Learn more about Search Results Chameleon

- You may be interested
- 「最適化によるAIトレーニングにおける二...
- 枝刈り探索法で最適解を見つける
- ハッギングフェイスのオートトレインを使...
- 「Xenovaのテキスト読み上げクライアント...
- AIは、人間の確証バイアスを克服できるか?
- サークルブームのレビュー:最高のAIパワ...
- 人工知能(AI)と法的身分
- Google Cloudによるデジタルトランスフォ...
- 機械学習によるマルチビューオプティカル...
- 「MITとNVIDIAの研究者が、要求の厳しい機...
- 機械学習において決定木とランダムフォレ...
- 「CMU研究者がニューラルネットワークの挙...
- 動的に画像のサイズを調整する
- 「LLaMaをポケットに収めるトリック:LLM...
- AI倫理の役割:革新と社会的責任のバランス
クラスタリングアルゴリズムへの導入
クラスタリングアルゴリズムの完全な入門ガイド階層型、分割型、密度ベースのクラスタリングをカバーする10種類のクラスタリングアルゴリズムを扱います

「AVIS内部:Googleの新しい視覚情報検索LLM」
「マルチモダリティは、基礎モデルの研究において最も注目されている分野の一つですGPT-4などのモデルがマルチモーダルなシナリオで驚異的な進歩を示しているにもかかわらず、まだ多くの課題がありますが、...」
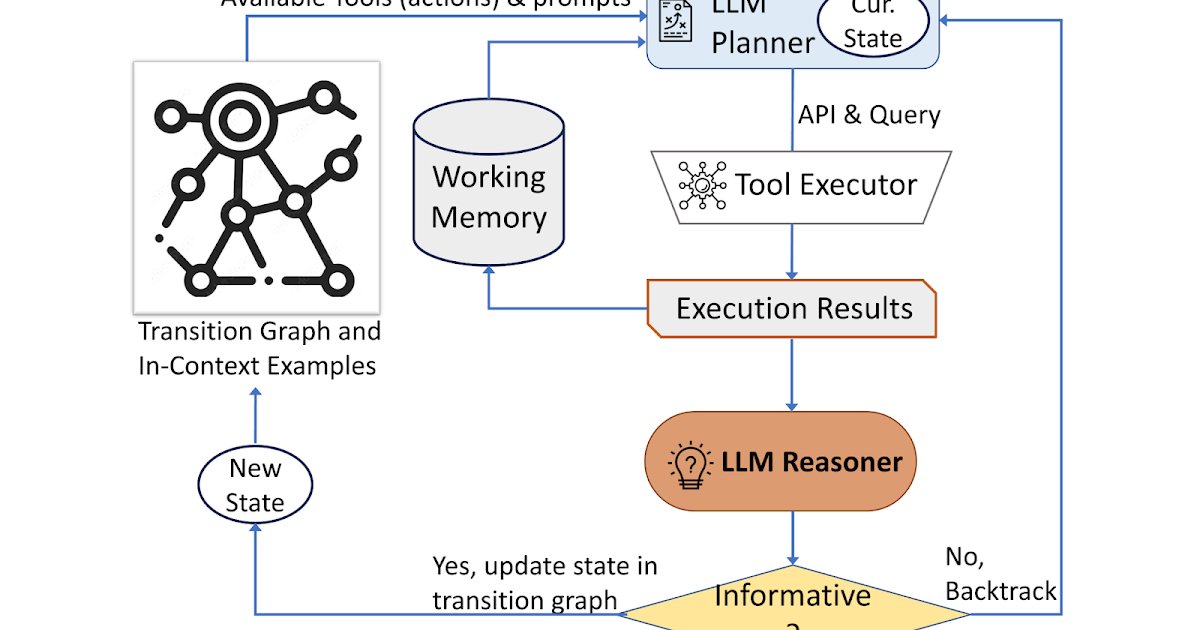
大規模な言語モデルを使用した自律型の視覚情報検索
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team 大規模言語モデル(LLM)を多様な入力に適応させるための進展があり、画像キャプショニング、ビジュアルな質問応答(VQA)、オープンボキャブラリ認識などのタスクにおいても進展が見られています。しかし、現在の最先端のビジュアル言語モデル(VLM)は、InfoseekやOK-VQAなどのビジュアル情報検索データセットにおいて、外部の知識が必要な質問に対して十分な性能を発揮できません。 外部の知識が必要なビジュアル情報検索のクエリの例。画像はOK-VQAデータセットから取得されています。 「AVIS:大規模言語モデルによる自律型ビジュアル情報検索」という論文では、ビジュアル情報検索タスクにおいて最先端の結果を達成する新しい手法を紹介しています。この手法は、LLMと3種類のツールを統合しています:(i)画像からビジュアル情報を抽出するためのコンピュータビジョンツール、(ii)オープンワールドの知識と事実を検索するためのWeb検索ツール、および(iii)視覚的に類似した画像に関連するメタデータから関連情報を得るための画像検索ツール。AVISは、LLMパワードのプランナーを使用して各ステップでツールとクエリを選択します。また、LLMパワードの推論エンジンを使用してツールの出力を分析し、重要な情報を抽出します。ワーキングメモリコンポーネントはプロセス全体で情報を保持します。 難しいビジュアル情報検索の質問に回答するためのAVISの生成されたワークフローの例。入力画像はInfoseekデータセットから取得されています。 以前の研究との比較 最近の研究(例:Chameleon、ViperGPT、MM-ReAct)では、LLMにツールを追加して多様な入力を扱うことを試みています。これらのシステムは2つのステージのプロセスに従います:プランニング(質問を構造化プログラムや命令に分解する)および実行(情報を収集するためにツールを使用する)。基本的なタスクでは成功していますが、このアプローチは複雑な実世界のシナリオではしばしば失敗します。 また、LLMを自律エージェントとして適用することに関心が高まっています(例:WebGPT、ReAct)。これらのエージェントは環境と対話し、リアルタイムのフィードバックに基づいて適応し、目標を達成します。ただし、これらの方法では各ステージで呼び出すことができるツールに制限がなく、膨大な検索空間が生じます。その結果、現在の最先端のLLMでも無限ループに陥ったり、エラーを伝播させることがあります。AVISは、ユーザースタディからの人間の意思決定に影響を受けたガイド付きLLMの使用によってこれを解決します。 ユーザースタディによるLLMの意思決定への情報提供 InfoseekやOK-VQAなどのデータセットに含まれる多くのビジュアルな質問は、人間にとっても難しい課題であり、さまざまなツールやAPIの支援が必要とされます。以下にOK-VQAデータセットの例の質問を示します。私たちは外部ツールの使用時の人間の意思決定を理解するためにユーザースタディを実施しました。…

メタスの新しいテキストから画像へのモデル – CM3leon論文の説明
メタは最近、Stable-Diffusion [2]、Midjourney、またはDALLE [3]のような拡散に基づかない最新のテキストから画像へのモデル、CM3Leon [1]を発表しました少々長いですが、要するに...

「2023年の機械学習モデルにおけるトップな合成データツール/スタートアップ」
実際の出来事の結果ではなく、意図的に作成された情報は、合成データとして知られています。合成データはアルゴリズムによって生成され、機械学習モデルのトレーニング、数学モデルの検証、テストプロダクションや運用データのテストデータセットの代替として使用されます。 合成データを使用する利点は、プライベートまたは制御されたデータを使用する際の制約の緩和、正確なデータでは満たせない特定の状況にデータ要件を調整すること、DevOpsチームがソフトウェアテストや品質保証に使用するためのデータセットを生成することなどです。 元のデータセットの複雑さを完全に複製しようとする際の制約は、不一致につながる可能性があります。実用的な合成例を生成するには、正確で正確なデータが依然として必要であるため、正確なデータを完全に代替することは不可能です。 合成データの重要性 ニューラルネットワークをトレーニングするために、開発者は広範で細心の注意を払ったデータセットが必要です。AIモデルは通常、より多様なトレーニングデータを持っているほど正確です。 問題は、数千から数百万のアイテムを含むデータセットを編集し、識別するのに多くの労力がかかり、頻繁に手頃な価格ではないことです。 ここで偽のデータが登場します。AI.Reverieの共同創設者であるPaul Walborsky氏は、ラベリングサービスから6ドルかかる単一の画像を、6セントで合成的に生成できると考えています。 お金を節約することは始まりに過ぎません。Walborsky氏は、「合成データは、プライバシーの懸念や偏見を減らすため、現実世界を正確に反映するためのデータの多様性を確保することが重要です。」と述べています。 合成データセットは、時には現実のデータよりも優れている場合があります。合成データは自動的にタグ付けされ、意図的に一般的ではないが重要な特殊な状況を含めることができます。 合成データのスタートアップおよび企業のリスト Datagen イスラエルの企業Datagenは2018年に設立され、2,200万ドルの資金調達を行っています。そのうち1,850万ドルのシリーズAが2月に行われ、その時が同社の公式な登場の機会でした。Datagenは、人間の動きに明らかな専門知識を持ち、フォトリアリスティックな視覚シミュレーションと自然界の再現に特化しており、その特異な合成データを「シミュレートデータ」と呼んでいます。Datagenは、合成データを扱う多くの他の企業と同様に、生成的敵対的ネットワーク(GAN)というAI手法を使用しています。これは、2つのシステム間のコンピューター将棋のようなものであり、一方が架空のデータを生成し、他方が結果の真実性を評価します。Datagenは、GANを物理シミュレーターと組み合わせ、強化学習ヒューマノイドモーションテクニックとスーパーレンダリングアルゴリズムを使用しています。 Datagenは、小売業、ロボット工学、拡張現実、仮想現実、モノのインターネット、自動運転車など、様々な産業をターゲットにしています。例えば、Amazon Goの場所のような小売自動化では、コンピュータービジョンシステムが買い物客を監視して、誰もが不正行為をしないことを確認しています。 Parallel Domain 自動運転車のための環境シミュレーションは、現在最も一般的なユースケースの1つです。それがSilicon ValleyのスタートアップであるParallel Domainの主要な事業領域です。Parallel Domainは2017年に設立され、その後約1,390万ドルの資金調達を行っています。その中には、昨年末の1,100万ドルのシリーズAも含まれています。トヨタはおそらく最大の支援者および顧客です。Parallel Domainは、合成データプラットフォームを使用して自動運転車に人々を殺すことを避ける方法を教えるために、最も困難なユースケースに焦点を当てています。最近の開発では、トヨタリサーチインスティチュートとのパートナーシップにより、合成データを使用して物体の恒久性について自律システムに教えています。現在の認識システムは、Parallel Domainのおかげで一時的に消える場合でもオブジェクトを追跡できるようになりましたが、まだpeek-a-booのようなものです。さらに、同社は完全に注釈付きの合成カメラとLiDARデータセットのデータビジュアライザを一般に公開しています。同社は、自律型ドローンデリバリーや自動運転のための人工的なトレーニングデータも提供しています。 Mindtech…

ToolQAとは 外部ツールを使用した質問応答のための大規模言語モデル(LLM)の能力を評価する新しいデータセット
大規模言語モデル(LLM)は、自然言語処理(NLP)と自然言語理解(NLU)の分野で非常に効果的であることが証明されています。有名なLLMの例として、GPT、BERT、PaLMなどがあり、これらは教育やソーシャルメディアから金融や医療まで、あらゆる領域で研究者によって解決策を提供するために使用されています。これらのLLMは、膨大な量のデータセットで訓練されており、膨大な知識を獲得しています。LLMは、チューニングを通じた質問応答、コンテンツ生成、テキスト要約、言語の翻訳など、さまざまな能力を持っています。最近では、LLMは印象的な能力を示していますが、根拠のない情報や数値的な推論の弱点を伴わずに、合理的な情報を生成することには困難があります。 最近の研究では、検索補完、数学ツール、コードインタプリタなどの外部ツールをLLMに組み込むことが、上記の課題に対するより良いアプローチであることが示されています。これらの外部ツールの有効性を評価することは困難であり、現在の評価方法では、モデルが事前に学習された情報を単に思い出しているのか、本当に外部ツールを利用して問題解決に役立てているのかを確定するための支援が必要です。これらの制約を克服するために、ジョージア工科大学のコンピューティング学部とアトランタの研究者チームが、外部リソースの利用能力を評価するためのベンチマークであるToolQAを開発しました。 ToolQAは、8つのドメインからのデータを含み、外部参照コーパスから情報を取得することができる13種類のツールを定義しています。ToolQAの各インスタンスには、質問、回答、参照コーパス、利用可能なツールのリストが含まれています。ToolQAの独自性は、すべての質問が適切なツールを使用して参照コーパスから情報を抽出することでのみ回答できるようになっており、これによりLLMが内部の知識に基づいてのみ質問に回答する可能性を最小限に抑え、ツールの利用能力を忠実に評価することができます。 ToolQAは、参照データ収集、人間による質問生成、プログラムによる回答生成の3つの自動化されたフェーズで構成されています。第1フェーズでは、テキスト、表、グラフなど、さまざまなタイプの公開コーパスが異なるドメインから収集され、ツールベースの質問応答のための参照コーパスとして使用されます。第2フェーズでは、ツールではなく参照コーパスに頼らない方法で解決できる質問が生成されます。これは、テンプレートベースの質問生成メソッドを通じて達成されます。このメソッドには、ツールの属性と人間によるテンプレートの作成と検証が含まれます。第3フェーズでは、生成された質問に対して正確な回答が生成され、ツールに対応する演算子が実装され、参照コーパスからプログラムによって回答が得られます。 チームは、ToolQA内の質問に対して、標準LLMとツールを組み込んだLLMの両方を使用して実験を行いました。その結果、ChatGPTやChain-of-thoughts promptingなど、内部の知識にのみ依存するLLMの成功率は、簡単な質問で約5%、難しい質問で約2%と低かったことが示されました。一方、ChameleonやReActなどのツールを組み込んだLLMは、外部ツールを使用することでより良いパフォーマンスを発揮し、簡単な質問では最高のパフォーマンスが43.15%、難しい質問では8.2%となりました。 結果とエラー分析からわかるように、ToolQAは現在のツールを組み込んだLLMアプローチにとって難しいベンチマークであり、より複雑なツールの構成的推論を必要とする難しい問題に対して特に難しいです。これはAIの発展における有望な進展です。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.