Learn more about Search Results Ford

- You may be interested
- アナリストによると、ジェネレーティブAI...
- 「2024年のデータ管理の未来予想:トップ4...
- 記述的な質問に対する戦略的なデータ分析&...
- 「スコア!チームNVIDIAが推薦システムで...
- 「GPTクローラーに会ってください:サイト...
- 言語の壁を乗り越える シームレスなサポー...
- 「PyTorchのネステロフモーメンタムの実装...
- アイドルアプリの自動シャットダウンを使...
- GOAT-7B-Communityモデルをご紹介します:...
- 「GCPを使用してリモートでVS Codeを操作...
- 線形プログラミングを使用して最適化問題...
- コンピュータビジョンの革新:進歩、課題...
- ‘未知に挑む検索 強化生成 (RAG) | AIが人...
- 「AIの利用者と小規模事業者を保護するた...
- Python例外テスト:クリーンで効果的な方法
In this article, we will explore the fascinating world of NOIR, Stanford University’s mind-controlled AI robot.
「物事がもうこれ以上狂ったことになり得ないと思っていたときに、スタンフォード大学が心の力で動かせるロボットを発表しましたしかし、それはどのように機能するのでしょうか?」

「ロボットがより良い判断をするにはどうすればよいのか?MITとStanfordの研究者が、高度なロボットの推論と計画のためのDiffusion-CCSPを紹介」
複雑な幾何学的および物理的制約(安定性や衝突の不足など)を満たすグラスプやオブジェクトの配置などの連続値を選択する能力は、ロボットの操作計画において重要です。従来の手法では、各種制約のサンプラーはそれぞれ個別に学習または最適化されてきましたが、複雑な問題に対しては、同時にさまざまな制約を満たす値を生成するための汎用ソルバーが必要です。 データの希少性により、すべての潜在的な要件を満たすために単一のモデルを構築またはトレーニングすることは困難です。そのため、汎用のロボットプランナーは、より大規模なジョブに対してソルバーを再利用して構築できる必要があります。 最近のMITおよびスタンフォード大学の研究では、制約グラフを使用して制約充足問題を学習された制約タイプの新しい組み合わせとして表現する統一フレームワークが提案されています。そして、拡散モデルに基づく制約ソルバーを使用して、制約を共同で満たす解を特定することができます。決定変数の例としては、掴む姿勢がありますが、配置ポーズやロボットの軌道も制約グラフのノードの例です。 新しい問題を解決するために、組成的拡散制約ソルバー(Diffusion-CCSP)は、異なる制約に対して拡散モデルのセットを学習します。次に、拡散プロセスを介して実行可能領域からさまざまなサンプルを生成することで、満足のいく割り当てを見つけるためにチューターを組み合わせます。具体的には、すべての拡散モデルは、個々の制約(たとえば、衝突を回避する位置)のための有効なソリューションを生成するようにトレーニングされます。推論時には、研究者は変数の任意の部分集合に依存して残りを解決することができます。拡散モデルは解のセットの生成モデルであるためです。各拡散モデルは、暗黙のエネルギー関数を最小化するようにトレーニングされており、グローバル制約の満足は、解のエネルギーの合計(個々の解のエネルギー関数の合計)の最小化と同等です。これらの2つの追加機能は、トレーニングおよび推論のカスタマイズに大きな余地を与えます。 別々または共同で、組成的な問題と解のペアは、成分拡散モデルのトレーニングに使用することができます。制約グラフにはトレーニング中に見られたより多くの変数が含まれていても、Diffusion-CCSPはパフォーマンス時間に既知の制約の新しい組み合わせに一般化することができます。 研究者は、Diffusion-CCSPを2次元の三角形の密なパッキング、定性的制約に従う2次元の形状配置、安定性制約に従う3次元の形状スタッキング、およびロボットを使用した3次元のアイテムパッキングなど、4つの困難なドメインでテストしました。その結果、この手法は推論速度と新しい制約の組み合わせへの一般化においてベースラインを上回ることが示されました。 チームは、この研究で調査したすべての制約が固定のアリティを持っていることを強調しています。制約と変数のアリティを考慮することは興味深いアプローチです。また、モデルが自然言語の指示を受け取ることができると有益であると考えています。さらに、タスクのラベルとソリューションを作成する現在の方法は制約があるため、特に「ダイニングテーブルを設定する」といった定性的な制限を扱う場合に制約があります。彼らは将来の発展で、より複雑な形状エンコーダと、オンラインの写真などの現実世界のデータから派生した制約を学習することで、現在と将来のアプリケーションの範囲を拡大することを提案しています。
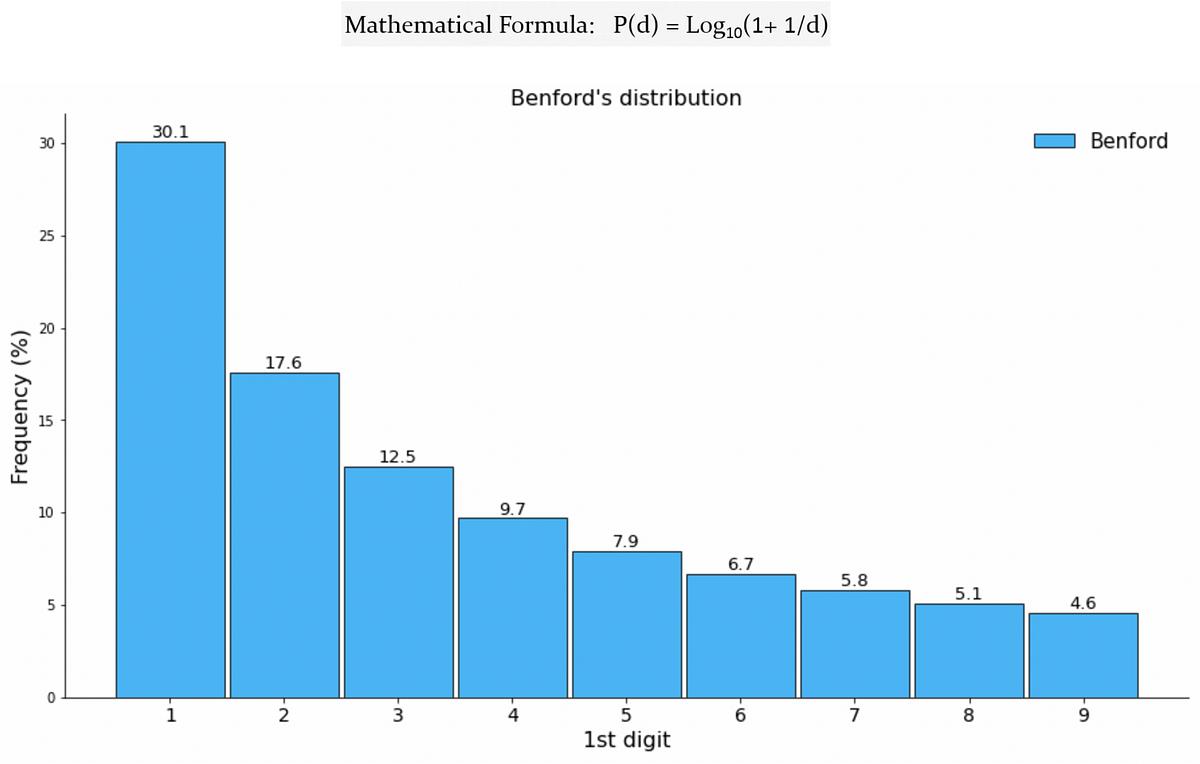
Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタル領域において、ユーザーの真正性は最も重要な懸念事項ですTwitterなどのプラットフォームが成長するにつれ、フェイクアカウントの増加も増えていますこれらのアカウントは本物のアカウントを模倣します

「2023年、オープンLLMの年」
2023年には、大型言語モデル(Large Language Models、LLMs)への公衆の関心が急増しました。これにより、多くの人々がLLMsの定義と可能性を理解し始めたため、オープンソースとクローズドソースの議論も広範な聴衆に届くようになりました。Hugging Faceでは、オープンモデルに大いに興味を持っており、オープンモデルは研究の再現性を可能にし、コミュニティがAIモデルの開発に参加できるようにし、モデルのバイアスや制約をより簡単に評価できるようにし、チェックポイントの再利用によってフィールド全体の炭素排出量を低減するなど、多くの利点があります(その他の利点もあります)。 では、オープンLLMsの今年を振り返ってみましょう! 文章が長くなりすぎないようにするために、コードモデルには触れません。 Pretrained Large Language Modelの作り方 まず、大型言語モデルはどのようにして作られるのでしょうか?(もし既に知っている場合は、このセクションをスキップしてもかまいません) モデルのアーキテクチャ(コード)は、特定の実装と数学的な形状を示しています。モデルのすべてのパラメータと、それらが入力とどのように相互作用するかがリストとして表されます。現時点では、大部分の高性能なLLMsは「デコーダーのみ」トランスフォーマーアーキテクチャのバリエーションです(詳細は元のトランスフォーマーペーパーをご覧ください)。訓練データセットには、モデルが訓練された(つまり、パラメータが学習された)すべての例と文書が含まれています。したがって、具体的には学習されたパターンが含まれます。ほとんどの場合、これらの文書にはテキストが含まれており、自然言語(例:フランス語、英語、中国語)、プログラミング言語(例:Python、C)またはテキストとして表現できる構造化データ(例:MarkdownやLaTeXの表、方程式など)のいずれかです。トークナイザは、訓練データセットからテキストを数値に変換する方法を定義します(モデルは数学的な関数であり、したがって入力として数値が必要です)。トークン化は、テキストを「トークン」と呼ばれるサブユニットに変換することによって行われます(トークン化方法によっては単語、サブワード、または文字になる場合があります)。トークナイザの語彙サイズは、トークナイザが知っている異なるトークンの数を示しますが、一般的には32kから200kの間です。データセットのサイズは、これらの個々の「原子論的」単位のシーケンスに分割された後のトークンの数としてよく測定されます。最近のデータセットのサイズは、数千億から数兆のトークンに及ぶことがあります!訓練ハイパーパラメータは、モデルの訓練方法を定義します。新しい例ごとにパラメータをどれだけ変更すべきですか?モデルの更新速度はどのくらいですか? これらのパラメータが選択されたら、モデルを訓練するためには1)大量の計算パワーが必要であり、2)有能な(そして優しい)人々が訓練を実行し監視する必要があります。訓練自体は、アーキテクチャのインスタンス化(訓練用のハードウェア上での行列の作成)および上記のハイパーパラメータを使用して訓練データセット上の訓練アルゴリズムの実行からなります。その結果、モデルの重みが得られます。これらは学習後のモデルパラメータであり、オープンな事前学習モデルへのアクセスに関して多くの人々が話す内容です。これらの重みは、推論(つまり、新しい入力の予測やテキストの生成など)に使用することができます。 事前学習済みLLMsは、重みが公開されると特定のタスクに特化または適応することもあります。それらは、「ファインチューニング」と呼ばれるプロセスを介して、ユースケースやアプリケーションの出発点として使用されます。ファインチューニングでは、異なる(通常はより専門化された小規模な)データセット上でモデルに追加の訓練ステップを適用して、特定のアプリケーションに最適化します。このステップには、計算パワーのコストがかかりますが、モデルをゼロから訓練するよりも財政的および環境的にはるかにコストがかかりません。これは、高品質のオープンソースの事前学習モデルが非常に興味深い理由の一つです。コミュニティが限られたコンピューティング予算しか利用できない場合でも、自由に使用し、拡張することができます。 2022年 – サイズの競争からデータの競争へ 2023年以前、コミュニティで利用可能だったオープンモデルはありましたか? 2022年初頭まで、機械学習のトレンドは、モデルが大きければ(つまり、パラメータが多ければ)、性能が良くなるというものでした。特に、特定のサイズの閾値を超えるモデルは能力が向上するという考えがあり、これらの概念はemergent abilitiesとscaling lawsと呼ばれました。2022年に公開されたオープンソースの事前学習モデルは、主にこのパラダイムに従っていました。 BLOOM(BigScience Large Open-science…

RAGを使用したLLMパワードアプリケーションの開始ガイド
ODSCのウェビナーでは、PandataのNicolas Decavel-Bueff、そして私(カル・アル・ドーバイブ)とData Stack AcademyのParham Parviziが協力し、エンタープライズグレードの大規模な言語モデル(LLM)の構築から学んだ教訓と、データサイエンティストとデータエンジニアが始めるためのヒントを共有しました最大の...

Sudowriteのレビュー:AIが人間らしい小説を書けるのか?
「AIは本当に人間のように小説を書くことができるのか? Sudowriteの詳細を知り、このSudowriteのレビューで真実を解明しましょう」

2024年にフォローするべきデータサイエンスのトップ12リーダー
データサイエンスの広がりを見据えると、2024年の到来は、革新を牽引し、分析の未来を形作る一握りの著名人にスポットライトを当てる重要な瞬間として迎えられます。『Top 12 Data Science Leaders List』は、これらの個人の卓越した専門知識、先見のリーダーシップ、および分野への重要な貢献を称えるビーコンとして機能します。私たちは、これらの画期的なマインドの物語、プロジェクト、そして先見の見通しをナビゲートしながら、データサイエンスの進路を形作ると約束された航跡を探求します。これらの模範的なリーダーたちは単なるパイオニアにとどまることはありません。彼らは無類のイノベーションと発見の時代へと私たちを導く先駆者そのものです。 2024年に注目すべきトップ12データサイエンスリーダーリスト 2024年への接近とともに、データサイエンスにおいて傑出した専門知識、リーダーシップ、注目すべき貢献を示す特異なグループの人々に焦点を当てています。『Top 12 Data Science Leaders List』は、これらの個人を認識し、注目することで、彼らを思想リーダー、イノベーター、およびインフルエンサーとして認め、来年重要なマイルストーンを達成することが予想されます。 さらに詳細に突入すると、これらの個人の視点、事業、イニシアチブが、さまざまなセクターを横断する複雑な課題に対するメソッドとデータの活用方法を変革することが明らかになります。予測分析の進展、倫理的なAIの実践の促進、または先進的なアルゴリズムの開発など、このリストでハイライトされた個人たちが2024年にデータサイエンスの領域に影響を与えることが期待されています。 1. Anndrew Ng 「AIのゲームにおいて、適切なビジネスコンテキストを見つけることが非常に重要です。私はテクノロジーが大好きです。それは多くの機会を提供します。しかし結局のところ、テクノロジーはコンテクスト化され、ビジネスユースケースに収まる必要があります。」 Dr. アンドリュー・エングは、機械学習(ML)と人工知能(AI)の専門知識を持つ英米のコンピュータ科学者です。AIの開発への貢献について語っている彼は、DeepLearning.AIの創設者であり、Landing AIの創設者兼CEO、AI Fundのゼネラルパートナー、およびスタンフォード大学コンピュータサイエンス学科の客員教授でもあります。さらに、彼はGoogle AIの傘下にある深層学習人工知能研究チームの創設リードでありました。また、彼はBaiduのチーフサイエンティストとして、1300人のAIグループの指導や会社のAIグローバル戦略の開発にも携わりました。 アンドリュー・エング氏は、スタンフォード大学でMOOC(大規模オープンオンラインコース)の開発をリードしました。また、Courseraを創設し、10万人以上の学生に機械学習のコースを提供しました。MLとオンライン教育の先駆者である彼は、カーネギーメロン大学、MIT、カリフォルニア大学バークレー校の学位を保持しています。さらに、彼はML、ロボット工学、関連する分野で200以上の研究論文の共著者であり、Tiime誌の世界で最も影響力のある100人のリストに選ばれています。…

スタンフォード大学とセールスフォースAIの研究者が「UniControl」という統合的な拡散モデルを発表:AI画像生成における高度な制御のための統一されたモデル
生成型の基礎モデルは、特定のタイプの入力データに似た新しいデータを生成するために設計された人工知能モデルのクラスです。これらのモデルは、自然言語処理、コンピュータビジョン、音楽生成など、さまざまな分野で使用されることがあります。彼らは、トレーニングデータから基礎となるパターンや構造を学び、その知識を使用して新しい似たようなデータを生成します。 生成型の基礎モデルは、画像合成、テキスト生成、推薦システム、薬物探索など、さまざまな応用があります。彼らは常に進化し、生成能力の向上、より多様で高品質な出力の生成、可制御性の向上、および使用に関連する倫理的な問題の理解など、その応用能力を向上させるために研究者が取り組んでいます。 Stanford大学、Northeastern大学、Salesforce AI研究所の研究者たちは、UniControlを開発しました。これは、野生での制御可能なビジュアル生成のための統一拡散モデルであり、言語とさまざまな視覚条件を同時に扱うことができます。UniControlは、複数のタスクを同時に処理し、さまざまな視覚条件をユニバーサルな表現空間にエンコードし、タスク間で共通の構造を探求する必要があります。UniControlは、他のタスクや言語プロンプトから幅広い視覚条件を受け取る必要があります。 UniControlは、視覚要素が主な役割を果たし、言語のプロンプトがスタイルと文脈を指示することにより、ピクセルパーフェクトな精度で画像の生成を提供します。研究チームは、UniControlがさまざまな視覚シナリオを管理する能力を向上させるために、事前学習されたテキストから画像への拡散モデルを拡大しました。さらに、彼らはタスクに関する認識能力を持つHyperNetを組み込み、異なる視覚条件に基づいて複数の画像生成タスクに適応することができるようにしました。 彼らのモデルは、ControlNetよりも3Dジオメトリガイドの深さマップや表面法線の微妙な理解を示しています。深さマップ条件により、より正確な出力が生じます。セグメンテーション、openpose、および物体のバウンディングボックスのタスク中、彼らのモデルによって生成された画像は、ControlNetによって生成された画像よりも与えられた条件によりよく整列し、入力プロンプトに対して高い忠実度を確保します。実験結果は、UniControlが同等のモデルサイズを持つ単一タスク制御法の性能をしばしば上回ることを示しています。 UniControlは、ControlNetのさまざまな視覚条件を統合し、新たに見たことのないタスクでゼロショット学習を実行することができます。現在のところ、UniControlは単一の視覚条件のみを受け入れるが、複数のタスクを同時に実行し、ゼロショット学習も可能です。これは、その汎用性と広範な採用の可能性を示しています。 ただし、彼らのモデルはまだ拡散ベースの画像生成モデルの制限を継承しています。具体的には、研究者のトレーニングデータはLaion-Aestheticsデータセットの一部から取得されたものであり、データバイアスがかかっています。UniControlは、バイアスのある、有毒な、性的な、または他の有害なコンテンツの作成をブロックするために、より良いオープンソースのデータセットが利用可能であれば改善することができます。

「Pythonを学ぶための5つの無料大学講座」
Pythonプログラミングを学ぶ最高のリソースをお探しですか? これらの無料の大学のコースをチェックしてみてください

「04/12から10/12までの週のトップ重要なLLM論文」
大型言語モデル(LLM)は最近急速に進化しています新しいモデルの世代が開発されるにつれて、研究者やエンジニアは最新の進歩について情報を得る必要がありますこの記事は…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.