Learn more about Search Results Eloレーティング

- You may be interested
- 次世代のコンピューティング:NVIDIAとAMD...
- アルゴリズムの効率をマスターする
- Airbnbの研究者がChrononを開発:機械学習...
- 「クリスマスラッシュ」3Dシーンが今週の...
- 次のLangChainプロジェクトのための基本を...
- 素晴らしい応用(データ)科学の仕事
- 「GPT-4とXGBoost 2.0の詳細な情報:AIの...
- ビデオゲームの世界でインタラクティブな...
- 「QLoRAを使ってLlama 2を微調整し、AWS I...
- 「RAVENに会ってください:ATLASの制限に...
- 「MLを学ぶ勇気:L1とL2の正則化の解明(...
- なぜMetaが非常に強力なAIモデルを無料で...
- Google DeepMindの研究者たちは、人工汎用...
- 黄金時代:『エイジ オブ エンパイア III...
- バーゼル大学病院が、「TotalSegmentator...
2v2ゲームのためのデータ駆動型Eloレーティングシステムの作成方法
「2v2のEloベースのスコアリングシステムを探索しましょうフーズボールやマルチプレイヤーゲームに最適です数学、データベースモデリング、およびその応用を発見してください」

「LLMを評価するためのより良い方法」
この記事は、NLPタスクによってカテゴリ分けされたリアルワールドのユーザープロンプトに対するLLMの応答を比較し、人間の洞察を活用したLLM評価の新しいアプローチを紹介していますこれは、LLM評価基準の向上に向けた有望な解決策を提供しています

LMSYS ORG プレゼント チャットボット・アリーナ:匿名でランダムなバトルを行うクラウドソーシング型 LLM ベンチマーク・プラットフォーム
多くのオープンソースプロジェクトは、特定のタスクを実行するためにトレーニングできる包括的な言語モデルを開発しています。これらのモデルは、ユーザーからの質問やコマンドに有用な応答を提供することができます。注目すべき例には、LLaMAベースのアルパカとビクーナ、およびPythiaベースのOpenAssistantとDollyがあります。 毎週新しいモデルがリリースされているにもかかわらず、コミュニティはまだ適切にベンチマークを行うことに苦労しています。LLMアシスタントの関心事はしばしば曖昧なため、回答の品質を自動的に評価できるベンチマークシステムを作成することは困難です。ここでは、対称比較に基づいたスケーラブルで増分的かつ独自のベンチマークシステムが理想的です。 現在のLLMベンチマークシステムのうち、これらの要件をすべて満たすものはほとんどありません。HELMやlm-evaluation-harnessなどの従来のLLMベンチマークフレームワークは、研究基準のタスクに対する複数のメトリック測定を提供します。ただし、対称比較に基づいていないため、自由形式の質問を適切に評価することはありません。 LMSYS ORGは、オープンでスケーラブルかつアクセス可能な大規模なモデルとシステムを開発する組織です。彼らの新しい取り組みであるChatbot Arenaは、匿名でランダムなバトルが行われるクラウドソーシングのLLMベンチマークプラットフォームを提供しています。チェスや他の競技ゲームと同様に、Chatbot ArenaではEloレーティングシステムが採用されています。Eloレーティングシステムは、前述の望ましい品質を提供する可能性があります。 彼らは1週間前にアリーナをオープンし、多くの有名なオープンソースLLMと共に情報を収集し始めました。LLMの実世界の応用例は、クラウドソーシングのデータ収集方法で確認することができます。ユーザーはアリーナで同時に2つの匿名モデルとチャットしながら、それらを比較対照することができます。 マルチモデルサービングシステムであるFastChatは、https://arena.lmsys.orgでアリーナをホストしています。アリーナに入場すると、匿名の2つのモデルとの会話に直面します。ユーザーが両方のモデルからコメントを受け取ると、会話を続けるか、どちらが好きかを投票することができます。投票が行われると、モデルの正体が明らかになります。ユーザーは同じ2つの匿名モデルと会話を続けたり、2つの新しいモデルとの新たなバトルを開始したりすることができます。システムはすべてのユーザーアクティビティを記録します。分析で投票が見えなくなるまで、モデル名は隠されます。アリーナがオープンしてから1週間で、約7,000件の合法的な匿名投票が集計されました。 将来的には、より多様なモデルを収容し、さまざまなタスクに対して詳細なランクを提供するために、改良されたサンプリングアルゴリズム、トーナメント手順、およびサービングシステムを実装したいと考えています。

「エローの有名なレーティングシステムに不確実性を加えるための記号的回帰の使用」
Eloレーティングシステムは、いくつかの文脈で有名になっていますおそらく最も有名なのは、1960年代以来、チェスのレーティングの基礎となってきたことですさらに、ウェブサイト538は成功裡に利用されています...
このツールを使用することで、プロンプトエンジニアリングのテストを簡素化します
「プロンプトエンジニアリングは、AIモデルに入力するための手法と最適化のプロセスです大規模言語モデルでは、プロンプトエンジニアリングは、生成するために入力する文やフレーズを最適化することを指します...」

⚔️AI vs. AI⚔️は、深層強化学習マルチエージェント競技システムを紹介します
私たちは新しいツールを紹介するのを楽しみにしています: ⚔️ AI vs. AI ⚔️、深層強化学習マルチエージェント競技システム。 このツールはSpacesでホストされており、マルチエージェント競技を作成することができます。以下の3つの要素で構成されています: マッチメイキングアルゴリズムを使用してモデルの戦いをバックグラウンドタスクで実行するスペース。 結果を含むデータセット。 マッチ履歴の結果を取得し、モデルのELOを表示するリーダーボード。 ユーザーが訓練済みモデルをHubにアップロードすると、他のモデルと評価およびランキング付けされます。これにより、マルチエージェント環境で他のエージェントとの評価が可能です。 マルチエージェント競技をホストする有用なツールであるだけでなく、このツールはマルチエージェント環境での堅牢な評価技術でもあると考えています。多くのポリシーと対戦することで、エージェントは幅広い振る舞いに対して評価されます。これにより、ポリシーの品質を良く把握することができます。 最初の競技ホストであるSoccerTwos Challengeでどのように機能するか見てみましょう。 AI vs. AIはどのように機能しますか? AI vs. AIは、Hugging Faceで開発されたオープンソースのツールで、マルチエージェント環境での強化学習モデルの強さをランク付けするためのものです。 アイデアは、モデルを継続的に互いに対戦させ、その結果を使用して他のすべてのモデルと比較してパフォーマンスを評価し、ポリシーの品質を把握するための相対的なスキルの尺度を得ることです。従来のメトリクスを必要とせずに。 エージェントが特定のタスクや環境に提出される数が増えるほど、ランキングはより代表的になります。 競争環境での試合結果に基づいて評価を生成するために、私たちはELOレーティングシステムを基にランキングを作成することにしました。…
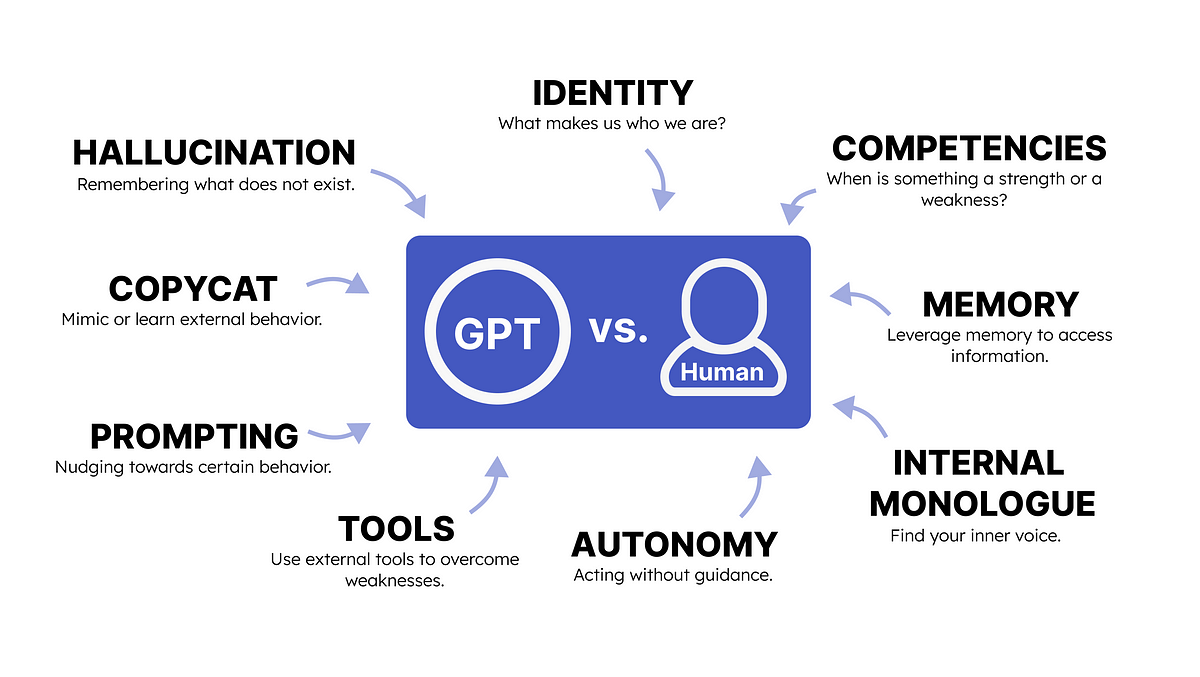
GPTと人間の心理学
GPTと人間の心理学との類推を行うことで、私たちは生成型AIの出力を促進する方法を理解することができます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.