Learn more about Search Results Ollie

- You may be interested
- 「クラスタリング解放:K-Meansクラスタリ...
- 「ディープラーニングの謎を解明する:CIF...
- 「GPT-4 コードインタープリター:瞬時にP...
- 「PyrOSM Open Street Mapデータとの作業」
- 人工知能を規制するための競争
- LLM-Blenderに会いましょう:複数のオープ...
- 水中探査の革命:ブラウン大学のプリオボ...
- ミッドジャーニープロンプトのTシャツデザ...
- 「スカイラインから街並みまで: SHoP Arc...
- 見逃せない7つの機械学習アルゴリズム
- ゲームにおける人工知能の現代の8つの例
- 「これらの新しいツールは、AIから私たち...
- SoundStorm:効率的な並列音声生成
- メリーランド大学とMeta AIの研究者は、「...
- データアナリストは良いキャリアですか?

「AIと自動化ソフトウェアがビール業界を変える7つの方法」
AIと自動化は、あらゆる業界で状況を変えており、ビール製造業者は特にこのテクノロジーに基づいた革新的なソフトウェアツールによって恩恵を受けています以下に、現代のソリューションがどのように助けになるかのいくつかの例をご紹介します画像の出典 Pexels 在庫管理の効率化 ビール業界が効率改善に向けて進展している際に考慮すべきことは、以下の7つの方法によってAIと自動化ソフトウェアがビール業界を変えていることです詳しくはこちらをご覧ください

「アマゾン、無人レジ技術を衣料品店に適用」
大手小売り企業AmazonのJust Walk Out無人レジショッピング技術の衣料品向け新バージョンは、アパレルを無線周波数識別(RFID)によって追跡します

「ICML 2023でのGoogle」
Cat Armatoさんによる投稿、Googleのプログラムマネージャー Googleは、言語、音楽、視覚処理、アルゴリズム開発などの領域で、機械学習(ML)の研究に積極的に取り組んでいます。私たちはMLシステムを構築し、言語、音楽、視覚処理、アルゴリズム開発など、さまざまな分野の深い科学的および技術的な課題を解決しています。私たちは、ツールやデータセットのオープンソース化、研究成果の公開、学会への積極的な参加を通じて、より協力的なエコシステムを広範なML研究コミュニティと構築することを目指しています。 Googleは、40回目の国際機械学習会議(ICML 2023)のダイヤモンドスポンサーとして誇りに思っています。この年次の一流学会は、この週にハワイのホノルルで開催されています。ML研究のリーダーであるGoogleは、今年の学会で120以上の採択論文を持ち、ワークショップやチュートリアルに積極的に参加しています。Googleは、LatinX in AIとWomen in Machine Learningの両ワークショップのプラチナスポンサーでもあることを誇りに思っています。私たちは、広範なML研究コミュニティとのパートナーシップを拡大し、私たちの幅広いML研究の一部を共有することを楽しみにしています。 ICML 2023に登録しましたか? 私たちは、Googleブースを訪れて、この分野で最も興味深い課題の一部を解決するために行われるエキサイティングな取り組み、創造性、楽しさについてさらに詳しく知ることを願っています。 GoogleAIのTwitterアカウントを訪れて、Googleブースの活動(デモやQ&Aセッションなど)について詳しく知ることができます。Google DeepMindのブログでは、ICML 2023での技術的な活動について学ぶことができます。 以下をご覧いただき、ICML 2023で発表されるGoogleの研究についてさらに詳しくお知りください(Googleの関連性は太字で表示されます)。 理事会および組織委員会 理事会メンバーには、Corinna Cortes、Hugo Larochelleが含まれます。チュートリアルの議長には、Hanie Sedghiが含まれます。 Google…

「ODSC Europe 2023の写真とハイライト」
ODSC Europe 2023から数週間が経ちましたが、最高のノートで去ることができました週はデータサイエンスのトップトピック、AIのイノベーションに関する魅力的なセッションで満ち、しばらく会っていなかった笑顔の顔もありました以下はODSCのハイライトです...
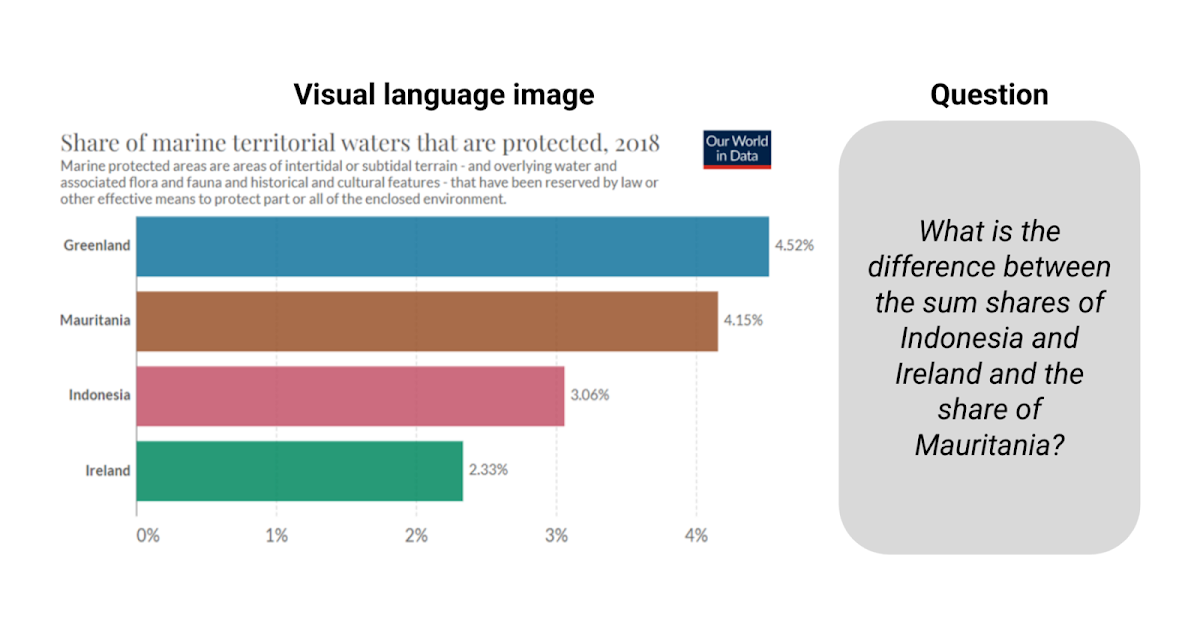
チャートの推論に基づくモデルの基盤
グーグルリサーチのリサーチソフトウェアエンジニア、ジュリアン・アイゼンシュロスによる投稿 ビジュアル言語は、情報を伝えるためにテキスト以外の絵文字を使用するコミュニケーション形式です。アイコノグラフィ、情報グラフィック、表、プロット、チャートなどの形でデジタルライフで普及しており、道路標識、コミックブック、食品ラベルなどの現実世界にも広がっています。このようなメディアをコンピュータがより理解できるようにすることは、科学的コミュニケーションと発見、アクセシビリティ、データの透過性に役立ちます。 ImageNetの登場以来、学習ベースのソリューションを使用してコンピュータビジョンモデルは大きな進歩を遂げてきましたが、焦点は自然画像にあり、分類、ビジュアルクエスチョンアンサリング(VQA)、キャプション、検出、セグメンテーションなどのさまざまなタスクが定義され、研究され、いくつかの場合には人間の性能に達成されています。しかし、ビジュアル言語は同じレベルの注目を集めていません。これは、この分野における大規模なトレーニングセットの不足のためかもしれません。しかし、PlotQA、InfographicsVQA、ChartQAなどの視覚言語イメージにおける質問応答システムの評価を目的とした新しい学術データセットが、ここ数年で作成されています。 ChartQAからの例。質問に答えるには、情報を読み取り、合計と差を計算する必要があります。 これらのタスクに対して構築された既存のモデルは、光学的文字認識(OCR)情報とその座標を大規模なパイプラインに統合することに頼っていましたが、プロセスはエラーが発生しやすく、遅く、一般化が悪いです。既存の畳み込みニューラルネットワーク(CNN)またはトランスフォーマーに基づくエンドツーエンドのコンピュータビジョンモデルは、自然画像で事前にトレーニングされたモデルを簡単にビジュアル言語に適応させることができなかったため、これらの方法が広く使用されていました。しかし、既存のモデルは、棒グラフの相対高さや円グラフのスライスの角度を読み取り、軸のスケールを理解し、色、サイズ、テクスチャでピクトグラムを伝説値に正しくマッピングし、抽出された数字で数値演算を実行するなど、チャートの質問に対する課題には準備ができていません。 これらの課題に対応するために、「MatCha:数学推論とチャートディレンダリングを活用したビジュアル言語の事前トレーニングの強化」という提案を行います。 MatChaは数学とチャートを表す言葉であり、2つの補完的なタスクでトレーニングされたピクセルからテキストへの基礎モデル(複数のアプリケーションでファインチューニングできる組み込み帰納バイアスを備えた事前トレーニングモデル)です。1つはチャートディレンダリングであり、プロットまたはチャートが与えられた場合、画像からテキストモデルはその基礎となるデータテーブルまたはレンダリングに使用されるコードを生成する必要があります。数学推論の事前トレーニングでは、テキストベースの数値推論データセットを選択し、入力を画像にレンダリングし、画像からテキストモデルが回答をデコードする必要があります。また、「DePlot:プロットからテーブルへの翻訳によるワンショットビジュアル言語推論」という、テーブルへの翻訳を介したチャートのワンショット推論にMatChaの上に構築されたモデルを提案します。これらの方法により、ChartQAの以前の最高記録を20%以上超え、パラメータが1000倍多い最高の要約システムに達成します。両方の論文はACL2023で発表されます。 チャートディレンダリング プロットやチャートは、基礎となるデータテーブルとコードによって通常生成されます。コードは、図の全体的なレイアウト(タイプ、方向、色/形状スキームなど)を定義し、基礎となるデータテーブルは実際の数字とそのグループ化を確立します。データとコードの両方がコンパイラ/レンダリングエンジンに送信され、最終的な画像が作成されます。チャートを理解するには、イメージ内の視覚パターンを発見し、効果的に解析してグループ化し、主要な情報を抽出する必要があります。プロットレンダリングプロセスを逆転するには、すべてのこのような機能が必要であり、したがって理想的な事前トレーニングタスクとして機能することができます。 ランダムなプロットオプションを使用して、Airbus A380 Wikipediaページの表から作成されたチャートです。MatChaの事前トレーニングタスクは、イメージからソーステーブルまたはソースコードを回復することです。 チャート、その基礎となるデータテーブル、およびそのレンダリングコードを同時に取得することは、実践的には困難です。事前トレーニングデータを十分に収集するために、[chart、code]および[chart、table]のペアを独立して蓄積します。[chart、code]の場合、適切なライセンスを持つすべてのGitHub IPythonノートブックをクロールし、図を含むブロックを抽出します。図とそれに直前にあるコードブロックは、[chart、code]ペアとして保存されます。[chart、table]のペアについては、2つのソースを調査しました。最初のソースは、合成データで、TaPasコードベースからWebクロールされたWikipediaテーブルを手動でコードに変換します。列のタイプに応じて、いくつかのプロットオプションをサンプリングして組み合わせます。さらに、事前トレーニングコーパスを多様化するために、PlotQAで生成された[chart、table]ペアも追加します。2番目のソースはWebクロールされた[chart、table]ペアです。Statista、Pew、Our World in Data、OECDの4つのWebサイトから合計約20,000ペアを含むChartQAトレーニングセットでクロールされた[chart、table]ペアを直接使用します。 数学的推論 MatChaに数値推論知識を組み込むために、テキスト数学データセットから数学的推論スキルを学習します。事前トレーニングには、MATHとDROPの2つの既存のテキスト数学推論データセットを使用します。MATHは合成的に作成され、各モジュール(タイプ)の質問ごとに200万のトレーニング例を含んでいます。DROPは読解型のQAデータセットで、入力はパラグラフのコンテキストと質問です。 DROPでの質問を解決するには、モデルがパラグラフを読み、関連する数字を抽出し、数値計算を実行する必要があります。私たちは、両方のデータセットが補完的であることを発見しました。MATHには、異なるカテゴリーにわたる多数の質問が含まれており、モデルに明示的に注入する必要がある数学的操作を特定するのに役立ちます。DROPの読解形式は、モデルが情報抽出と推論を同時に実行する典型的なQA形式に似ています。実際には、両方のデータセットの入力を画像にレンダリングします。モデルは答えをデコードするように訓練されます。 MATHとDROPからの例をMatChaの事前トレーニング目的に取り込むことにより、MatChaの数学的推論スキルを向上させます。入力テキストを画像としてレンダリングします。 エンドツーエンドの結果 Webサイト理解に特化した画像からテキストへの変換トランスフォーマーであるPix2Structモデルバックボーンを使用し、上記の2つのタスクで事前トレーニングを行います。MatChaの強みを示すために、表の基礎にアクセスできない質問応答や要約のためのチャートやプロットを含むいくつかの視覚言語タスクで微調整します。MatChaは、以前のモデルの性能を大幅に上回り、基礎となるテーブルにアクセスできると仮定する以前の最先端も上回ります。 以下の図では、チャートと作業するための標準的なアプローチであったOCRパイプラインから情報を取り込んだ2つのベースラインモデルを最初に評価します。最初のものはT5に基づき、2番目のものはVisionTaPasに基づきます。また、PaLI-17BとPix2Structのモデル結果を報告します。PaLI-17Bは、多様なタスクでトレーニングされた大型(他のモデルの約1000倍)のイメージプラステキスト・トゥ・テキスト・トランスフォーマーですが、テキストやその他の視覚言語の読み取り能力に限界があります。最後に、Pix2StructとMatChaのモデル結果を報告します。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.