Learn more about Search Results Ego4D

- You may be interested
- 高度なグラフニューラルネットワークを使...
- 「ChatGPTエンタープライズ- LLMが行った...
- 学習曲線の航行:AIの記憶保持との闘い
- 「Amazon Personalizeと生成AIでマーケテ...
- 「AIを暴走させようとするハッカーたちに...
- 『React開発の向上:ChatGPTの力を解き放...
- 「データと分析について非データの人々と...
- COSPとUSPの内部:GoogleがLLMsの推論を進...
- 「トップAIランダム顔生成アプリ(2023年)」
- 「AIデータ統合とコンテンツベースのマッ...
- RecList 2.0 オープンソースによるMLモデ...
- 何が合成データとは?その種類、機械学習...
- ChatGPTを使ってコーディングする方法R...
- AIがVRデバイスのユーザーエクスペリエン...
- 「Google Sheetsにおける探索的データ分析」

Google AIは、屋外での人間の視点によるシーン理解のためのマルチ属性ビデオデータセットであるSANPOを導入しました
自動運転などのタスクにおいて、AIモデルは道路や歩道の3D構造だけでなく、道路標識や信号機を識別・認識する必要があります。このようなタスクは、自動車に取り付けられた特殊なレーザーが3Dデータをキャプチャすることで容易に行われます。このようなプロセスは、エゴセントリックシーン理解と呼ばれ、自身の視点から環境を理解することを意味します。問題は、エゴセントリックな人間のシーン理解に適用できる公開データセットが自動運転領域を超えて存在しないことです。 Googleの研究者たちは、人間のエゴセントリックなシーン理解のためのマルチ属性ビデオデータセットであるSANPO(Scene understanding, Accessibility, Navigation, Pathfinding, Obstacle avoidance)データセットを導入しました。SANPOには、SANPO-RealとSANPO-Syntheticの2つの実世界データと合成データが含まれています。SANPO-Realは多様な環境をカバーしており、マルチビュー手法をサポートするために2つのステレオカメラからのビデオが含まれています。実データセットには、15フレーム/秒(FPS)でキャプチャされた11.4時間のビデオと密な注釈が含まれています。 SANPOは、エゴセントリックな人間のシーン理解のための大規模なビデオデータセットであり、密な予測注釈を持つ60万以上の実世界および10万以上の合成フレームから成り立っています。 Googleの研究者たちは、プライバシー保護を優先しています。彼らは現地、市、および州の法律に従ってデータを収集しています。また、注釈のためにデータを送信する前に、顔や車両ナンバープレートなどの個人情報を削除するようにしています。 ビデオのキャプチャ中のモーションブラー、人間の評価ミスなどの欠点を克服するために、SANPO-Syntheticが導入されました。研究者は、実世界の環境に合わせて最適化された高品質な合成データセットを作成するために、Parallel Domainと提携しました。SANPO-Syntheticには、バーチャル化されたZedカメラを使用して記録された1961のセッションが含まれており、ヘッドマウントとチェストマウントの位置の均等な分布があります。 合成データセットと一部の実データセットは、パノプティックインスタンスマスクを使用して注釈が付けられました。SANPO-Realでは、フレームごとに20を超えるインスタンスがあるのはわずかです。それに対して、SANPO-Syntheticには実データセットよりもずっと多くのインスタンスが含まれています。 この分野での他の重要なビデオデータセットには、SCAND、MuSoHu、Ego4D、VIPSeg、Waymo Openなどがあります。SANPOはこれらのデータセットと比較され、パノプティックマスク、深度、カメラ姿勢、マルチビューステレオ、実データと合成データを兼ね備える最初のデータセットです。SANPOの他に、パノプティックセグメンテーションと深度マップを兼ね備えたデータセットはWaymo Openだけです。 研究者は、SANPOデータセット上で2つの最先端モデル、BinsFormer(深度推定)とkMaX-DeepLab(パノプティックセグメンテーション)を訓練しました。彼らは、このデータセットは両方の密な予測タスクにとって非常に挑戦的であることを観察しました。また、合成データセットの方が実データセットよりも精度が高いことも確認されました。これは、現実世界の環境が合成データよりも複雑であるためです。さらに、セグメンテーション注釈においては、合成データの方がより正確です。 人間のエゴセントリックなシーン理解のデータセットの不足に対処するために導入されたSANPOは、実世界と合成データセットの両方を網羅しており、密な注釈、マルチ属性の特徴、パノプティックセグメンテーションと深度情報のユニークな組み合わせによって他のデータセットとは異なる存在です。さらに、研究者たちのプライバシーへの取り組みは、視覚障害者のための視覚ナビゲーションシステムの開発をサポートし、高度な視覚シーン理解の可能性を広げるために、このデータセットを他の研究者に提供することができます。

大規模言語モデルは、ビデオからの長期行動予測に役立ちますか?AntGPTをご紹介します:ビデオベースの長期行動予測タスクにおいて大規模言語モデルを組み込むためのAIフレームワークです
ビデオの観察から、研究はLTAタスク(長期アクション予測)に焦点を当てています。一般的に長期的な時間軸を超えて興味のあるアクターのための動詞と名詞の予測の連続が望ましい結果です。LTAは人間と機械のコミュニケーションにおいて重要です。自動運転車や日常の家事などの状況で、機械エージェントはLTAを使用して人々を支援する可能性があります。また、人間の行動の曖昧さや予測不可能性により、ビデオのアクション検出は非常に困難です。 ボトムアップモデリングは、一般的なLTA戦略の一つで、潜在的な視覚表現や離散的なアクションラベルを使用して人間の行動の時間的ダイナミクスを直接シミュレートします。現在のほとんどのボトムアップLTA戦略は、視覚入力を使用したエンドツーエンドでトレーニングされたニューラルネットワークとして実装されています。アクターの目標を知ることはアクションの予測に役立つかもしれません。特に日常の家庭の状況では人間の行動はしばしば「目的を持っている」です。そのため、広く使用されるボトムアップ戦略に加えて、トップダウンのフレームワークも考慮しています。トップダウンのフレームワークでは、まず目標を達成するために必要なプロセスを概説し、それによって人間のアクターの長期的な目標を示唆します。 ただし、目標指向のプロセス計画をアクション予測に使用するのは通常困難です。なぜなら、ターゲット情報が現在のLTAの標準ではしばしば未ラベル化されており、潜在的です。彼らの研究では、トップダウンとボトムアップのLTAの両方でこれらの問題に取り組んでいます。彼らは、大規模な言語モデル(LLMs)が映画から利益を得ることができるかどうかを調べることを提案しています。なぜなら、LLMsはロボット計画やプログラムベースのビジュアル質問応答において成功しているためです。彼らは、レシピなどの手順テキスト素材で事前トレーニングされたことにより、LLMsが長期的なアクション予測の仕事に対して有用な事前情報をエンコードすることを提案しています。 理想的なシナリオでは、LLMsにエンコードされた事前知識はボトムアップおよびトップダウンのLTAアプローチの両方を支援できます。なぜなら、これらのモデルは「現在のアクションの後に最も可能性の高いアクションは何ですか?」といった質問に応えることができるだけでなく、「アクターが何を達成しようとしており、目標を達成するための残りの手順は何ですか?」といった質問にも応えることができるからです。彼らの研究は、LLMsを長期的なアクション予測に使用するための以下の4つの問いに答えることを目指しています。まず、ビデオとLLMsの間のLTA作業に適切なインターフェースは何ですか?次に、LLMsはトップダウンのLTAに有用であり、目標を推測できますか?アクションの予測は、LLMsの時間的ダイナミクスに関する事前知識によって支援される可能性がありますか?最後に、LLMsのインコンテキスト学習機能によって提供される少数のショットLTA機能を使用できますか? ブラウン大学と本田技術研究所の研究者は、これらの質問に答えるために必要な定量的および定性的評価を行うためのAntGPTという2段階のシステムを提供しています。AntGPTはまず、教師付きアクション認識アルゴリズムを使用して人間の活動を識別します。その後、OpenAI GPTモデルによって認識されたアクションがアクションの意図した結果または今後のアクションに変換され、オプションで最終的な予測に後処理されます。ボトムアップLTAでは、GPTモデルに対して自己回帰的な方法、ファインチューニング、またはインコンテキスト学習を使用して将来のアクションのシーケンスを予測するよう明示的に依頼します。彼らはまずGPTにアクターの目標を予測させ、その後アクターの行動を生成してトップダウンのLTAを達成します。 彼らはまた、目標情報を使用して目標条件付きの予測を行います。さらに、推論のチェーンと少数のショットボトムアップLTAを使用して、AntGPTのトップダウンおよびボトムアップLTAの能力を評価しています。彼らはEGTEA GAZE+、EPIC-Kitchens-55、Ego4DなどのいくつかのLTAベンチマークでテストを実施しています。定量的なテストは彼らの提案されたAntGPTの実現可能性を示しています。さらに、定量的および定性的な研究により、LLMsがビデオの観察からの離散的なアクションラベルを使用してアクターの高レベルの目標を推測することができることが示されています。さらに、LLMsはさまざまな目標を与えられた場合にカウンターファクトアルなアクション予測を実行することができることにも注目しています。 彼らの研究は以下の貢献をしています: 1. 大規模な言語モデルを使用して目標を推測し、時間的ダイナミクスをモデル化し、長期的なアクション予測をボトムアップおよびトップダウンの方法として定義することを提案します。 2. LLMsとコンピュータビジョンアルゴリズムを自然に結び付けるAntGPTフレームワークを提案し、EPIC-Kitchens-55、EGTEA GAZE+、Ego4D LTA v1およびv2のベンチマークにおいて最先端の長期的なアクション予測性能を達成します。 3. LTAの業務に使用される場合、LLMsの重要な設計上の決定、利点、欠点を理解するために、包括的な定量的および定性的評価を実施します。また、彼らはまもなくコードを公開する予定です。

複雑なタスクの実行におけるロボットの強化:Meta AIが人間の行動のインターネット動画を使用して視覚的な手がかりモデルを開発する
メタAIは、先進的な人工知能(AI)研究機関であり、最近、ロボティクスの分野を革命的に変えると約束する画期的なアルゴリズムを発表しました。彼らの研究論文「ロボティクスのためのヒューマンビデオからの利用価値:ユーザビリティの高い表現」というタイトルで、著者たちはYouTubeビデオをロボットが人間の動作を学び、複製するための強力なトレーニングツールとしての応用を探求しています。オンラインの教育ビデオの膨大なリソースを活用することで、この最先端のアルゴリズムは、静的なデータセットと現実世界のロボットアプリケーションの間のギャップを埋め、ロボットがより柔軟性と適応性を持って複雑なタスクを実行できるようにすることを目指しています。 この革新的なアプローチの中心にあるのは、「利用価値」という概念です。利用価値は、オブジェクトや環境が提供する潜在的なアクションや相互作用を表します。人間のビデオの分析を通じてロボットにこれらの利用価値を理解し、活用するように訓練することで、メタAIのアルゴリズムは、さまざまな複雑なタスクの実行方法についての柔軟な表現をロボットに提供します。このブレイクスルーにより、ロボットは人間の動作を模倣する能力が向上し、獲得した知識を新しい未知の環境で適用することができるようになります。 この利用価値ベースのモデルをロボットの学習プロセスにシームレスに統合するために、メタAIの研究者たちは、それをオフラインの模倣学習、探索、ゴール条件付き学習、強化学習のためのアクションパラメータ化など、4つの異なるロボット学習パラダイムに取り入れています。利用価値認識の力をこれらの学習手法と組み合わせることにより、ロボットは新しいスキルを獲得し、より精度と効率性を持ってタスクを実行することができます。 利用価値モデルを効果的にトレーニングするために、メタAIはEgo4DやEpic Kitchensなどの大規模な人間ビデオデータセットを利用しています。これらのビデオを分析することで、研究者たちは既製の手-物体相互作用検出器を使用して接触領域を識別し、接触後の手首の軌跡を追跡します。しかし、シーン内の人間の存在が分布のシフトを引き起こすという重大な課題が生じます。この障害を克服するために、研究者たちは利用可能なカメラ情報を活用して接触点と接触後の軌跡を人間非依存のフレームに投影し、それを入力としてモデルに使用します。 このブレイクスルー以前、ロボットはアクションを模倣する能力に制約があり、主に特定の環境の複製に限定されていました。しかし、メタAIの最新のアルゴリズムにより、ロボットのアクションの一般化において大きな進歩が実現されました。これは、ロボットが獲得した知識を新しい未知の環境で適用できることを意味します。メタAIは、コンピュータビジョンの分野の発展と研究者や開発者間の協力を推進することを約束しています。このコミットメントに沿って、組織は自身のプロジェクトからコードとデータセットを共有する予定です。これらのリソースを他の人々にアクセス可能にすることで、メタAIはこの技術のさらなる探求と開発を促進することを目指しています。このオープンなアプローチにより、YouTubeビデオから新しいスキルと知識を獲得できるセルフラーニングロボットの開発が可能になり、ロボティクスの分野が新たなイノベーションの領域に進化します。
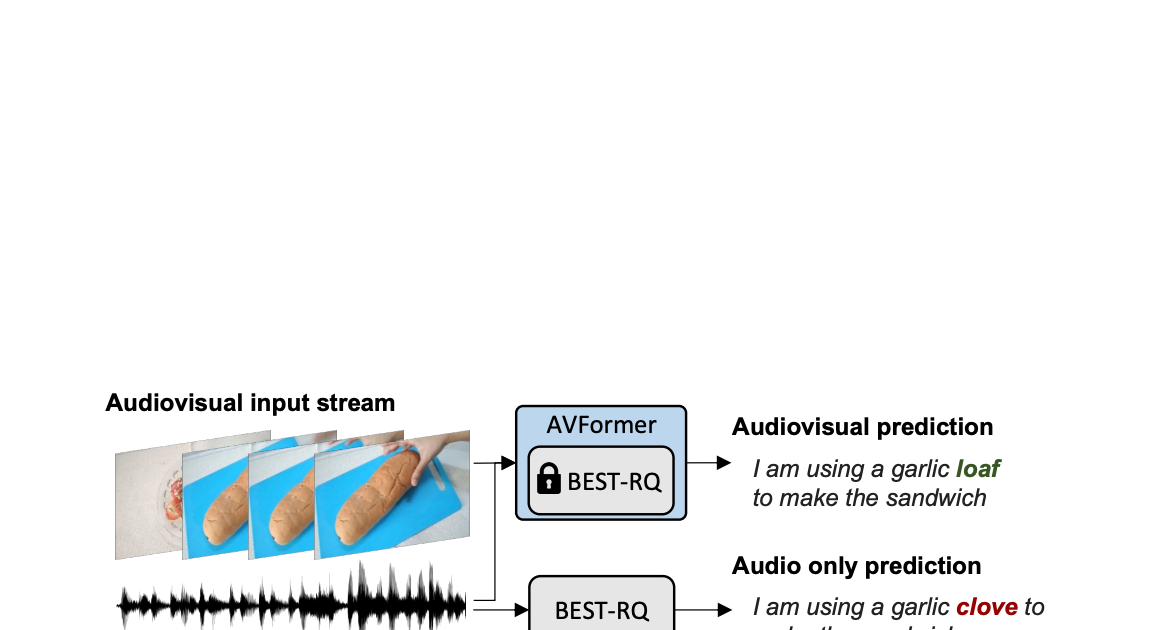
AVFormer:凍結した音声モデルにビジョンを注入して、ゼロショットAV-ASRを実現する
Google Researchの研究科学者、Arsha NagraniとPaul Hongsuck Seoによる投稿 自動音声認識(ASR)は、会議通話、ストリームビデオの転写、音声コマンドなど、さまざまなアプリケーションで広く採用されている確立された技術です。この技術の課題は、ノイズのあるオーディオ入力に集中していますが、マルチモーダルビデオ(テレビ、オンライン編集ビデオなど)の視覚ストリームはASRシステムの堅牢性を向上させる強力な手がかりを提供することができます。これをオーディオビジュアルASR(AV-ASR)と呼びます。 唇の動きは音声認識に強力な信号を提供し、AV-ASRの最も一般的な焦点であるが、野外のビデオで口が直接見えないことがよくあります(例えば、自己中心的な視点、顔のカバー、低解像度など)ため、新しい研究領域である拘束のないAV-ASR(AVATARなど)が誕生し、口の領域だけでなく、ビジュアルフレーム全体の貢献を調査しています。 ただし、AV-ASRモデルをトレーニングするためのオーディオビジュアルデータセットを構築することは困難です。How2やVisSpeechなどのデータセットはオンラインの教育ビデオから作成されていますが、サイズが小さいため、モデル自体は通常、ビジュアルエンコーダーとオーディオエンコーダーの両方から構成され、これらの小さなデータセットで過剰適合する傾向があります。それにもかかわらず、オーディオブックから取得した大量のオーディオデータを用いた大規模なトレーニングによって強く最適化された最近リリースされた大規模なオーディオモデルがいくつかあります。LibriLightやLibriSpeechなどがあります。これらのモデルには数十億のパラメータが含まれ、すぐに利用可能であり、ドメイン間で強い汎化性能を示します。 上記の課題を考慮して、私たちは「AVFormer:ゼロショットAV-ASRの凍結音声モデルにビジョンを注入する」と題した論文で、既存の大規模なオーディオモデルにビジュアル情報を付加するシンプルな方法を提案しています。同時に、軽量のドメイン適応を行います。AVFormerは、軽量のトレーニング可能なアダプタを使用して、視覚的な埋め込みを凍結されたASRモデルに注入します(Flamingoが大規模な言語モデルに視覚テキストタスクのためのビジュアル情報を注入する方法と似ています)。これにより、最小限の追加トレーニング時間とパラメータで弱くラベル付けられた少量のビデオデータでトレーニング可能です。トレーニング中のシンプルなカリキュラムスキームも紹介し、オーディオとビジュアルの情報を効果的に共同処理できるようにするために重要であることを示します。その結果、AVFormerモデルは、3つの異なるAV-ASRベンチマーク(How2、VisSpeech、Ego4D)で最新のゼロショットパフォーマンスを達成し、同時に伝統的なオーディオのみの音声認識ベンチマーク(LibriSpeechなど)のまともなパフォーマンスを保持しています。 拘束のないオーディオビジュアル音声認識。軽量モジュールを使用して、ビジョンを注入して、オーディオビジュアルASRのゼロショットを実現するために、Best-RQ(灰色)の凍結音声モデルにビジョンを注入します。AVFormer(青)というパラメーターとデータ効率の高いモデルが作成されます。オーディオ信号がノイズの場合、視覚的なパンの生成トランスクリプトでオンリーミステイク「クローブ」を「ローフ」に修正するのに役立つ視覚的なパンが役立つ場合があります。 軽量モジュールを使用してビジョンを注入する 私たちの目標は、既存のオーディオのみのASRモデルにビジュアル理解能力を追加しながら、その汎化性能を各ドメイン(AVおよびオーディオのみのドメイン)に維持することです。 このために、既存の最新のASRモデル(Best-RQ)に次の2つのコンポーネントを追加します:(i)線形ビジュアルプロジェクター、および(ii)軽量アダプター。前者は、オーディオトークン埋め込みスペースにおける視覚的な特徴を投影します。このプロセスにより、別々に事前トレーニングされたビジュアル機能とオーディオ入力トークン表現を適切に接続することができます。後者は、その後最小限の変更で、ビデオのマルチモーダル入力を理解するためにモデルを変更します。その後、これらの追加モジュールを、HowTo100Mデータセットからのラベル付けされていないWebビデオとASRモデルの出力を擬似グラウンドトゥルースとして使用してトレーニングし、Best-RQモデルの残りを凍結します。このような軽量モジュールにより、データ効率と強力なパフォーマンスの汎化が可能になります。 我々は、AV-ASRベンチマークにおいて、モデルが人手で注釈付けされたAV-ASRデータセットで一度もトレーニングされていないゼロショット設定で、拡張モデルを評価しました。 ビジョン注入のためのカリキュラム学習 初期評価後、私たちは経験的に、単純な一回の共同トレーニングでは、モデルがアダプタとビジュアルプロジェクタの両方を一度に学習するのが困難であることがわかりました。この問題を緩和するために、私たちは、これら2つの要因を分離し、ネットワークを順序良くトレーニングする2段階のカリキュラム学習戦略を導入しました。最初の段階では、アダプタパラメータが全くフィードされずに最適化されます。アダプタがトレーニングされたら、ビジュアルトークンを追加し、トレーニング済みのアダプタを凍結したまま第2段階でビジュアルプロジェクションレイヤーのみをトレーニングします。 最初の段階は、音声ドメイン適応に焦点を当てています。第2段階では、アダプタが完全に凍結され、ビジュアルプロジェクタは、ビジュアルトークンをオーディオ空間に投影するためのビジュアルプロンプトを生成することを学習する必要があります。このように、私たちのカリキュラム学習戦略は、モデルがAV-ASRベンチマークでビジュアル入力を統合し、新しい音声ドメインに適応することを可能にします。私たちは、交互に適用する反復的な適用では性能が低下するため、各段階を1回だけ適用します。 AVFormerの全体的なアーキテクチャとトレーニング手順。アーキテクチャは、凍結されたConformerエンコーダー・デコーダーモデル、凍結されたCLIPエンコーダー(グレーのロックシンボルで示される凍結層を持つ)、および2つの軽量トレーニング可能なモジュールで構成されています。-(i)ビジュアルプロジェクションレイヤー(オレンジ)およびボトルネックアダプタ(青)を有効にし、多モーダルドメイン適応を可能にします。私たちは、2段階のカリキュラム学習戦略を提案しています。最初に、アダプタ(青)をビジュアルトークンなしでトレーニングします。その後、ビジュアルプロジェクションレイヤー(オレンジ)を調整し、他のすべての部分を凍結したままトレーニングします。 下のプロットは、カリキュラム学習なしでは、AV-ASRモデルがすべてのデータセットでオーディオのみのベースラインよりも劣っており、より多くのビジュアルトークンが追加されるにつれてその差が拡大することを示しています。一方、提案された2段階のカリキュラムが適用されると、AV-ASRモデルは、オーディオのみのベースラインよりも遥かに優れたパフォーマンスを発揮します。 カリキュラム学習の効果。赤と青の線はオーディオビジュアルモデルであり、ゼロショット設定で3つのデータセットに表示されます(WER%が低い方が良いです)。カリキュラムを使用すると、すべての3つのデータセットで改善します(How2(a)およびEgo4D(c)では、オーディオのみのパフォーマンスを上回るために重要です)。4つのビジュアルトークンまで性能が向上し、それ以降は飽和します。 ゼロショットAV-ASRでの結果 私たちは、How2、VisSpeech、Ego4Dの3つのAV-ASRベンチマークで、zero-shotパフォーマンスのために、BEST-RQ、私たちのモデルの音声バージョン、およびAVATARを比較しました。AVFormerは、すべてのベンチマークでAVATARとBEST-RQを上回り、BEST-RQでは600Mパラメータをトレーニングする必要がありますが、AVFormerはわずか4Mパラメータしかトレーニングせず、トレーニングデータセットのわずか5%しか必要としません。さらに、音声のみのLibriSpeechでのパフォーマンスも評価し、AVFormerは両方のベースラインを上回ります。 AV-ASRデータセット全体におけるゼロショット性能に対する最新手法との比較。音声のみのLibriSpeechのパフォーマンスも示します。結果はWER%(低い方が良い)として報告されています。 AVATARとBEST-RQはHowTo100Mでエンドツーエンド(すべてのパラメータ)で微調整されていますが、AVFormerは微調整されたパラメータの少ないセットのおかげで、データセットの5%でも効果的に機能します。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.