Learn more about Search Results Hugo Lu

- You may be interested
- ディフューザーの新着情報は何ですか?🎨
- ディープラーニングを使用してファンタジ...
- Google AIは、アクティブノイズキャンセリ...
- 機械学習における再現性の重要性
- 時系列データのためのPandas
- 大きな言語モデルの謎を解き明かす:初心...
- SRGANs:低解像度と高解像度画像のギャッ...
- ロボット犬は、人間よりも侵略的なヒアリ...
- 「アナリストとデータサイエンティストに...
- 「DALL-E 3とChatGPTを使って、私が一貫し...
- (ローマ字:Rokkagetsu de detā anarisuto...
- 「2023年の市場で利用可能な15の最高のETL...
- 「数分で無料で自分自身の見栄えの良いウ...
- HNSW(Hierarchical Navigable Small Worl...
- 「Pythonのitertoolsで無限イテレータを探...
ナレッジグラフ、ハードウェアの選択、Pythonのワークフロー、およびその他の11月に読むべきもの
データと機械学習の専門家にとって、1年間のイベント満載な時期もいよいよ終盤に入ってきました皆さんの中には、新しいスキルを学ぶために最後の力を振り絞り、最新の研究に追いつくために奮闘している方も多いことでしょう

「LangChainとは何ですか?利用事例と利点」
LangChainはプログラマが大規模言語モデルを用いてアプリケーションを開発するための人工知能フレームワークです。ライブラリはPythonとTypeScript / JavaScriptで利用でき、開発者にとって多目的に活用できるものとなっています。テンプレートは参照アーキテクチャを提供し、アプリケーションの出発点として使用できます。LangChainフレームワークは開発から製品化、展開まで、アプリケーションのライフサイクルを効率化します。LangChainは、ステップごとに情報を求めることでチャットボットや質問応答システムなどのアプリケーションを構築するために開発者が利用することができます。また、開発者同士がお互いを支援しアイデアを共有するコミュニティも提供されています。 https://www.langchain.com/ 用途 LangChainには、自然言語を使用してSQLデータベースと対話するための機能があります。これにより、より人間らしい方法で質問したりコマンドを与えたりすることができ、LangChainがそれをSQLクエリに変換します。たとえば、先週のトップパフォーマンスを発揮した店舗を知りたい場合、LangChainにSQLクエリを生成してもらうことができます。 LangChainは、複雑なSQLクエリを手動で書くことなくデータベースとやり取りすることができる便利な機能を持っています。データベースとの会話のような感覚で、必要な情報を簡単に取得することができます。この機能により、データベースのデータに基づいて質問に答えることができるチャットボットの作成や、データ分析のためのカスタムダッシュボードの作成など、可能性が広がります。SQLデータベースに格納されたエンタープライズデータを扱う開発者にとって強力なツールです。 https://python.langchain.com/assets/images/sql_usecase-d432701261f05ab69b38576093718cf3.png 特徴 1. データの認識:LangChainは外部のデータソースと接続することで、言語モデルとの対話をより興味深くコンテキスト豊かなものにすることができます。 2. 代行的:LangChainを使用することで、言語モデルは単なる応答者にとどまらず、環境と対話することができます。これにより、アプリケーションが生き生きとしたダイナミックなものになります。 3. 簡単な統合:LangChainは使いやすく、拡張可能な標準化されたインターフェースを提供します。それはまるでアプリケーション用の共通言語を持っているようなものです。 4. スムーズな会話:効率的にプロンプトを処理することにより、言語モデルとの会話がスムーズで効果的に行えます。 5. オールインワンハブ:貴重なリソースを一箇所にまとめることで、開発者が必要なものを見つけてLangChainアプリケーションを作成し、公開するのが容易になります。 6. 見て学ぶ:LangChainは開発者が作成したチェーンとエージェントを視覚化することができます。異なるアイデア、プロンプト、モデルで実験することができます。 https://miro.medium.com/v2/resize:fit:1100/format:webp/1*05zEoeNU7DVYOFzjugiF_w.jpeg 利点 1.…

「DINO — コンピュータビジョンのための基盤モデル」
「コンピュータビジョンにとっては、エキサイティングな10年です自然言語の分野での大成功がビジョンの領域にも移されており、ViT(ビジョントランスフォーマー)の導入などが含まれています...」(Konpyūta bijon ni totte wa, ekisaitinguna jūnen desu. Shizen gengo no bunya de no daiseikō ga bijon no ryōiki ni mo utsusarete ori, ViT…

「言語モデルにアルゴリズム的な推論を教える」
Posted by Hattie Zhou, MILAの大学院生、Hanie Sedghi, Googleの研究科学者 GPT-3やPaLMなどの大規模言語モデル(LLM)は、モデルとトレーニングデータのサイズを拡大することで、近年驚異的な進歩を遂げています。それにもかかわらず、LLMが象徴的に推論できるか(すなわち、論理的なルールに基づいて記号を操作できるか)という長年の議論がありました。たとえば、LLMは、数字が小さい場合には簡単な算術演算を実行できますが、数字が大きい場合は苦労します。これは、LLMがこれらの算術演算を実行するために必要な基本的なルールを学習していないことを示唆しています。 ニューラルネットワークはパターンマッチング能力に優れていますが、データ中の偶発的な統計的パターンに過学習しやすいです。これは、トレーニングデータが大きく多様であり、評価が分布内である場合には良いパフォーマンスに影響しません。ただし、加算などのルールベースの推論を必要とするタスクでは、LLMは分布外の一般化に苦労し、トレーニングデータの偶発的な相関は真のルールベースの解決策よりもはるかに容易に利用されることがしばしばあります。その結果、さまざまな自然言語処理タスクでの重要な進展にもかかわらず、加算などの簡単な算術タスクのパフォーマンスは依然として課題のままです。MATHデータセットでのGPT-4のささやかな改善にもかかわらず、エラーは主に算術と計算のミスによるものです。したがって、重要な問題は、LLMがアルゴリズム的な推論が可能かどうかということです。アルゴリズム的な推論は、アルゴリズムを定義する一連の抽象的なルールを適用してタスクを解決することを含みます。 「コンテキスト学習を通じたアルゴリズム的な推論の教育」では、コンテキスト学習を活用してLLMにアルゴリズム的な推論能力を可能にするアプローチについて説明しています。コンテキスト学習とは、モデルがモデルのコンテキスト内でそれに関するいくつかの例を見た後にタスクを実行できる能力を指します。タスクはプロンプトを使用してモデルに指定され、重みの更新は必要ありません。また、より困難な算術問題においてプロンプトで見られるものよりも強力な一般化を実現するための革新的なアルゴリズム的プロンプティング技術を提案しています。最後に、適切なプロンプト戦略を選択することで、モデルが分布外の例でアルゴリズムを信頼性を持って実行できることを示しています。 アルゴリズム的プロンプトを提供することで、コンテキスト学習を通じてモデルに算術のルールを教えることができます。この例では、LLM(単語予測)は、簡単な加算の質問(例:267 + 197)をプロンプトとして入力すると正しい答えを出力しますが、桁数の長い類似の加算の質問に対しては失敗します。ただし、より困難な質問に加算のアルゴリズム的プロンプトを追加すると(単語予測の下に表示される青いボックスと白い+)、モデルは正しく答えることができます。さらに、モデルは一連の加算計算を合成することによって乗算アルゴリズム( X )をシミュレートすることができます。 アルゴリズムをスキルとして教える モデルにアルゴリズムをスキルとして教えるために、アルゴリズムプロンプトを開発します。これは、他の根拠に基づいたアプローチ(スクラッチパッドや思考の連鎖など)を基に構築されます。アルゴリズムプロンプトは、LLMからアルゴリズム的な推論能力を抽出し、他のプロンプトアプローチと比較して2つの注目すべき特徴があります。 1)アルゴリズミックな解決策に必要な手順を出力してタスクを解決し、2)LLMによる誤解釈の余地がないように、各アルゴリズミックな手順を十分な詳細で説明します。 アルゴリズム的なプロンプトの直感を得るために、2つの数字の加算のタスクを考えてみましょう。スクラッチパッドスタイルのプロンプトでは、右から左に各桁を処理し、各ステップでキャリー値(現在の桁が9より大きい場合は次の桁に1を追加します)を追跡します。ただし、キャリーのルールはキャリー値の数例を見た後ではあいまいです。キャリーのルールを明示するために明示的な方程式を含めると、モデルは関連する詳細に焦点を当て、プロンプトをより正確に解釈することができることがわかります。この洞察を活用して、2つの数字の加算のためのアルゴリズム的なプロンプトを開発しました。計算の各ステップに対して明示的な方程式を提供し、曖昧さのない形式でさまざまなインデックス操作を説明します。 さまざまな加算のプロンプト戦略のイラスト。 答えの桁数が最大5桁までの加算のプロンプト例を3つだけ使用して、19桁までの加算のパフォーマンスを評価します。正確性は、答えの長さに均等にサンプリングされた合計2,000の例において測定されます。以下に示すように、アルゴリズムのプロンプトの使用により、プロンプトで見られる以上に長い質問に対しても高い正確性が維持されており、モデルが入力に関係ないアルゴリズムを実行することによってタスクを解決していることが示されています。 異なるプロンプトのメソッドによる加算問題のテスト正確性の長さの増加。 アルゴリズム的なスキルを道具として活用する モデルがより一般的な推論プロセスにおいてアルゴリズミックな推論を活用できるかどうかを評価するために、学校の数学のワードプロブレム(GSM8k)を使用してパフォーマンスを評価します。具体的には、GSM8kからの加算計算をアルゴリズミックな解決策で置き換える試みを行います。…

「ICML 2023でのGoogle」
Cat Armatoさんによる投稿、Googleのプログラムマネージャー Googleは、言語、音楽、視覚処理、アルゴリズム開発などの領域で、機械学習(ML)の研究に積極的に取り組んでいます。私たちはMLシステムを構築し、言語、音楽、視覚処理、アルゴリズム開発など、さまざまな分野の深い科学的および技術的な課題を解決しています。私たちは、ツールやデータセットのオープンソース化、研究成果の公開、学会への積極的な参加を通じて、より協力的なエコシステムを広範なML研究コミュニティと構築することを目指しています。 Googleは、40回目の国際機械学習会議(ICML 2023)のダイヤモンドスポンサーとして誇りに思っています。この年次の一流学会は、この週にハワイのホノルルで開催されています。ML研究のリーダーであるGoogleは、今年の学会で120以上の採択論文を持ち、ワークショップやチュートリアルに積極的に参加しています。Googleは、LatinX in AIとWomen in Machine Learningの両ワークショップのプラチナスポンサーでもあることを誇りに思っています。私たちは、広範なML研究コミュニティとのパートナーシップを拡大し、私たちの幅広いML研究の一部を共有することを楽しみにしています。 ICML 2023に登録しましたか? 私たちは、Googleブースを訪れて、この分野で最も興味深い課題の一部を解決するために行われるエキサイティングな取り組み、創造性、楽しさについてさらに詳しく知ることを願っています。 GoogleAIのTwitterアカウントを訪れて、Googleブースの活動(デモやQ&Aセッションなど)について詳しく知ることができます。Google DeepMindのブログでは、ICML 2023での技術的な活動について学ぶことができます。 以下をご覧いただき、ICML 2023で発表されるGoogleの研究についてさらに詳しくお知りください(Googleの関連性は太字で表示されます)。 理事会および組織委員会 理事会メンバーには、Corinna Cortes、Hugo Larochelleが含まれます。チュートリアルの議長には、Hanie Sedghiが含まれます。 Google…

「ODSC APAC 2023の最初のセッションが発表されました」
8月22日から23日にかけてバーチャルで開催されるODSC APACまで、あとわずか数週間です私たちは、カンファレンスセッションの一部をお見せできることをとても楽しみにしていますあなたの経験レベルに関係なく、専門家によるワークショップ、チュートリアル、講演があります以下をチェックしてくださいデータ駆動型のワークフォースの構築...

大規模なネアデデュープリケーション:BigCodeの背後に
対象読者 大規模な文書レベルの近似除去に興味があり、ハッシュ、グラフ、テキスト処理のいくつかの理解を持つ人々。 動機 モデルにデータを供給する前にデータをきちんと扱うことは重要です。古い格言にあるように、ゴミを入れればゴミが出てきます。データ品質があまり重要ではないという幻想を作り出す見出しをつかんでいるモデル(またはAPIと言うべきか)が増えるにつれて、それがますます難しくなっています。 BigScienceとBigCodeの両方で直面する問題の1つは、ベンチマークの汚染を含む重複です。多くの重複がある場合、モデルはトレーニングデータをそのまま出力する傾向があることが示されています[1](ただし、他のドメインではそれほど明確ではありません[2])。また、重複はモデルをプライバシー攻撃に対しても脆弱にする要因となります[1]。さらに、重複除去の典型的な利点には以下があります: 効率的なトレーニング:トレーニングステップを少なくして、同じかそれ以上のパフォーマンスを達成できます[3][4]。 データ漏洩とベンチマークの汚染を防ぐ:ゼロでない重複は評価を信用できなくし、改善という主張が偽りになる可能性があります。 アクセシビリティ:私たちのほとんどは、何千ギガバイトものテキストを繰り返しダウンロードまたは転送する余裕がありません。固定サイズのデータセットに対して、重複除去は研究、転送、共同作業を容易にします。 BigScienceからBigCodeへ 近似除去のクエストに参加した経緯、結果の進展、そして途中で得た教訓について最初に共有させてください。 すべてはBigScienceがすでに数ヶ月前に始まっていたLinkedIn上の会話から始まりました。Huu Nguyenは、私のGitHubの個人プロジェクトに気付き、BigScienceのための重複除去に取り組むことに興味があるかどうか私に声をかけました。もちろん、私の答えは「はい」となりましたが、データの膨大さから単独でどれだけの努力が必要になるかは全く無知でした。 それは楽しくも挑戦的な経験でした。その大規模なデータの研究経験はほとんどなく、みんながまだ信じていたにもかかわらず、何千ドルものクラウドコンピュート予算を任せられるという意味で挑戦的でした。はい、数回マシンをオフにしたかどうかを確認するために寝床から起きなければならなかったのです。その結果、試行錯誤を通じて仕事を学びましたが、それによってBigScienceがなければ絶対に得られなかった新しい視点が開かれました。 さらに、1年後、私は学んだことをBigCodeに戻して、さらに大きなデータセットで作業をしています。英語向けにトレーニングされたLLMに加えて、重複除去がコードモデルの改善につながることも確認しました[4]。さらに、はるかに小さなデータセットを使用しています。そして今、私は学んだことを、親愛なる読者の皆さんと共有し、重複除去の視点を通じてBigCodeの裏側で何が起こっているかを感じていただければと思います。 興味がある場合、BigScienceで始めた重複除去の比較の最新バージョンをここで紹介します: これはBigCodeのために作成したコードデータセット用のものです。データセット名が利用できない場合はモデル名が使用されます。 MinHash + LSHパラメータ( P , T , K…
一度言えば十分です!単語の繰り返しはAIの向上に役立ちません
大規模言語モデル(LLM)はその能力を示し、世界中で話題になっています今や、すべての大手企業は洒落た名前を持つモデルを持っていますしかし、その裏にはすべてトランスフォーマーが動いています...

フロントエンド開発のトレンド
最先端の進歩や最高水準のイノベーションが、現在ウェブ開発の世界を形作っている様子について、私たちと一緒に深く掘り下げてみませんか
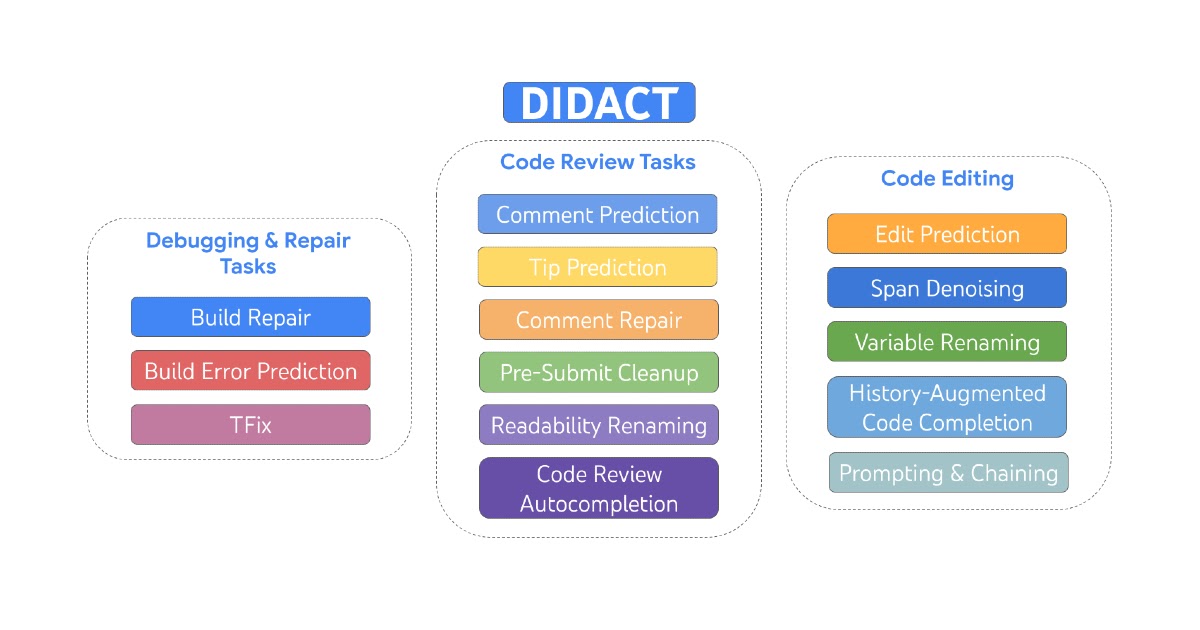
ソフトウェア開発活動のための大規模シーケンスモデル
Google の研究科学者である Petros Maniatis と Daniel Tarlow が投稿しました。 ソフトウェアは一度に作られるわけではありません。編集、ユニットテストの実行、ビルドエラーの修正、コードレビューのアドレス、編集、リンターの合意、そしてより多くのエラーの修正など、少しずつ改善されていきます。ついには、コードリポジトリにマージするに十分な良い状態になります。ソフトウェアエンジニアリングは孤立したプロセスではなく、人間の開発者、コードレビュワー、バグ報告者、ソフトウェアアーキテクト、コンパイラ、ユニットテスト、リンター、静的解析ツールなどのツールの対話です。 今日、私たちは DIDACT(Dynamic Integrated Developer ACTivity)を説明します。これは、ソフトウェア開発の大規模な機械学習(ML)モデルをトレーニングするための方法論です。 DIDACT の新規性は、完成したコードの磨き上げられた最終状態だけでなく、ソフトウェア開発のプロセス自体をトレーニングデータのソースとして使用する点にあります。開発者が作業を行う際に見るコンテキストと、それに対するアクションを組み合わせて、モデルはソフトウェア開発のダイナミクスについて学び、開発者が時間を費やす方法により合わせることができます。私たちは、Google のソフトウェア開発の計装を活用して、開発者活動データの量と多様性を以前の作品を超えて拡大しました。結果は、プロのソフトウェア開発者にとっての有用性と、一般的なソフトウェア開発スキルを ML モデルに注入する可能性という2つの側面で非常に有望です。 DIDACT は、編集、デバッグ、修復、およびコードレビューを含む開発活動をトレーニングするマルチタスクモデルです。 私たちは DIDACT Comment…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.