Learn more about Search Results Neo4j

- You may be interested
- 省エネAI:ニューロモーフィックコンピュ...
- あなたのオープンソースのLLMプロジェクト...
- 「ニューラルネットワークとディープラー...
- AIの進歩における倫理的な課題のナビゲー...
- 「HuggingFaceを使用したLlama 2 7B Fine-...
- 「機械学習チートシートのためのScikit-le...
- 情報セキュリティ:IoT業界内のAIセキュリ...
- 「TALL(タール):空間および時間的な依...
- アシストされた生成:低遅延テキスト生成...
- 「LLMにおけるリトリーバル・オーグメンテ...
- 「エラーバーの可視化に深く潜る」
- LangChain チートシート
- ラマインデックスを使って、独自のパンダA...
- もし芸術が私たちの人間性を表現する方法...
- NLPの探求 – NLPのキックスタート(...

「Chat-GPTとPythonを使用して、自分の記事に基づいてNeo4jで知識グラフを構築する方法」
この記事では、Python、LLM(ChatGPT)、およびNeo4jを使用して、非構造化ドキュメントから知識グラフを構築しますこれは、これを自動的に行うことが実際に可能であることを示す小規模なPoCとして機能します
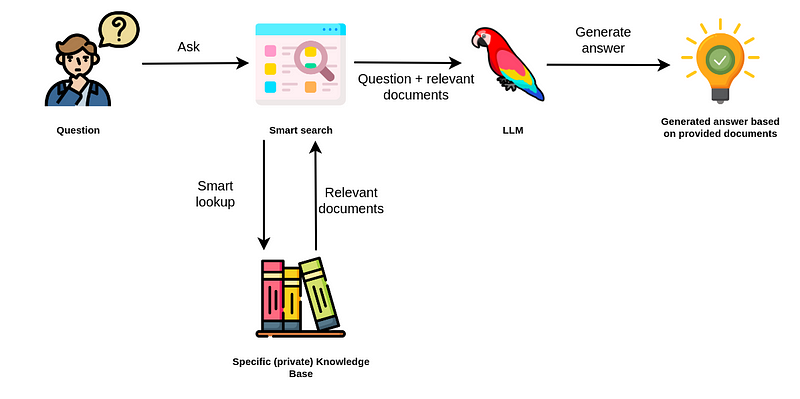
「Neo4jにおける非構造化テキストに対する効率的な意味検索」
ChatGPTが6か月前に登場して以来、技術の風景は変革的な転換を遂げましたChatGPTの優れた一般化能力により、...
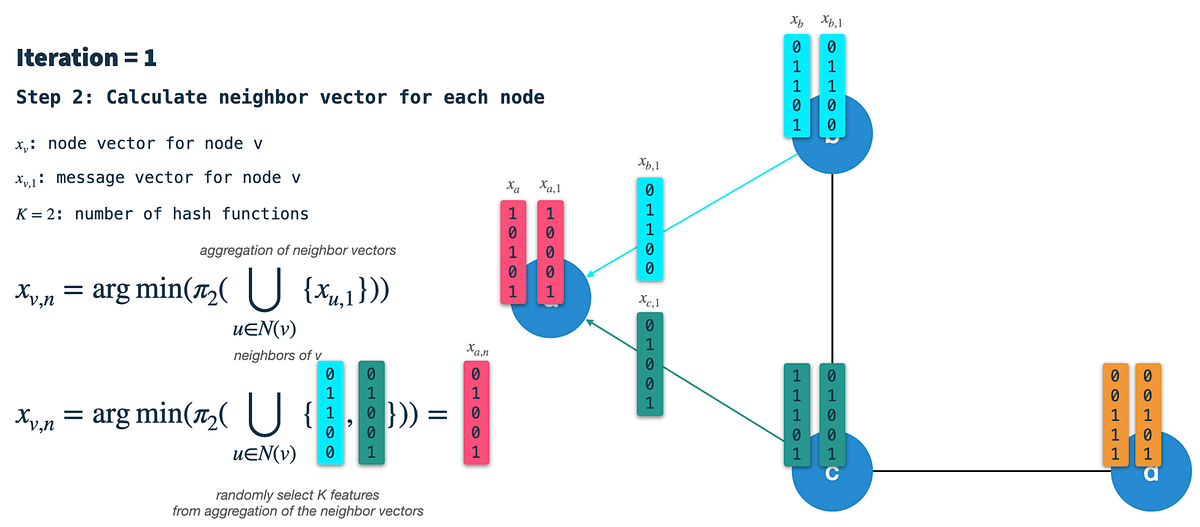
HashGNN Neo4j GDSの新しいノード埋め込みアルゴリズムに深く入り込む
HashGG(#GNN)は、高次の近接性とノードの特性を捉えるためにメッセージパッシングニューラルネットワーク(MPNN)の概念を利用するノード埋め込み技術ですこれにより、大幅にスピードアップします...

グラフ、分析、そして生成AI グラフニュースレターの年
グラフ、分析、および生成AIグラフとAIが結びつくさまざまな方法と、業界と研究のニュースについての説明

「ODSC West 2023 写真で振り返る」
「ODSCウエストは今や私たちの歴史の一部であり、全てがうまくいっていて幸せです初めてのハロウィンパーティー、さらに多くの本のサイン会、エキサイティングな基調講演、そして誰にでも合ったセッションがたくさんありましたイベントの写真はこちらでご覧いただけます」

「どのテキストもコンセプトのグラフに変換する方法」
テキストコーパスから知識グラフ(コンセプトグラフ)をMistral 7Bを使用して作成する

「Cheat Sheetつきで始めるグラフデータベースクエリ」
グラフデータベースは、企業のIT組織における分析ツールセットの中で急速に重要な役割を果たしていますもしSQLを知っているのであれば、簡単にCypherを学ぶことができ、データ分析のための大きな機会を開拓することができます

「LLMsにおけるエンタープライズ知識グラフの役割」
紹介 大規模言語モデル(LLM)と生成AIは、人工知能と自然言語処理の革新的なブレークスルーを表します。彼らは人間の言語を理解し、生成することができ、テキスト、画像、音声、合成データなどのコンテンツを生成することができるため、さまざまなアプリケーションで非常に柔軟に使用できます。生成AIはコンテンツ作成の自動化や強化、ユーザーエクスペリエンスの個別化、ワークフローの効率化、創造性の促進など、現実世界のアプリケーションで非常に重要な役割を果たしています。この記事では、エンタープライズがオープンLLMと統合できるように、エンタープライズナレッジグラフを効果的にプロンプトに基づいて構築する方法に焦点を当てます。 学習目標 LLM/Gen-AIシステムと対話しながら、グラウンディングとプロンプトの構築に関する知識を獲得する。 グラウンディングのエンタープライズへの関連性と、オープンなGen-AIシステムとの統合によるビジネス価値を例を挙げながら理解する。 知識グラフとベクトルストアという2つの主要なグラウンディング競争解決策を、さまざまな側面で分析し、どちらがどのような場合に適しているかを理解する。 パーソナライズされたおすすめの顧客シナリオにおいて、知識グラフ、学習データモデリング、およびグラフモデリングを活用したグラウンディングとプロンプトのサンプルエンタープライズ設計を研究する。 この記事はData Science Blogathonの一環として公開されました。 大規模言語モデルとは何ですか? 大規模言語モデルは、深層学習技術を用いて大量のテキストや非構造化データをトレーニングした高度なAIモデルです。これらのモデルは人間の言語と対話し、人間らしいテキスト、画像、音声を生成し、さまざまな自然言語処理タスクを実行することができます。 一方、言語モデルの定義は、テキストコーパスの分析に基づいて単語のシーケンスに対して確率を割り当てることを指します。言語モデルは、シンプルなn-gramモデルからより洗練されたニューラルネットワークモデルまでさまざまなものがあります。ただし、”大規模言語モデル”という用語は、深層学習技術を使用し、パラメータが数百万から数十億に及ぶモデルを通常指します。これらのモデルは、言語の複雑なパターンを捉え、しばしば人間が書いた文と区別のつかないテキストを生成することができます。 プロンプトとは何ですか? LLMまたは同様のチャットボットAIシステムへのプロンプトとは、会話やAIとの対話を開始するために提供するテキストベースの入力やメッセージのことです。LLMは柔軟で、さまざまなタスクに使用されるため、プロンプトのコンテキスト、範囲、品質、明瞭さは、LLMシステムから受け取る応答に重要な影響を与えます。 グラウンディング/RAGとは何ですか? 自然言語LLM処理の文脈におけるグラウンディング、またはリトリーバル拡張生成(RAG)は、プロンプトをコンテキスト、追加のメタデータ、および範囲で豊かにすることを指します。これにより、AIシステムは必要な範囲とコンテキストに合わせてデータを理解し、解釈するのに役立ちます。LLMの研究によれば、応答の品質はプロンプトの品質に依存することが示されています。 これはAIの基本的な概念であり、生データと人間の理解と範囲を一致する形でデータを処理および解釈する能力とのギャップを埋める役割を果たします。これにより、AIシステムの品質と信頼性が向上し、正確かつ有用な情報や応答を提供する能力が高まります。 LLMの欠点は何ですか? GPT-3などの大規模言語モデル(LLM)はさまざまなアプリケーションで注目と利用が進んでいますが、いくつかの欠点も存在します。LLMの主な欠点には以下があります: 1. バイアスと公平性:LLMはしばしば訓練データからバイアスを引き継ぎます。これにより、バイアスを持ったまたは差別的なコンテンツの生成が生じ、有害なステレオタイプを強化し、既存のバイアスを固定化する可能性があります。 2. 幻覚:…

「ODSC West AIエキスポであなたのAIの解決策を見つけよう」
数週間後のODSC Westの一環として開催されるAI Expo and Demo Hallでは、Microsoft Azure、Hewlett Packard、Iguazio、neo4j、Tangent Works、Qwak、Clouderaなどの業界大手組織の代表者と直接会う機会がありますまた、最新のNLPツールについても学ぶことができます

「フリーODSCウェストオープンパス」を紹介します
「オープンデータとデータサイエンス、AIコミュニティの成長のために、私たちは喜んでお知らせします今年10月30日から11月2日に行われるODSCウエストでは、参加者全員に無料のODSCオープンパスを提供しています参加経験のない方々にとっては...」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.