます。以下のJay Alammar氏のブログ記事は、元のトランスフォーマーモデルの復習として役立ちます。 このノートブックの執筆時点では、🤗Transformersには、T5、Bart、MarianMT、Pegasusのエンコーダーデコーダーモデルが含まれており、これらはモデルの要約についてはドキュメントで要約されています。 このノートブックは4つのパートに分かれています: 背景 – ニューラルエンコーダーデコーダーモデルの短い歴史がRNNベースのモデルに焦点を当てて与えられます。 エンコーダーデコーダー…

fairseqのwmt19翻訳システムをtransformersに移植する
Stas Bekmanさんによるゲストブログ記事 この記事は、fairseq wmt19翻訳システムがtransformersに移植された方法をドキュメント化する試みです。 私は興味深いプロジェクトを探していて、Sam Shleiferさんが高品質の翻訳者の移植に取り組んでみることを提案してくれました。 私はFacebook FAIRのWMT19ニュース翻訳タスクの提出に関する短い論文を読み、オリジナルのシステムを試してみることにしました。 最初はこの複雑なプロジェクトにどう取り組むか分からず、Samさんがそれを小さなタスクに分解するのを手伝ってくれました。これが非常に助けになりました。 私は、両方の言語を話すため、移植中に事前学習済みのen-ru / ru-enモデルを使用することを選びました。ドイツ語は話せないので、de-en / en-deのペアで作業するのははるかに難しくなります。移植プロセスの高度な段階で出力を読んで意味を理解することで翻訳の品質を評価できることは、多くの時間を節約することができました。 また、最初の移植をen-ru / ru-enモデルで行ったため、de-en / en-deモデルが統合されたボキャブラリを使用していることに全く気づいていませんでした。したがって、2つの異なるサイズのボキャブラリをサポートするより複雑な作業を行った後、統合されたボキャブラリを動作させるのは簡単でした。 手抜きしましょう 最初のステップは、もちろん手抜きです。大きな努力をするよりも小さな努力をする方が良いです。したがって、fairseqへのプロキシとして機能し、transformersのAPIをエミュレートする数行のコードで短いノートブックを作成しました。 もし基本的な翻訳以外のことが必要なければ、これで十分でした。しかし、もちろん、完全な移植を行いたかったので、この小さな勝利の後、より困難な作業に移りました。 準備 この記事では、~/portingの下で作業していると仮定し、したがってこのディレクトリを作成します:…

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。 BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。 Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。 このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et…
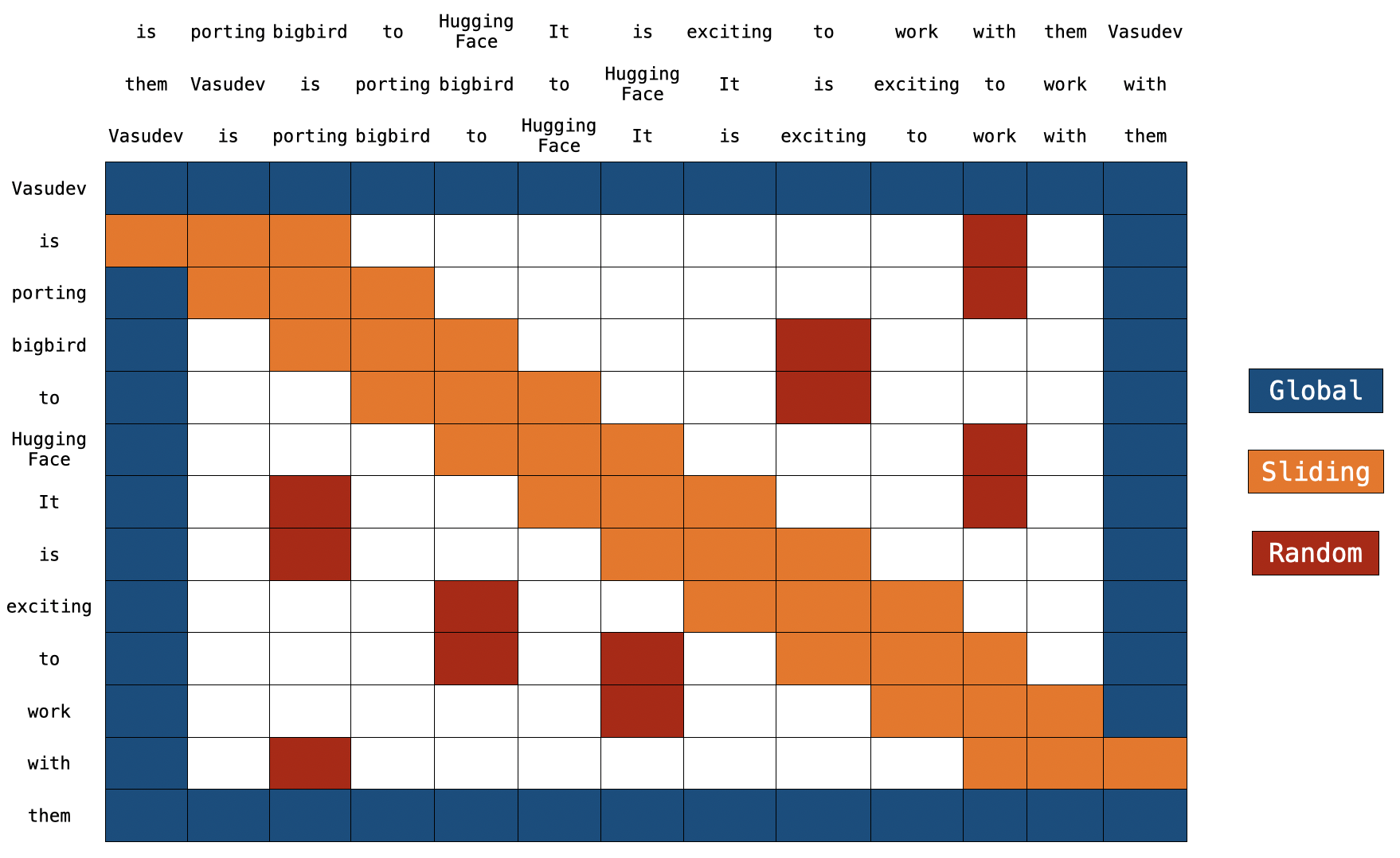
BigBirdのブロック疎な注意機構の理解
イントロダクション トランスフォーマーベースのモデルは、多くの自然言語処理タスクにおいて非常に有用であることが示されています。ただし、トランスフォーマーベースのモデルの主な制限は、O(n^2) の時間とメモリの複雑さ(ここで n はシーケンスの長さです)です。したがって、長いシーケンス n > 512 に対してトランスフォーマーベースのモデルを適用するのは計算上非常に高コストです。最近のいくつかの論文では、Longformer、Performer、Reformer、Clustered attention などが、完全な注意行列を近似することでこの問題を解決しようとしています。これらのモデルについて詳しく知りたい場合は、🤗の最近のブログ記事をチェックしてください。 BigBird(論文で紹介)は、この問題に対処するための最近のモデルの1つです。 BigBird は通常の注意(つまり、BERTの注意)ではなく、ブロックスパースな注意を使用し、BERTよりも低い計算コストで長さ 4096 のシーケンスを処理することができます。 BigBird は、長いドキュメントの要約、長いコンテキストを持つ質問応答など、非常に長いシーケンスを含むさまざまなタスクでSOTAを達成しています。 BigBird RoBERTa-like モデルは現在、🤗Transformersで利用できます。この記事の目的は、読者に 詳細な BigBird の実装の理解を提供し、🤗Transformers…

bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
LLMは大きいことで知られており、一般のハードウェア上で実行またはトレーニングすることは、ユーザーにとって大きな課題であり、アクセシビリティも困難です。私たちのLLM.int8ブログポストでは、LLM.int8論文の技術がtransformersでどのように統合され、bitsandbytesライブラリを使用しているかを示しています。私たちは、モデルをより多くの人々にアクセス可能にするために、再びbitsandbytesと協力することを決定し、ユーザーが4ビット精度でモデルを実行できるようにしました。これには、テキスト、ビジョン、マルチモーダルなどの異なるモダリティの多くのHFモデルが含まれます。ユーザーはまた、Hugging Faceのエコシステムからのツールを活用して4ビットモデルの上にアダプタをトレーニングすることもできます。これは、DettmersらによるQLoRA論文で今日紹介された新しい手法です。論文の概要は以下の通りです: QLoRAは、1つの48GBのGPUで65Bパラメータモデルをフィントゥーニングするためのメモリ使用量を十分に削減しながら、完全な16ビットのフィントゥーニングタスクのパフォーマンスを維持する効率的なフィントゥーニングアプローチです。QLoRAは、凍結された4ビット量子化された事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝搬させます。私たちの最高のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達しますが、1つのGPUでのフィントゥーニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています:(a)通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(b)量子化定数を量子化して平均メモリフットプリントを減らすためのダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザ。私たちはQLoRAを使用して1,000以上のモデルをフィントゥーニングし、高品質のデータセットを使用した指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供しています。これは通常のフィントゥーニングでは実行不可能である(例えば33Bおよび65Bパラメータモデル)モデルタイプ(LLaMA、T5)とモデルスケールを横断したものです。私たちの結果は、QLoRAによる小規模な高品質データセットでのフィントゥーニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。さらに、ヒューマンとGPT-4の評価に基づいてチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価がヒューマンの評価に対して安価で合理的な代替手段であることを示しています。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するための信頼性がないことがわかります。レモンピックされた分析では、GuanacoがChatGPTに比べてどこで失敗するかを示しています。私たちは4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 リソース このブログポストとリリースには、4ビットモデルとQLoRAを始めるためのいくつかのリソースがあります: 元の論文 基本的な使用法Google Colabノートブック-このノートブックでは、4ビットモデルとその変種を使用した推論の方法、およびGoogle ColabインスタンスでGPT-neo-X(20Bパラメータモデル)を実行する方法を示しています。 フィントゥーニングGoogle Colabノートブック-このノートブックでは、Hugging Faceエコシステムを使用してダウンストリームタスクで4ビットモデルをフィントゥーニングする方法を示しています。Google ColabインスタンスでGPT-neo-X 20Bをフィントゥーニングすることが可能であることを示しています。 論文の結果を再現するための元のリポジトリ Guanaco 33b playground-または以下のプレイグラウンドセクションをチェック はじめに モデルの精度と最も一般的なデータ型(float16、float32、bfloat16、int8)について詳しく知りたくない場合は、これらの概念の詳細について視覚化を含めた簡単な言葉で説明している私たちの最初のブログポストの紹介を注意深くお読みいただくことをお勧めします。 詳細については、このwikibookドキュメントを通じて浮動小数点表現の基本を読むことをお勧めします。 最近のQLoRA論文では、4ビットFloatと4ビットNormalFloatという異なるデータ型を探求しています。ここでは、理解しやすい4ビットFloatデータ型について説明します。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.