Learn more about Search Results ELIZA

- You may be interested
- Plotlyを使用してマッププロットを作成す...
- この中国のAI研究は、ベートーヴェン、ク...
- 最適なテクノロジー/ベンダーを選ぶための...
- GoogleのAIがPaLI-3を紹介:10倍も大きい...
- 無料のオープンパスでODSC West Virtualに...
- 「25,000台のコンピュータがChatGPTを訓練...
- 「LangChainとOpenAI GPTを使用して初めて...
- インテルの研究者たちは、CPU上でLLMs(La...
- 「ビッグデータパイプラインのデータ品質...
- 「脳のように機能するコンピュータビジョ...
- 「透明なセンサーが視線追跡を目に見えな...
- 「データとテクノロジーのリーダーシップ...
- 「高次元におけるデータの驚くべき挙動」
- ニューラルネットワークは人間のような言...
- 「あなた自身のODSCウエストスケジュール...

「チャットボットとAIアシスタントの構築」
この記事は、自然言語処理(NLP)とチャットボットフレームワークの総合ガイドを紹介します詳しくは、学んでください!

次元性の祝福?!(パート1)
「これらの問題の1つまたは複数について、慎重に選ばれた科学者のグループが夏に一緒に取り組めば、重要な進展が期待できると私たちは考えています」と提案は述べましたジョンはまだ知りませんでしたが...

「GBMとXGBoostの違いって何だ?」
有名なアルゴリズム間の実質的な違いをご覧ください (Yūmei na arugorizumu-kan no jitsubutsuteki na chigai o goran kudasai.)

なぜハイプが重要なのか:AIについて現実的な考え方が必要
ELIZAはChatGPTにいくつかの類似点を持つ初期のチャットボットでしたなぜこの興奮が重要なのでしょうか?船を発明すると、船難も起こります

「架空の世界から現実へ:ChatGPTと真のAI会話のSF夢」
「SFの夢は現実になったのか?」

UCSDの研究者が、チューリングテストでのGPT-4のパフォーマンスを評価:人間のような欺瞞とコミュニケーション戦略のダイナミクスを明らかにする
GPT-4はUCSDの研究者グループによってインターネット上の一般的なチューリングテストで試験されました。最も優れたGPT-4のプロンプトは、ゲームの41%で成功しました。これはELIZA(27%)、GPT-3.5(14%)および無作為なチャンス(63%)によって提供されたベースラインよりも良い結果でしたが、まだ完全な性能ではありません。チューリングテストの結果によれば、参加者は主に言語スタイル(合計の35%)とソーシャル・エモーショナルな特性(合計の27%)で判断されました。参加者の教育レベルやLLM(Large Language Models)への事前の経験は、彼らが詐欺を見破る能力を予測するための要因ではありませんでした。これは、そのような問題に精通している人々であっても、トリックに対して脆弱である可能性があることを示しています。チューリングテストは知性の尺度としては広く批判を受けていますが、カリフォルニア大学サンディエゴ校の2人の研究者は、それが即興のコミュニケーションと詐欺の尺度として有用であると主張しています。彼らは人間と見なすことができる人工知能モデルを持っており、これには広範な社会的影響があるかもしれません。したがって、彼らは人間らしさを決定するためのさまざまな方法論と基準の効果を調査しています。 チューリングテストは知性への感度に関する論争とは関係なく興味深いものです。まず、テストされている能力、つまりシステムが対話者を人間だと思わせることができるかどうかを分析することが重要です。チューリングテストは、そのような能力の開発をモデルで監視するための信頼性のある方法を提供します。さらに、モデルのサイズや性能、プロンプト戦略、リアルタイム情報へのアクセスなどの補助的なインフラストラクチャ、およびインタラクティブのレベルなど、嘘をつくことに関与するさまざまな側面についても学ぶことができます。 また、チューリングテストは、機械が人間らしく見えるという一般的な認識を調査するための研究ツールとしても使用できます。機械のパフォーマンスが評価されますが、人間の参加者の文化的、倫理的、心理的な前提条件も調査されます。インタラクティブが質問を作成し、洗練された質問を行う過程で、インタラクターが人間であると考える属性に関する基本的な意見が明らかにされます。 チューリングテストは、1人の尋問者と1人の証人によって変更され、証人が人間か人工知能かを判断します。これはチューリングの最初の3人の公式とは異なりますが、各ゲームに複数の人間参加者をオンラインで必要としないため、かなり一般的になりました。 彼らはOpenAI APIを使用して、ユーザーからの質問に答えることができる25のLLM証人を開発しました。各LLM証人は温度設定(0.2、0.5、または1.0)、モデル(GPT-3.5またはGPT-4)、およびプロンプトを持っていました。報告書は状況を説明し、エージェントに具体的な指示を与えました。 チャットアプリのユーザーインターフェースは、標準的なメッセージングサービスに似せて作られました。尋問者が最初のメッセージを送信し、各ユーザーは同時に1つのメッセージのみを送信することができました。各通信は最大300文字で、総討論時間は5分でした。テキストボックスに貼り付けることは制限され、侮辱的なメッセージを防止するためにコンテンツフィルタが適用されました。画面の右上隅にはカウントダウンタイマー、指示オーバーレイを表示するボタン、および侮辱的な人々を報告するためのフォームがあります。 尋問者は意思決定インターフェースを使用して、以下の情報を提供しました: i)判決(機械または人間の証人) ii)正しい判断を下したことにどれだけ確信しているか(0〜100) iii)選択の理由(自由形式の言語) 制約事項 オープンでオンラインの実験としての性質上、この研究にはいくつかの欠点があり、その結果は確かとは言えません。まず、サンプルがコミュニティの代表的なものよりも反映されている可能性があります、なぜなら参加者はソーシャルメディアを通じて募集されたからです。また、参加者にはインセンティブが必要でした。したがって、尋問者や証人が最善を尽くした可能性があります。人間の証人は人工知能のように振る舞って「トローリング」しています。一部の調査員はこのような行為を人間の判決の正当化として使用しました。したがって、結果は人間のパフォーマンスを過小評価し、AIのパフォーマンスを過大評価している可能性があります。第三に、一部の尋問者は証人に関する事前知識を持っていたことを認めています。 要約すると- チューリングテストは知能の不完全な指標としてしばしば非難されてきました。これは、あまりにも評価が明らかであったために、研究者が人間のパフォーマンスを過大評価した可能性があります。最後に、一度に1人のオンラインユーザーしかいなかったため、彼らは頻繁に同じ人工知能の証人とペアリングされました。その結果、人々は特定の証言がAIであるという固定観念を持つ可能性があり、全体的に低いSR結果につながる可能性があります。このバイアスは、1人の尋問者が3回以上連続してAIと対戦したゲームを削除することで対抗する努力があったにもかかわらず、結果に影響を与えたでしょう。最後に、利用可能なプロンプトの一部のみが使用され、それらは実際の人々がゲームとどのように対話するかを知らない状態で開発されました。結果は、より効果的なプロンプトが存在するため、チューリングテストでのGPT-4の潜在的なパフォーマンスを過小評価しています。

正確なクラスタリングを簡単にする方法:kscorerの最適なK-meansクラスタを自動選択するガイド
kscorerはクラスタリングプロセスを効率化し、高度なスコアリングと並列化を通じたデータ分析への実用的なアプローチを提供します

「分析的に成熟した組織(AMO)の構築」
組織の分析の成熟度を理解することは、データ関連のプロとして強力な競争力を持つことができますそれにより、「非分析的」な意思決定(「プロジェクトの優先順位付け」など)がより情報に基づいて行われるでしょう

メディアでの顔のぼかしの力を解き放つ:包括的な探索とモデルの比較
現代のデータ駆動型の世界において、個人のプライバシーと匿名性を確保することは非常に重要です個人のアイデンティティを保護したり、GDPRなどの厳しい規制に準拠したりすることから、...
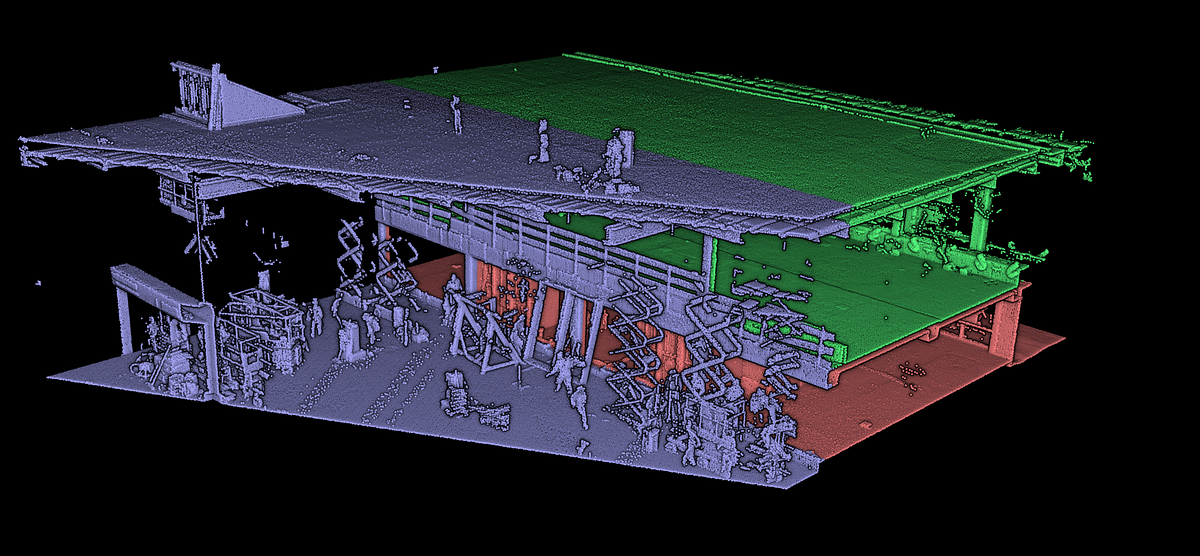
「屋内モデリングのための3Dポイントクラウド形状検出」
「屋内空間の3Dモデリングのための3D形状検出、セグメンテーション、クラスタリング、ボクセル化を自動化するための、10ステップのPythonガイド」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.