Learn more about Search Results Kubernetes

- You may be interested
- クラウド移行のマスタリング:成功させる...
- 中国のSJTUの研究者たちは、大規模なLiDAR...
- 「LLMモニタリングと観測性 – 責任...
- 「LangChain、Google Maps API、およびGra...
- 「PythonでゼロからGANモデルを構築および...
- MITとMeta AIからのこのAI研究は、高度な...
- 新しいOpenAIのGPTsサービスが小規模ビジ...
- 「06/11から12/11までの週のトップ重要コ...
- HuggingFace Researchが紹介するLEDITS:D...
- 「Apple製品に見つかった欠陥がスパイウェ...
- 「AWSを基にしたカスケーディングデータパ...
- 「Python タイムスタンプ:初心者のための...
- チャットGPTの潜在能力を引き出すためのプ...
- 「AIライティング革命のナビゲーション:C...
- PythonのAsyncioをAiomultiprocessで強化...

KubernetesでのGenAIアプリケーションの展開:ステップバイステップガイド
このガイドは、高い可用性のためにKubernetes上でGenAIアプリケーションを展開するための包括的で詳細な手順を提供します

「Kubernetesに対応した無限スケーラブルストレージ」
時には、ただ機能するストレージが必要ですCephを使用して、Kubernetesクラスタで無限にスケーリング可能な複製ストレージを取得する方法を学びましょう!確実に動作することを確認するために、ノードを破壊しましょう💥

データから洞察力へ:KubernetesによるAI/MLの活用
「KubernetesがAI/MLと連携することで、AI/MLのワークロードに対して細粒度の制御、セキュリティ、弾力性を提供する方法を発見しましょう」
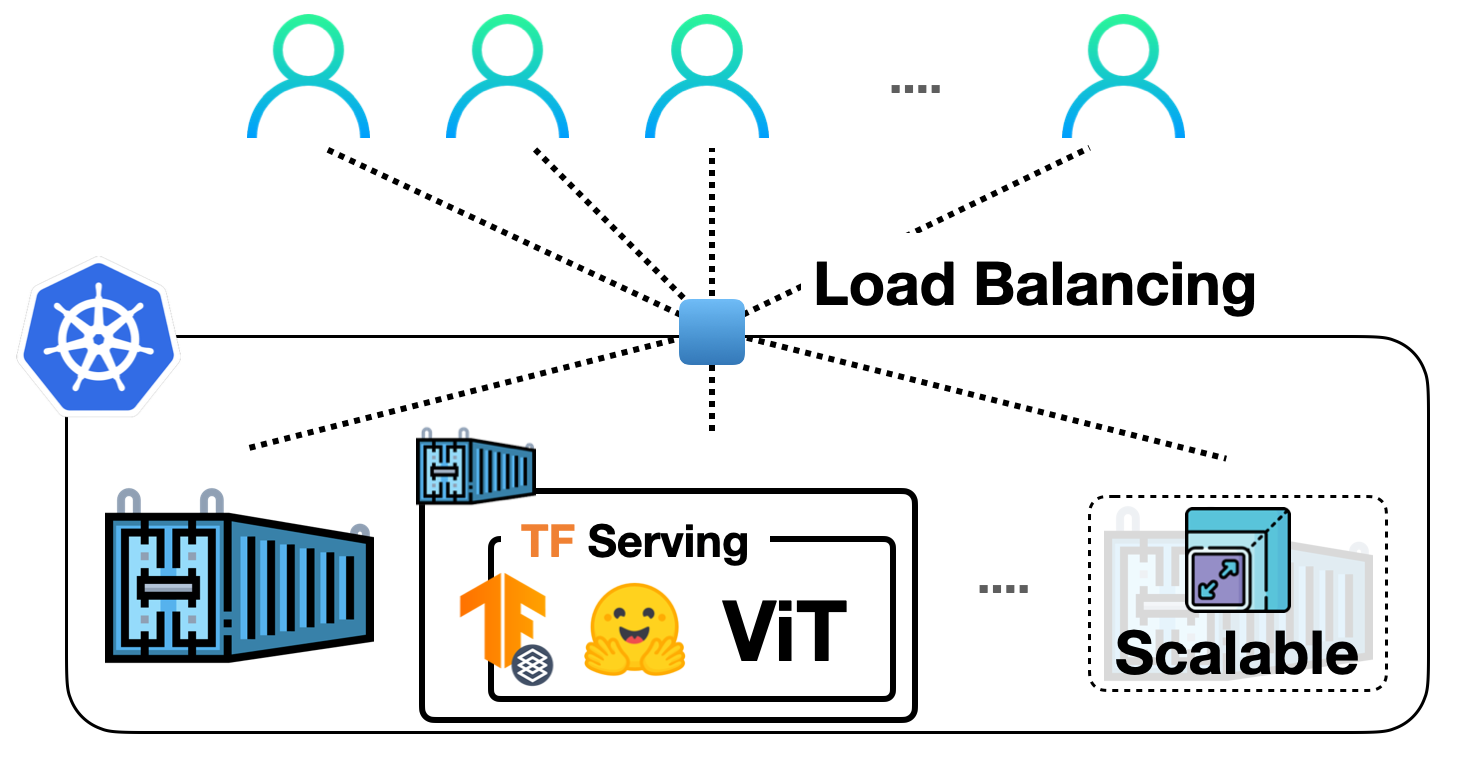
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…

「変化の風を操る:2024年の主要なテクノロジートレンド」
AIの進歩からインフラのイノベーション、メールセキュリティの要件など、将来の展望を把握し、組織を戦略的に導くための理解を得る

「GoogleがCloud TPU v5pとAIハイパーコンピューターを発表:AI処理能力の飛躍」
Googleは、AIハイパーコンピュータと呼ばれる画期的なスーパーコンピューターアーキテクチャと共に、テンサープロセッシングユニットのリリースで波紋を広げました。これらの革新的なリリースは、リソース管理ツールのダイナミックワークロードスケジューラーとともに、組織のAIタスクの処理における重要な前進を示しています。 直近の11月にリリースされたv5eに継ぎ、Googleの最もパワフルなTPUであるCloud TPU v5pは、従来の設計とは異なり、性能志向のデザインを採用しており、処理能力の大幅な向上を約束しています。ポッドごとに8,960個のチップを装備し、チップ間のインターコネクションスピードは4,800 Gbpsを誇ります。このバージョンは、前のTPU v4と比べて倍のFLOPSと高帯域幅メモリ(HBM)の3倍の印象的な増加を提供します。 パフォーマンスへの注力が大きな成果をもたらし、Cloud TPU v5pは、大規模なLLMモデルのトレーニング時にTPU v4と比べて驚異的な2.8倍の速度向上を実証しています。さらに、第2世代のSparseCoresを活用することで、v5pは前任者に比べて組み込み密なモデルのトレーニング速度が1.9倍速くなります。 一方、AIハイパーコンピューターは、スーパーコンピューターアーキテクチャの革新的な存在となっています。最適化されたパフォーマンスハードウェア、オープンソースソフトウェア、主要な機械学習フレームワーク、そして適応的な消費モデルを組み合わせています。AIハイパーコンピューターは、単一のコンポーネントの補強ではなく、協力的なシステム設計を活用して、トレーニング、微調整、そしてサービスのドメイン全体でAIの効率と生産性を向上させています。 この高度なアーキテクチャは、超大規模なデータセンターインフラストラクチャをベースに、厳密に最適化された計算、ストレージ、ネットワークデザインを特徴としています。さらに、JAX、TensorFlow、PyTorchなどの機械学習フレームワークをサポートするオープンソースソフトウェアを介して関連するハードウェアへのアクセスも提供しています。この統合は、Multislice TrainingやMultihost Inferencingなどのソフトウェアと、Google Kubernetes Engine(GKE)やGoogle Compute Engineとの深い統合にも及びます。 AIハイパーコンピューターを特筆するのは、AIタスクに特化した柔軟な消費モデルです。革新的なダイナミックワークロードスケジューラーやCommitted Use Discounts(CUD)、オンデマンド、スポットなどの伝統的な消費モデルを導入しています。このリソース管理およびタスクスケジューリングプラットフォームは、Cloud TPUとNvidia GPUをサポートし、ユーザーの支出を最適化するために必要なすべてのアクセラレーターのスケジュールを効率化します。 このモデルでは、Flex…

「Neosyncをご紹介します:開発環境やテストにおいて、製造データを同期化し、匿名化するためのオープンソースソリューション」
ソフトウェア開発では、テストと開発の目的で機密性の高い本番データを扱う際に、チームはしばしば課題に直面します。データのプライバシーとセキュリティをバランスする必要性と、強力なテストの必要性の両立は難しいものです。既存の解決策には、データの匿名化や合成データの作成に手作業が必要な場合もありますが、これらのプロセスをより便利かつ効率的にする必要があるかもしれません。 この問題に取り組む一つの一般的な手法は、テストのためにデータを手動で匿名化または生成することです。しかし、これは時間がかかり、エラーを起こしやすく、潜在的なセキュリティリスクを引き起こす可能性があります。技術の進歩に伴い、Neosyncと呼ばれる新しいオープンソースのソリューションが現れました。このソリューションは、このプロセスを簡略化し、合理化するために登場しました。 Neosyncは、本番データベースのスナップショットにシームレスに接続することで、チームが本番スキーマに基づいた合成データを生成したり、既存の本番データを匿名化したりすることを可能にするプラットフォームです。この匿名化されたまたは合成データは、ローカル開発、ステージング、および継続的な統合テストを含むさまざまな環境で同期できます。 Neosyncの主な特徴は、自動的に合成データを生成し、機密情報を匿名化し、特定のテストニーズに対応するために本番データベースのサブセットを作成する能力です。このプラットフォームはGitOpsベースのアプローチを採用しており、既存の開発者ワークフローにスムーズに適合します。Neosyncはまた、テスト中に発生する可能性のある外部キーの破損に関する懸念を解決するためにデータの整合性を確保します。 Neosyncの特筆すべき側面の一つは、ジョブの再試行、失敗、再生を処理する包括的な非同期パイプラインです。これにより、開発者にとって頑強かつ信頼性の高いテスト環境が確保されます。このプラットフォームは、事前に構築されたトランスフォーマーを使用してさまざまなデータ型をサポートし、特定の要件に応じてカスタムトランスフォーマーを定義することも可能です。 Neosyncは、どのワークフローにもシームレスに統合される世界クラスの開発者体験を提供することで、その機能を実証しています。PostgresやMySQLなどの複数のデータベースシステム、およびS3などのストレージソリューションのサポートにより、その汎用性が向上しています。KubernetesやDockerなどのツールを使用することで、効率的でスケーラブルな開発環境が提供されます。 まとめると、Neosyncは、効率的なテストとデータプライバシーのバランスを求める開発者にとって貴重なソリューションです。オープンソースの性質により、チームは最も機密性の高いデータを自身のインフラストラクチャ内に保持することができ、安全で信頼性の高いテスト環境を促進します。自動データ生成、匿名化、およびさまざまなデータベースのサポートなどの機能により、Neosyncは現代の開発者のベストプラクティスにぴったりと合致し、より優れた、より強靭なアプリケーションの構築に貢献しています。

「Protopia AIによる企業LLMアクセラレーションの基盤データの保護」
この記事では、Protopia AIのStained Glass Transformを使用してデータを保護し、データ所有権とデータプライバシーの課題を克服する方法について説明していますProtopia AIは、AWSと提携して、生成AIの安全かつ効率的なエンタープライズ導入のためのデータ保護と所有権の重要な要素を提供していますこの記事では、ソリューションの概要と、Retrieval Augmented Generation(RAG)などの人気のあるエンタープライズユースケースや、Llama 2などの最先端のLLMsでAWSを使用する方法をデモンストレーションしています

エグゼクティブアーキテクトのFinOpsへのアプローチ:AIと自動化がデータ管理を効率化する方法
フィンオプスは進化するクラウド金融管理の学問と文化的実践であり、組織が最大のビジネス価値を得ることを可能にします

「パーソナリティをピクセルにもたらす、Inworldは自己再生AIを使用してゲームキャラクターをレベルアップさせます」
ゲーム体験を一層向上させるために、スタジオと開発者は非常な努力を払い、写実的で没入感のあるゲーム内環境を作り上げています。 しかし、非プレイヤーキャラクター(NPC)はしばしば取り残されています。多くのNPCは深さやリアリズムに欠けた方法で行動し、その相互作用は繰り返しがちで忘れられやすいものとなっています。 Inworld AI は、生成AI を使用して、プレイヤーの行動に動的かつ応答性のあるNPCの振る舞いを実現することで、ゲームのルールを変えています。このカリフォルニア州マウンテンビューを拠点とするスタートアップのCharacter Engine は、どんなキャラクターデザインにも使用でき、スタジオと開発者がゲームプレイを向上させ、プレイヤーのエンゲージメントを高めるお手伝いをしています。 ゲーミング体験を高める:アチーブメント解除 Inworldのチームは、AIを搭載したNPCを開発することを目指しており、高品質のパフォーマンスを提供しながら、ゲーム内の没入感を保ちながらプレイヤーとの関係を築き上げることができるようにしています。 開発者がAIベースのNPCをゲームに統合しやすくするために、InworldはCharacter Engineを構築しました。このエンジンは、NVIDIAの技術上で動作する生成AIを使用して、没入感のあるインタラクティブなキャラクターを作り出すことができます。これは、プロダクションに対応したスケーラブルなソリューションであり、リアルタイムな体験に最適化されています。 Character Engine は、Character Brain、Contextual Mesh、Real-Time AI の3つのレイヤーから成り立っています。 Character Brain は、テキスト読み上げや自動音声認識、感情、ジェスチャー、アニメーションなどの複数のパーソナリティ 機械学習 モデルに同期することで、キャラクターのパフォーマンスを制御します。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.