Learn more about Search Results DecisionTreeRegressor

- You may be interested
- BScの後に何をすべきか?トップ10のキャリ...
- MONAI 生成モデル:医療画像の進歩に向け...
- 「グローバルリーダーが警告、A.I.は「壊...
- 合成時系列データ生成としてのLLM
- 「Artificial Narrow Intelligence(ANI)...
- 「8月7日〜13日のトップ投稿:ChatGPTを忘...
- 光を見る
- Redshift ServerlessとKinesisを使用した...
- ツールフォーマー:AIモデルに外部ツール...
- NVIDIAの最高科学者、ビル・ダリー氏がHot...
- [GPT-4V-Actと出会いましょう:GPT-4V(isi...
- 自動小売りチェックアウトは、ラベルのな...
- 「ディープマインドのアルファコードの力...
- GPT-4の詳細がリークされました!
- 埋め込みの類似検索:データ分析の画期的...
「バッギングは決定木において過学習を防止するのに役立つのか?」
「決定木は、分類と回帰の両方の問題を解決する能力、そして提供する解釈の容易さで広く知られた機械学習アルゴリズムの一種です...」

カテゴリカル特徴:ラベルエンコーディングの問題点は何ですか?
「多くの機械学習モデルが、カテゴリーの特徴をネイティブに処理できないことはよく知られています例外もいくつかありますが、通常は実践者が数値を決定することになります...」
ランダムフォレストの解釈
近年、大型言語モデルについて大いに盛り上がりがありますが、それは従来の機械学習手法が絶滅の運命を辿るべきだということではありません私は、ChatGPTがデータセットを与えられた場合に役立つとは疑っています...
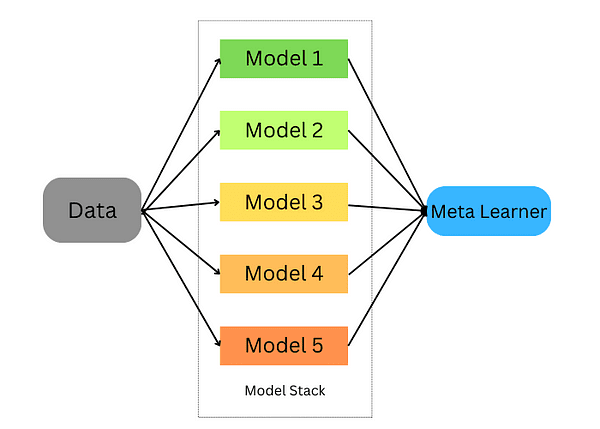
アンサンブル学習技術:Pythonでのランダムフォレストを使った手順解説
Pythonにおけるランダムフォレストの実践的な手順解説
「生データから洗練されたデータへ:データの前処理を通じた旅 – パート2:欠損値」
この記事を読む前に、特徴量エンジニアリングに関するシリーズの前の記事をチェックしてくださいほとんどの実世界のデータセットには、少なくとも一部の欠損値がありますしかし...
Scikit-Learnのパイプラインを使用して、機械学習モデルのトレーニングと予測を自動化する
Scikit-Learnのパイプラインは、機械学習のライフサイクル(主にデータの前処理、モデルの作成、テストデータでの予測)で複数の操作をつなぐために使用されますこれにより、時間と労力を節約することができます...
デノイザーの夜明け:表形式のデータ補完のためのマルチ出力MLモデル
表形式のデータにおける欠損値の扱いは、データサイエンスにおける基本的な問題ですこの記事では、デノイジングに関する文献から着想を得た洗練された手法を紹介し、表形式のデータ補完においてマルチアウトプットの機械学習モデルを活用する方法を提案します
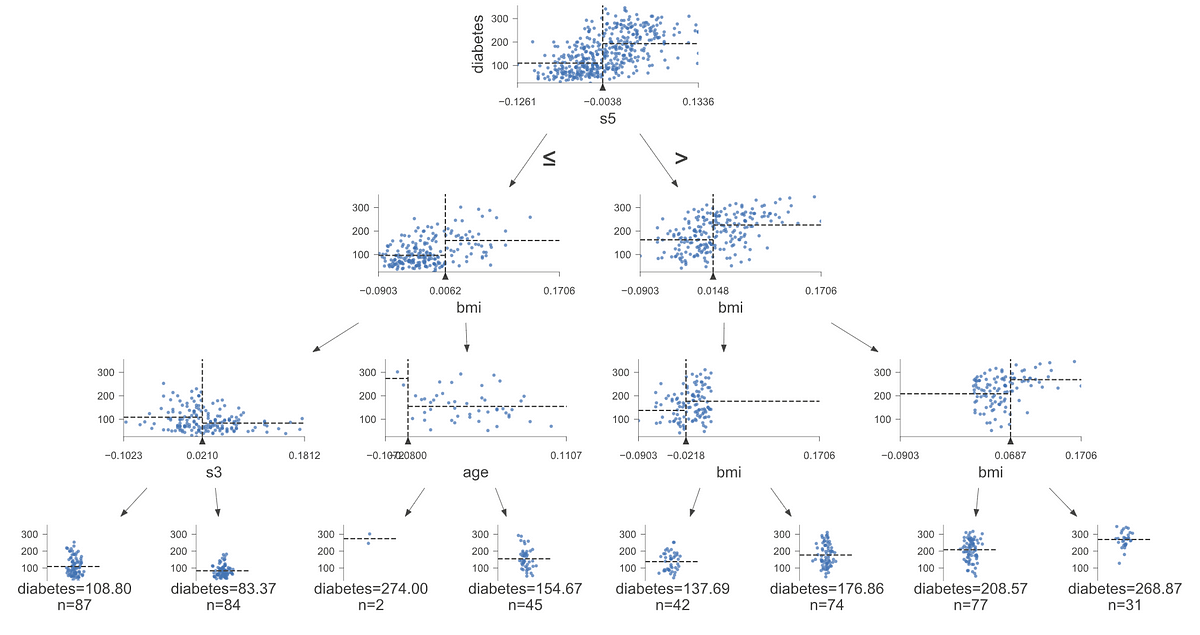
dtreevizを使用して、信じられないほどの意思決定木の視覚化を作成する
決定木モデルを視覚化できることは、モデルの説明可能性にとって重要であり、ステークホルダーがこれらのモデルに信頼を持つのに役立つことがあります
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.