Learn more about Search Results GLIP

- You may be interested
- このAI論文は、それぞれの手のモデルに基...
- 「大規模言語モデルは本当にそのすべての...
- ミッドジャーニープロンプトのTシャツデザ...
- 新しいAI搭載のSQLエキスパートは、数秒で...
- 「RAGAsを使用したRAGアプリケーションの...
- 学習曲線の航行:AIの記憶保持との闘い
- 「KOSMOS-2:Microsoftによるマルチモーダ...
- 「あなたの学校の次のセキュリティガード...
- ベータ分布:ベイズ推定の基礎
- 「Unblock Your Software Engineers With ...
- NLPの探求 – NLPのキックスタート(...
- 「Nvidiaの画期的なAIイメージパーソナラ...
- Amazon SageMakerで@remoteデコレータを使...
- 「AI Time JournalがeBook「2023年の顧客...
- 「データサイエンスにおけるデータベース...
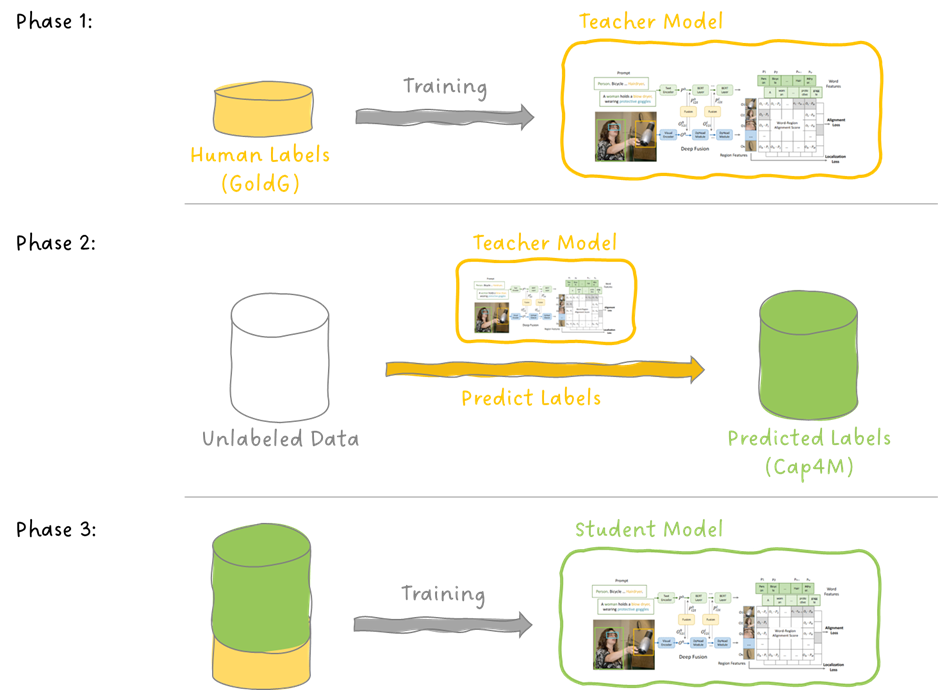
GLIP オブジェクト検出への言語-画像事前学習の導入
今日は、言語-画像の事前学習であるCLIPの素晴らしい成功を基に、物体検出のタスクに拡張した論文であるGLIPについて掘り下げます...

GoogleのAIがPaLI-3を紹介:10倍も大きい似たモデルと比べて、より小型、高速、かつ強力なビジョン言語モデル(VLM)です
ビジョン言語モデル(VLM)は、自然言語理解と画像認識の能力を組み合わせた高度な人工知能システムです。OpenAIのCLIPやGoogleのBigGANのように、VLMはテキストの説明を理解し、画像を解釈することができるため、コンピュータビジョン、コンテンツ生成、人間との対話など、さまざまな分野での応用が可能です。VLMは、視覚的なコンテキストでテキストを理解し生成する能力を示し、AIの分野で重要なテクノロジーとなっています。 Google Research、Google DeepMind、Google Cloudの研究者は、分類と対照的な目標で事前学習されたVision Transformer(ViT)モデルと比較し、特にSigLIPベースのPaLIがマルチモーダルタスクで優れた成果を上げていることを明らかにしました。研究者たちは、2兆パラメータのSigLIP画像エンコーダをスケーリングし、新たなマルチリンガルクロスモーダル検索の最先端を実現しました。彼らの研究は、分類スタイルのデータではなく、ウェブ規模の画像テキストデータでビジュアルエンコーダを事前学習することの利点を示しています。PaLI-Xのような大規模ビジョン言語モデルの分類事前学習の拡大による利点が明らかになっています。 彼らの研究では、VLMのスケーリングについて詳しく説明し、実用性と効率的な研究の重要性を強調しています。彼らは競争力のある結果を出すために、5兆パラメータのPaLI-3というモデルを導入しました。PaLI-3のトレーニングプロセスは、ウェブスケールのデータでの対照的な事前トレーニング、改善されたデータセットのミキシング、およびより高解像度のトレーニングを含んでいます。さらに、2兆パラメータのマルチリンガルな対照的なビジョンモデルも紹介されています。脱落研究は、特に位置特定や視覚に関連するテキスト理解のタスクにおいて、対照的な事前学習モデルの優越性を確認しています。 彼らのアプローチでは、事前学習済みのViTモデルを画像エンコーダとして使用し、特にViT-G14を使用しています。ViT-G14は約2兆パラメータを持ち、PaLI-3のビジョンのバックボーンとなります。対照的な事前トレーニングでは、画像とテキストを別々に埋め込み、それらの対応を分類します。ViTの出力からのビジュアルトークンは、テキストトークンと組み合わされます。これらの入力は、タスクに固有のプロンプト(VQAの質問など)によって駆動される、30億パラメータのUL2エンコーダ-デコーダ言語モデルによって処理されます。 PaLI-3は、特に位置特定と視覚的に配置されたテキストの理解において、より大きなモデルと比較して優れています。対照的な画像エンコーダの事前トレーニングを持つSigLIPベースのPaLIモデルは、新たなマルチリンガルクロスモーダル検索の最先端を確立しています。フルのPaLI-3モデルは、リファリング表現のセグメンテーションの最新技術を凌駕し、検出タスクのサブグループ全体で低いエラーレートを維持しています。対照的な事前トレーニングは、位置特定タスクにおいてより効果的です。PaLI-3のViT-G画像エンコーダは、複数の分類およびクロスモーダル検索タスクで優れています。 まとめると、彼らの研究は、SigLIPアプローチによる対照的な事前トレーニングの利点を強調し、高度で効率的なVLMを実現します。より小規模な5兆パラメータのSigLIPベースのPaLI-3モデルは、位置特定およびテキスト理解において大きなモデルよりも優れており、さまざまなマルチモーダルベンチマークで優れた成果を上げています。PaLI-3の画像エンコーダの対照的な事前トレーニングは、新たなマルチリンガルクロスモーダル検索の最先端を実現しています。彼らの研究は、画像エンコーダの事前トレーニング以外のVLMトレーニングのさまざまな側面について包括的な調査が必要であり、モデルのパフォーマンスをさらに向上させる必要性を強調しています。

9/10から15/10までの週のトップ重要なコンピュータビジョン論文
『週ごとに、いくつかのトップレベルの学術会議やジャーナルで画像などのコンピュータビジョンの革新的な研究が紹介され、さまざまなサブフィールドでのエキサイティングなブレークスルーが発表されました...』

「DINO — コンピュータビジョンのための基盤モデル」
「コンピュータビジョンにとっては、エキサイティングな10年です自然言語の分野での大成功がビジョンの領域にも移されており、ViT(ビジョントランスフォーマー)の導入などが含まれています...」(Konpyūta bijon ni totte wa, ekisaitinguna jūnen desu. Shizen gengo no bunya de no daiseikō ga bijon no ryōiki ni mo utsusarete ori, ViT…

「なんでもセグメント:任意のオブジェクトのセグメンテーションを促す」
今日の論文解説はビジュアルになります!私たちはMetaのAI研究チームによる論文「Segment Anything」を分析しますこの論文は研究コミュニティだけでなく、あらゆる分野でも話題となりました...

BYOL(Bootstrap Your Own Latent)— コントラスティブな自己教示学習の代替手段
『今日の論文分析では、BYOL(Bootstrap Your Own Latent)の背後にある論文に詳しく触れますこれは、対比的な自己教師あり学習技術の代替手法を提供します...』

UCサンタクルーズとSamsungの研究者が、ナビゲーションの決定にChatGPTのようなLLM(言語モデル)で共通センスを活用するゼロショットオブジェクトナビゲーションエージェントであるESCを紹介しました
オブジェクトナビゲーション(ObjNav)は、未知の環境で物理エージェントを事前に決められた目的のオブジェクトに案内するものです。目的のオブジェクトにナビゲートすることは、他のナビゲーションベースのエンボディドタスクにおいて重要な前提条件となります。 環境内の部屋とオブジェクトを識別する(意味的なシーン理解)ことと、コモンセンスの推論を使用して目標オブジェクトの場所を推測する(コモンセンス推論)ことは、成功したナビゲーションに不可欠な2つのスキルです。しかし、現在のゼロショットオブジェクトナビゲーション手法は、コモンセンスの推論能力に欠けており、この要件に十分に対応していません。既存の手法は、探索に対して単純なヒューリスティックを使用するか、他の目標指向型ナビゲーションタスクや周囲のトレーニングを必要とします。 最近の研究は、大規模な事前学習モデルがゼロショット学習と問題解決に優れていることを示しています。この知見に触発され、カリフォルニア大学サンタクルーズ校とサムスン研究は、Exploration with Soft Commonsense constraints(ESC)と呼ばれるゼロショットオブジェクトナビゲーションフレームワークを提案しました。このフレームワークは、事前学習済みモデルを使用して、馴染みのない設定やオブジェクト種に自動的に適応します。 チームはまず、GLIPというビジョンと言語のグラウンディングモデルを使用して、現在のエージェントの視点のオブジェクトと部屋の情報を推測するためのプロンプトベースの手法として利用します。GLIPは、画像とテキストのペアに対する広範な事前学習により、最小限のプロンプティングで新しいオブジェクトに対して容易に一般化することができます。次に、部屋とオブジェクトのデータをコンテキストとして使用する事前学習済みのコモンセンス推論言語モデルを使用して、両者の関連性を推測します。 しかし、LLMから推論されたコモンセンス知識を具体的な手順に変換する際には、まだ空白があります。また、物事のつながりの間にあるある程度の不確実性があることも珍しくありません。確率的ソフトロジック(PSL)を使用することで、このような障害を克服するために、「ソフト」コモンセンス制約をモデル化するESCのアプローチが使用されます。フロンティアベースの探索(FBE)は、これらの柔らかいコモンセンス制約を使用して、次の探索対象のフロンティアに焦点を当てる従来の戦略です。以前のアプローチでは、共通の感覚を暗黙的に刷り込むためにニューラルネットワークトレーニングに頼っていましたが、提案された手法では、ソフトロジック述語を使用して連続値空間で知識を表現し、それを各フロンティアに与えることで、より効率的な探索を促進します。 システムの効果をテストするために、研究者たちはさまざまな家のサイズ、建築スタイル、テクスチャ特徴、オブジェクトタイプを持つ3つのオブジェクト目標ナビゲーションベンチマーク(MP3D、HM3D、RoboTHOR)を使用します。調査結果は、MP3DではCoWに比べてSPL(長さによる重み付けされたSPL)およびSR(成功率)で約285%、RoboTHORでは約35%とSR(成功率)でアプローチが優れていることを示しています。この手法は、HM3Dのデータセットでのトレーニングを必要とするZSONと比較して、MP3Dでは相対的なSPLで196%、HM3Dでは相対的なSPLで85%優れています。提案されたゼロショットアプローチは、MP3Dデータセットにおいて他の最先端の教師ありアルゴリズムと比較して最も高いSPLを達成しています。

ビジョン-言語モデルへのダイブ
人間の学習は、複数の感覚を共同で活用することによって新しい情報をより良く理解し、分析することができるため、本質的にマルチモーダルです。最近のマルチモーダル学習の進歩は、このプロセスの効果的性質からインスピレーションを得て、画像、ビデオ、テキスト、音声、ボディジェスチャー、表情、生理的信号などのさまざまなモダリティを使用して情報を処理しリンクするモデルを作成することに取り組んでいます。 2021年以降、ビジョンと言語のモダリティ(またはジョイントビジョン言語モデルとも呼ばれる)を組み合わせたモデル、例えばOpenAIのCLIPなどへの関心が高まっています。ジョイントビジョン言語モデルは、画像キャプショニング、テキストによる画像生成および操作、視覚的な質問応答など、非常に困難なタスクにおいて特に印象的な能力を示しています。この分野は引き続き進化しており、ゼロショットの汎化性能向上に貢献し、さまざまな実用的なユースケースにつながっています。 このブログ記事では、ジョイントビジョン言語モデルについて、それらのトレーニング方法に焦点を当てて紹介します。また、最新の進歩をこの領域で試すために🤗 Transformersを活用する方法も示します。 目次 はじめに 学習戦略 コントラスティブラーニング PrefixLM クロスアテンションを用いたマルチモーダル融合 MLM / ITM トレーニングなし データセット 🤗 Transformersでのビジョン言語モデルのサポート 研究の新たな展開 結論 はじめに モデルを「ビジョン言語」モデルと呼ぶとはどういうことでしょうか?ビジョンと言語のモダリティの両方を組み合わせるモデルということでしょうか?しかし、それは具体的にどういう意味を持つのでしょうか? これらのモデルを定義するのに役立つ特徴の一つは、画像(ビジョン)と自然言語テキスト(言語)の両方を処理できる能力です。このプロセスは、モデルに求められる入力、出力、タスクに依存します。 たとえば、ゼロショット画像分類のタスクを考えてみましょう。入力画像といくつかのプロンプトを渡すことで、入力画像に対する最も可能性の高いプロンプトを取得します。 この猫と犬の画像はここから取得しました。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.