Learn more about Search Results Intel

- You may be interested
- 「Pythonで時系列ネットワークグラフの可...
- エロン・マスクのxAIがOpenAIのChatGPTに...
- 「Pythonで脂肪尾を数値化する4つの方法」
- 「Spring Bootを使用して自分自身のChatGP...
- メタ&ジョージア工科大学の研究者たちは...
- クライテリオンを使用したRustコンパイラ...
- 「5つのオンラインAI認定プログラム ̵...
- 「Googleのトレイルブレイザーのインスピ...
- 「AutoGen:次世代の大規模言語モデルアプ...
- RayはNVIDIA AIとの協業により、開発者が...
- ランナーの疲労検知のための時間系列分類 ...
- 「AIの成長する需要が世界的な水不足を引...
- 「BoomiのCEOが統合と自動化プラットフォ...
- 「インドにおけるAI規制のためのPMモディ...
- 「Amazon Personalizeと生成AIでマーケテ...
「人工的な汎用知能(Artificial General Intelligence; AGI)の探求:AIが超人力を達成したとき」
人工知能の分野は過去10年間で大きな進歩を遂げていますが、人間レベルの知能を達成することは多くの研究者の究極の目標ですこの記事では、私は...

この中国のAIモデル、Baichuan2-192kモデルはChatGPTやClaude2を超えることができるのか? 最長のコンテキストモデルを持つBaichuan Intelligentが公開した、この中国のスタートアップ「Baichuan Intelligent」のモデルに会いましょう
AIの優位性を争う中で、中国のAIスタートアップ、百川インテリジェントが最新の大容量言語モデル、百川2-192Kを発表し、長文プロンプトの処理において新たな基準を設定しました。この開発は、中国がグローバルなAIのランドスケープにおいて先駆者としての地位を確立する意気込みを示しています。 小説や法的文書、財務報告書など、大量のテキストプロンプトを扱うAIモデルへの需要が高まっています。従来のモデルは長文に苦戦することが多く、各業界でより強力で効率的な解決策が求められています。 現在、AIのランドスケープはOpenAIやMetaなどの西洋の巨大企業によって支配されており、彼らは絶えず革新的で洗練されたモデルをリリースしています。百川インテリジェントの新作、百川2-192Kは、これらの確立されたプレイヤーに挑戦します。 百川インテリジェントは、搜狗の創設者である王小川が起業した会社であり、画期的な大容量言語モデルである百川2-192Kを紹介しました。このモデルは、「コンテキストウィンドウ」という素晴らしい機能を搭載しており、一度に約35万文字の中国語の処理が可能です。比較すると、OpenAIのGPT-4-32kを14倍、AmazonがバックアップするAnthropicのClaude 2を4.4倍上回り、長文プロンプトの取り扱いに強力なツールとなっています。 百川2-192Kの主な革新点は、広範なテキストをシームレスに処理できる能力にあります。このモデルは小説の要約や品質の高い応答、長文の理解などに優れており、カリフォルニア大学バークレー校などの米国の機関が主導するプロジェクトであるLongEvalのテスト結果によって実証されています。このモデルの素晴らしいコンテキストの長さは、パフォーマンスを損なうことなく、動的な位置エンコーディングと分散トレーニングフレームワークの技術的な革新によって実現されています。百川2-192Kの優れた能力は、法律、メディア、金融などの産業において不可欠なツールとなっています。長文の処理および生成能力は、これらのセクターにおいて重要です。ただし、より多くの情報を処理できる能力が必ずしも他のモデルよりも優れているとは限らないことに留意することも重要です。これに関しては、スタンフォード大学とUCバークレーの共同研究でも指摘されています。 百川インテリジェントのAIセクターでの急速な台頭は、設立からわずか6か月でユニコーンクラブへの参加を果たすなど、中国がAI技術の可能性を広げることへの取り組みを示しています。現在、アメリカの企業がAIハードウェアとソフトウェアでリードを占めていますが、百川の積極的な戦略と技術革新は、AIの進化するランドスケープを示しています。百川2-192Kの発表は、AIの優位性を争う競争が終わりを告げたわけではなく、中国が西洋の巨大企業の支配に挑戦する意欲を示しています。百川2-192Kは、特に長文プロンプトの取り扱いにおいてAI技術の可能性の限界を押し上げる画期的なモデルです。その優れたコンテキストの長さと品質の高い応答は、さまざまな産業にとって貴重なツールとなります。

「IntelのOpenVINOツールキットを使用したAI最適化と展開のマスタリング」
イントロダクション 人間の労働力を置き換えるAIの影響が増しているため、私たちはほぼ毎日AIについて話題にしています。AIを活用したソフトウェアの構築は、短期間で急速に成長しています。企業やビジネスは、信頼性のある責任あるAIをアプリケーションに統合し、収益を増やすことを信じています。アプリケーションにAIを統合する最も困難な部分は、モデルの推論とモデル訓練に使用される計算リソースです。既に多くのテクニックが存在しており、モデルの推論時のパフォーマンスを最適化し、より少ない計算リソースでモデルを訓練します。この問題を解決するために、IntelはOpenVINO Toolkitを導入しました。OpenVINOは革新的なオープンソースツールキットであり、AIの推論を最適化して展開することができます。 学習目標 この記事では、以下の内容を理解します。 OpenVINO Toolkitとは何か、AIの推論モデルを最適化し展開するための目的を理解します。 OpenVINOの実用的なユースケース、特にエッジにおけるAIの将来における重要性を探求します。 Google ColabでOpenVINOを使用して画像内のテキスト検出プロジェクトを実装する方法を学びます。 OpenVINOの主な特徴と利点、モデルの互換性とハードウェアアクセラレータのサポート、およびさまざまな産業とアプリケーションに与える影響を探求します。 この記事はData Science Blogathonの一環として公開されました。 OpenVINOとは何ですか? OpenVINO(オープンビジュアル推論およびニューラルネットワーク最適化)は、Intelチームによって開発されたオープンソースツールキットで、ディープラーニングモデルの最適化を容易にするものです。OpenVINOツールキットのビジョンは、AIのディープラーニングモデルを効率的かつ効果的にオンプレミス、オンデバイス、またはクラウド上で展開することです。 OpenVINO Toolkitは特に価値があります。なぜなら、TensorFlow、PyTorch、Onnx、Caffeなどのような人気のあるディープラーニングフレームワークをサポートしているからです。好きなフレームワークを使用してモデルをトレーニングし、OpenVINOを使用してIntelのハードウェアアクセラレータ(CPU、GPU、FPGA、VPUなど)にデプロイするために変換と最適化を行うことができます。 推論に関しては、OpenVINO Toolkitはモデルの量子化と圧縮のためのさまざまなツールを提供しており、推論の精度を損なうことなくディープラーニングモデルのサイズを大幅に削減することができます。 なぜOpenVINOを使用するのですか? AIの人気は現在も衰える気配がありません。この人気により、オンプレミスやオンデバイスでAIアプリケーションを実行するためのアプリケーションがますます開発されることは明らかです。OpenVINOが優れているいくつかの重要な領域は、なぜOpenVINOを使用することが重要かを理解するための理想的な選択肢となっています。 OpenVINOモデルズー OpenVINOは、安定した拡散、音声、オブジェクト検出などのタスクに対する事前トレーニング済みのディープラーニングモデルを提供するモデルズーを提供しています。これらのモデルはプロジェクトの出発点として利用することができ、時間とリソースを節約することができます。…

SynthIA(Synthetic Intelligent Agent)7B-v1.3に会ってください:オルカスタイルのデータセットで訓練されたミストラル-7B-v0.1モデルです
SynthIA-7B-v1.3は、7兆パラメーターの大規模な言語モデル(LLM)です。実際には、OrcaスタイルのデータセットでトレーニングされたMistral-7B-v0.1モデルであり、方向の指示に従い、深く議論することができます。SynthIA-7B-v1.3は完全に制約されておらず、次のようなさまざまな用途に活用することができます: テキストの作成、言語の翻訳、オリジナルコンテンツの生成、質問に対する洞察に富んだ応答が、すべてこのスキルセットの範囲内です。 要求を注意深く実行し、指示に従います。 質問が簡単か難しいか、一般的か非常識かにかかわらず、常に十分かつ正確に回答するべきです。 詩、コード、脚本、音楽、手紙、メールなどのクリエイティブなテキスト形式を生成することができます。 SynthIA-7B-v1.3は、多くの潜在的な用途を持つ強力で柔軟なLLMです。以下にいくつかの例を挙げます: 記事、ブログ、物語、詩など、SynthIA-7B-v1.3を使用して生成できる書面作品は多岐に渡ります。クリエイティブな文章執筆や言語翻訳にも使用できます。 SynthIA-7B-v1.3は、研究者の学習を支援するツールです。仮説の開発、論文の要約、レポートの作成などの形式で使用できます。 SynthIA-7B-v1.3は、教室での教育ツールとして利用することができます。カリキュラム資料の作成、学生の疑問の解決、学生の作品の評価など、多くの教育的な応用があります。 商業利用:SynthIA-7B-v1.3は、企業プロセスの改善に利用できます。製品/サービスのアイデア形成、カスタマーサポートの応答作成、マーケティングなどの潜在的な応用があります。 SynthIA-7B-v1.3ユーザーガイド 使用する場合は、SynthIA-7B-v1.3をHugging Face Transformersで見つけることができます。モデルの読み込みが完了したら、質問や指示を与えてコミュニケーションすることができます。詩の生成、テキストの翻訳、最新のニュースのレポートなど、さまざまなタスクをモデルに訓練することができます。 主な特徴 SynthIA-7B-v1.3は、7兆パラメーターという非常にパワフルで包括的なLLMの一つです。 フィルタされていません。したがって、物議を醸すまたは敏感なテーマを含むあらゆる主題についての文章を生成することができます。 長尺の会話や指示の従いに重点を置くため、文章執筆、研究、教育、ビジネス関連の相互作用に最適です。 SynthIA-7B-v1.3を最大限に活用する方法 SynthIA-7B-v1.3の最大限の活用についてのいくつかの提案: 指示や提案はできるだけ詳細にしてください。詳細な情報を提供するほど、モデルがニーズを理解し、期待される結果を生み出す能力が向上します。 モデルに何をしたいかのサンプルを与えてみてください。例えば、特定のスタイルで書かれた詩の例を使用してモデルを訓練すれば、そのようなスタイルで書かれた詩を生成するようにすることができます。 複雑な作業を簡単な作業に分割してください。これにより、モデルの作業完了能力が向上します。 SynthIA-7B-v1.3の使用には熟練が必要な場合もありますが、練習を重ねることで、プロの品質の文章を生成し、多くの目標を達成することができます。…

「Artificial Narrow Intelligence(ANI)とは何ですか?」
はじめに コンピュータが翻訳やゲームプレイのようなタスクでどのように優れたパフォーマンスを発揮できるのか、考えたことはありますか?その答えは狭義人工知能(Artificial Narrow Intelligence、ANI)です。このAIの分野は、特定の機能に優れることに焦点を当てており、専門的なタスクにおいては強力な存在です。狭義AIのコンセプトは、テクノロジーを細かくカスタマイズし、特定の目標を達成するために調整することに関係しています。技術の進化に伴い、専門家たちは狭義AIの機能を向上させるために精力的に取り組んでおり、さまざまなモデルを統合した統一されたシステムを作り上げ、複数のタスクを実行できるようにしています。この包括的な記事では、狭義AIの複雑さについて掘り下げ、そのさまざまなタイプを探求し、その利点を明らかにし、潜在能力を示す現実世界の例を見つけ出します。 狭義AIとは? 狭義人工知能は、特定のタスク上で機能するために設計された知能システムを指します。機械、モデル、またはロボットは、特定の制約や制限のセットに基づいて導入され、それに基づいて専用の目的を達成します。 狭義AIは、その制約や限定性、人間の行動を完全に模倣できないことから、弱い人工知能とも呼ばれます。さらに、狭義AIは、人工一般知能(Artificial General Intelligence、AGI)とは対照的に使用されることが非常に頻繁です。AGIは、人間の知能を模倣し、複数のタスクを同時に実行するアルゴリズムで動作します。 狭義AI vs 一般AI 以下の表で、狭義AIと一般AIの違いについて探求しましょう: 側面 狭義AI 一般AI 機能性 特定のタスクを実行することに特化しています。 人間のような認知能力を持ちます。 範囲 狭い領域やタスクに限定されます。 さまざまなタスクに対して柔軟性を持ちます。 学習 指定されたタスク内で学習し、改善します。…

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…
IntelとHugging Faceがパートナーシップを結び、機械学習ハードウェアアクセラレーションを民主化する
Hugging Faceのミッションは、優れた機械学習を民主化し、産業や社会に対するそのポジティブな影響を最大化することです。私たちはTransformerモデルの進歩だけでなく、その採用を簡素化するためにも努力しています。 本日、Intelが正式に私たちのハードウェアパートナープログラムに参加したことをお知らせいたします。Optimumオープンソースライブラリのおかげで、IntelとHugging FaceはTransformerをトレーニング、微調整、予測するための最新のハードウェアアクセラレーションを共同で開発します。 Transformerモデルはますます大きく複雑になっており、検索やチャットボットなどのレイテンシーに敏感なアプリケーションにおいて、生産上の課題を引き起こすことがあります。残念ながら、レイテンシーの最適化は機械学習(ML)の専門家にとって長年の難問でした。基盤となるフレームワークやハードウェアプラットフォームの深い知識があっても、どのツマミや機能を活用するかを見極めるために多くの試行錯誤が必要です。 Intelは、Intel Xeon Scalable CPUプラットフォームと幅広いハードウェア最適化AIソフトウェアツール、フレームワーク、ライブラリを備えた、AIの加速化に完全な基盤を提供します。そのため、Hugging FaceとIntelが力を合わせて、Intelプラットフォーム上での最高のパフォーマンス、スケーラビリティ、生産性を実現するための強力なモデル最適化ツールの開発に取り組むことは理にかなっています。 「Intel XeonハードウェアとIntel AIソフトウェアの最新のイノベーションをTransformersコミュニティにもたらすため、オープンソースの統合と統合された開発者体験を通じてHugging Faceと協力することにワクワクしています。」と、Intel副社長兼AIおよび分析のゼネラルマネージャーであるWei Li氏は述べています。 最近の数ヶ月間、IntelとHugging FaceはTransformerワークロードのスケーリングに取り組んできました。推論(パート1、パート2)の詳細なチューニングガイドとベンチマークを公開し、最新のIntel Xeon Ice Lake CPU上でDistilBERTの単桁ミリ秒レイテンシーを実現しました。トレーニングの側では、GPUよりも40%優れた価格性能を提供するHabana Gaudiアクセラレータのサポートを追加しました。 次の自然なステップは、この作業を拡大してMLコミュニティと共有することでした。それがOptimum Intelオープンソースライブラリの登場です!それをより詳しく見てみましょう。…

🤗 Optimum IntelとOpenVINOでモデルを高速化しましょう
昨年7月、インテルとHugging Faceは、Transformerモデルのための最新かつシンプルなハードウェアアクセラレーションツールの開発で協力することを発表しました。本日、私たちはOptimum IntelにIntel OpenVINOを追加したことをお知らせできて非常に嬉しく思います。これにより、Hugging FaceハブまたはローカルにホストされるTransformerモデルを使用して、様々なIntelプロセッサ上でOpenVINOランタイムによる推論を簡単に実行できます(サポートされているデバイスの完全なリストを参照)。OpenVINOニューラルネットワーク圧縮フレームワーク(NNCF)を使用してモデルを量子化し、サイズと予測レイテンシをわずか数分で削減することもできます。 この最初のリリースはOpenVINO 2022.2をベースにしており、私たちのOVModelsを使用して、多くのPyTorchモデルに対する推論を実現しています。事後トレーニング静的量子化と量子化感知トレーニングは、多くのエンコーダモデル(BERT、DistilBERTなど)に適用することができます。今後のOpenVINOリリースでさらに多くのエンコーダモデルがサポートされる予定です。現在、エンコーダデコーダモデルの量子化は有効化されていませんが、次のOpenVINOリリースの統合により、この制限は解除されるはずです。 では、数分で始める方法をご紹介します! Optimum IntelとOpenVINOを使用してVision Transformerを量子化する この例では、食品101データセットでイメージ分類のためにファインチューニングされたVision Transformer(ViT)モデルに対して事後トレーニング静的量子化を実行します。 量子化は、モデルパラメータのビット幅を減らすことによってメモリと計算要件を低下させるプロセスです。ビット数を減らすことで、推論時に必要なメモリが少なくなり、行列乗算などの演算が整数演算によって高速に実行できるようになります。 まず、仮想環境を作成し、すべての依存関係をインストールしましょう。 virtualenv openvino source openvino/bin/activate pip install pip --upgrade pip…

Intel Sapphire Rapidsを使用してPyTorch Transformersを高速化する – パート2
最近の投稿では、第4世代のIntel Xeon CPU(コードネーム:Sapphire Rapids)とその新しいAdvanced Matrix Extensions(AMX)命令セットについて紹介しました。Amazon EC2上で動作するSapphire Rapidsサーバーのクラスタと、Intel Extension for PyTorchなどのIntelライブラリを組み合わせることで、スケールでの効率的な分散トレーニングを実現し、前世代のXeon(Ice Lake)に比べて8倍の高速化とほぼ線形スケーリングを達成する方法を紹介しました。 この投稿では、推論に焦点を当てます。PyTorchで実装された人気のあるHuggingFaceトランスフォーマーと共に、Ice Lakeサーバーでの短いおよび長いNLPトークンシーケンスのパフォーマンスを測定します。そして、Sapphire RapidsサーバーとHugging Face Optimum Intelの最新バージョンを使用して同じことを行います。Hugging Face Optimum Intelは、Intelプラットフォームのハードウェアアクセラレーションに特化したオープンソースのライブラリです。 さあ、始めましょう! CPUベースの推論を検討すべき理由 CPUまたはGPUで深層学習の推論を実行するかどうかを決定する際には、いくつかの要素を考慮する必要があります。最も重要な要素は、モデルのサイズです。一般に、より大きなモデルはGPUによって提供される追加の計算能力からより多くの利益を得ることができますが、より小さいモデルはCPU上で効率的に実行することができます。…
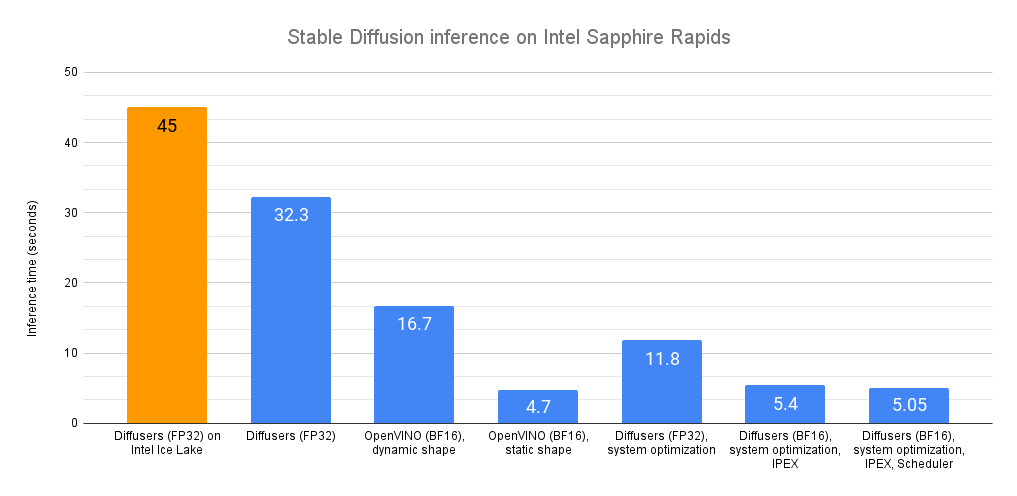
Intel CPU上での安定な拡散推論の高速化
最近、私たちは最新世代のIntel Xeon CPU(コードネームSapphire Rapids)を紹介しました。これには、ディープラーニングの高速化に対応した新しいハードウェア機能があります。また、これらを使用して自然言語処理のトランスフォーマーの分散微調整と推論を加速する方法も紹介しました。 この投稿では、Sapphire Rapids CPU上で安定拡散モデルを加速するための異なる技術を紹介します。次の投稿では、分散微調整について同様の内容を紹介します。 執筆時点では、Sapphire Rapidsサーバーにアクセスする最も簡単な方法は、Amazon EC2 R7izインスタンスファミリーを使用することです。まだプレビュー段階ですので、アクセスするためにはサインアップする必要があります。前の投稿と同様に、私はUbuntu 20.04 AMI(ami-07cd3e6c4915b2d18)を使用してr7iz.metal-16xlインスタンス(64 vCPU、512GB RAM)を使用しています。 さあ、始めましょう!コードサンプルはGitlabで利用できます。 Diffusersライブラリ Diffusersライブラリは、安定拡散モデルを使用して画像を生成するのが非常に簡単です。これらのモデルに詳しくない場合は、こちらの素晴らしいイラスト入りの紹介をご覧ください。 まず、必要なライブラリ(Transformers、Diffusers、Accelerate、PyTorch)を使用して仮想環境を作成しましょう。 virtualenv sd_inference source sd_inference/bin/activate pip…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.