Learn more about Search Results Catboost

- You may be interested
- 「今日の市場においてAIパワードモバイル...
- ディープラーニングライブラリーの紹介:P...
- 「MITの研究者達が、シーン内の概念を理解...
- 「MLOpsは過学習していますその理由をここ...
- バイアス、有害性、および大規模言語モデ...
- T-Mobile US株式会社は、Amazon Transcrib...
- 「2023年の振り返り:Post-ChatGPT時代の...
- クロマに会ってください:LLMs用のAIネイ...
- 学習曲線の航行:AIの記憶保持との闘い
- 「GoogleのDeblur AI:画像をシャープにす...
- インターネット上のトップ8逆電話検索ツール
- 「AI規制、キャピトルヒルで初歩的な進展...
- 「Googleのマルチモーダル基本モデルへの...
- 2024年の予測17:RAG to RichesからBeatle...
- 「Spotifyで学んだSHAPによる特徴重要度分...
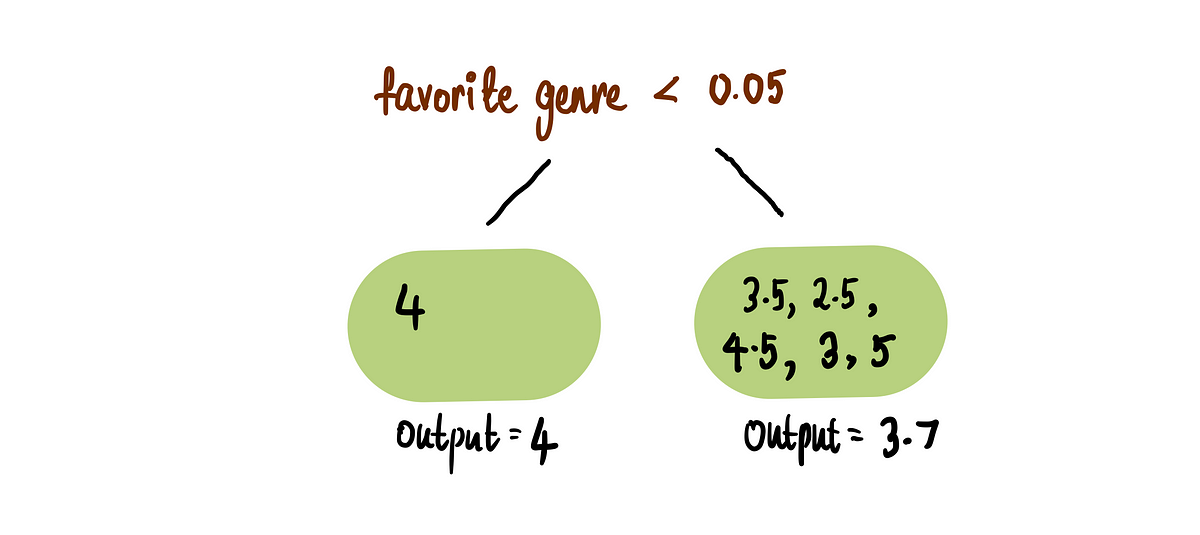
CatBoost回帰:分かりやすく解説してください
CatBoost(カテゴリカルブースティング)は、カテゴリカルな特徴量を処理し、正確な予測を生成することで優れた機械学習アルゴリズムです従来、カテゴリカルな特徴量を扱うことは…

CatBoost カテゴリカルデータを用いたモデル構築のための解決策
イントロダクション 熱心な学習者がデータサイエンスや機械学習を学びたい場合、ブーステッドファミリーを学ぶべきです。ブーステッドファミリーから派生した多くのアルゴリズムがあります。例えば、AdaBoost、Gradient Boosting、XGBoostなどです。ブーステッドファミリーのアルゴリズムの1つはCatBoostアルゴリズムです。CatBoostは機械学習アルゴリズムであり、Categorical Boostingを表しています。これはYandexによって開発されたオープンソースのライブラリです。PythonとRの両方で使用することができます。CatBoostはデータセット内のカテゴリ変数と非常にうまく動作します。他のブースティングアルゴリズムと同様に、CatBoostも分類ラベルを予測するために背後で複数の決定木、つまり木のアンサンブルを作成します。これは勾配ブースティングに基づいています。 また読む:CatBoost:カテゴリカル(CAT)データを自動的に処理するための機械学習ライブラリ 学習目標 ブーステッドアルゴリズムの概念とデータサイエンスおよび機械学習における重要性を理解する。 カテゴリ変数の処理を担当するブーステッドファミリーの一員であるCatBoostアルゴリズム、その起源、および役割を探索する。 CatBoostの主な特徴、カテゴリ変数の処理、勾配ブースティング、順序ブースティング、および正則化技術の理解。 CatBoostの利点、カテゴリ変数の堅牢な処理と優れた予測パフォーマンスについての洞察。 回帰および分類タスクにおいてPythonでCatBoostを実装し、モデルパラメータを探索し、テストデータ上で予測を行う方法を学ぶ。 この記事はData Science Blogathonの一部として公開されました。 CatBoostの重要な特徴 カテゴリ変数の処理: CatBoostはカテゴリ変数を含むデータセットの処理に優れています。さまざまな方法を使用して、カテゴリ変数を数値表現に変換することで、自動的にカテゴリ変数を処理します。これにはターゲット統計、ワンホットエンコーディング、または両方の組み合わせが含まれます。この機能により、手動のカテゴリ変数の前処理の要件を省略することで、時間と労力を節約できます。 勾配ブースティング: CatBoostは、効果的な予測モデルを作成するために、複数の弱学習器(決定木)を組み合わせるアンサンブル技術である勾配ブースティングを使用します。前の木によって引き起こされる誤りを修正するために訓練され、指示された木を追加することで、異なる可能性のある分割構成を最小化する勾配ブースティングは、イテレーションごとにツリーを作成する方法です。この反復的なアプローチにより、モデルの予測能力が徐々に向上します。 順序ブースティング: CatBoostは、「順序ブースティング」と呼ばれる新しい技術を提案して、カテゴリ変数を効果的に処理します。ツリーを構築する際に、カテゴリ変数の最適な分割点を特定するために、カテゴリ変数のパーミュテーション駆動の事前ソートという技術を使用します。この方法により、CatBoostはすべての潜在的な分割構成を考慮し、予測を改善し、過学習を低減することができます。 正則化: CatBoostでは、過学習を減らし、汎化性能を向上させるために正則化技術が使用されます。葉の値に対するL2正則化を特徴とし、過剰な葉の値を防ぐために損失関数にペナルティ項が追加されます。また、カテゴリデータのエンコーディング時の過学習を防ぐために、「順序ターゲットエンコーディング」という先端的な手法も使用します。 CatBoostの利点…

「SageMakerキャンバスモデルリーダーボードを使用して、高度な設定を持つ機械学習モデルを構築し、評価します」
「Amazon SageMaker Canvas は、アナリストや市民データサイエンティストが、自身のビジネスニーズに合わせた正確な機械学習(ML)の予測を生成するためのノーコードの作業スペースです今日から、SageMaker Canvas は、アンサンブルまたはハイパーパラメータの最適化といった高度なモデルビルドの設定、トレーニングと検証データの分割比率のカスタマイズなどをサポートしています」

カテゴリカル特徴:ラベルエンコーディングの問題点は何ですか?
「多くの機械学習モデルが、カテゴリーの特徴をネイティブに処理できないことはよく知られています例外もいくつかありますが、通常は実践者が数値を決定することになります...」

電動車向けのZenML:データから効率予測へ
はじめに 電気自動車の効率を予測し、ユーザーがそのシステムを簡単に使用できるシステムがあると思ったことはありますか?電気自動車の世界では、電気自動車の効率を非常に高い精度で予測することができます。このコンセプトは現実の世界にも導入され、私たちはZenmlとMLflowに非常に感謝しています。このプロジェクトでは、技術的な深いダイブを探求し、データサイエンス、機械学習、およびMLOpsの組み合わせがこのテクノロジーを美しく作り上げる方法を見ていきます。また、電気自動車にどのようにZenMLを使用するかも見ていきます。 学習目標 この記事では、以下のことを学びます。 Zenmlとは何か、エンドツーエンドの機械学習パイプラインでの使用方法を学ぶ。 MLFlowの役割を理解し、機械学習モデルの実験トラッカーを作成する。 機械学習モデルの展開プロセスと予測サービスの設定方法を探索する。 機械学習モデルの予測との対話に使用するユーザーフレンドリーなStreamlitアプリの作成方法を発見する。 この記事はデータサイエンスブログマラソンの一環として公開されました。 電気自動車の効率を理解する 電気自動車(EV)の効率は、バッテリーからの電気エネルギーを走行距離にどれだけ効率よく変換できるかを示します。通常、kWh(キロワット時)あたりのマイルで測定されます。 モーター効率、バッテリー効率、重量、空力、および補助負荷などの要素がEVの効率に影響を与えます。したがって、これらの領域を最適化すると、EVの効率を改善することができます。消費者にとっては、より効率の高いEVを選ぶことで、より良い運転体験が得られます。 このプロジェクトでは、実際のEVデータを使用して電気自動車の効率を予測するエンドツーエンドの機械学習パイプラインを構築します。効率を正確に予測することで、EVメーカーは設計を最適化することができます。 ZenMLというMLOpsフレームワークを使用して、機械学習モデルのトレーニング、評価、展開のワークフローを自動化します。ZenMLは、MLライフサイクルの各ステージでのメタデータの追跡、アーティファクトの管理、モデルの再現性の機能を提供します。 データ収集 このプロジェクトでは、Kaggleからデータを収集します。かわいいは、データサイエンスや機械学習プロジェクトのための多くのデータセットを提供するオンラインプラットフォームです。必要な場所からデータを収集することができます。このデータセットを収集することで、モデルへの予測を行うことができます。以下は、すべてのファイルやテンプレートが含まれている私のGitHubリポジトリです: https://github.com/Dhrubaraj-Roy/Predicting-Electric-Vehicle-Efficiency.git 問題の設定 効率的な電気自動車は未来ですが、その走行範囲を正確に予測することは非常に困難です。 解決策 私たちのプロジェクトは、データサイエンスとMLOpsを組み合わせて、電気自動車の効率予測のための正確なモデルを作成し、消費者とメーカーの両方に利益をもたらします。 仮想環境の設定 なぜ仮想環境を設定したいのでしょうか? プロジェクトを他のプロジェクトとの競合せずに目立たせるためです。…

「データセットに欠損値がありますか?何もしなさい!」
欠損値は実際のデータセットでは非常に一般的です時間とともに、この問題に対処するためにさまざまな方法が提案されてきました通常、欠損値を含むデータを削除するか、あるいは...という方法があります
データ、効率化された:より良い製品、ワークフロー、チームの構築方法
「利用可能なデータと有用なデータの間のギャップは、データプラクティショナーが実現するための唯一の目的である企業やツールの増加にもかかわらず、非常に困難であることが証明されています」
「本当にあのキノコを食べるべきか?」
ほとんどの教育的および現実世界のデータセットにはカテゴリカルな特徴が含まれています今日は、カテゴリカルな特徴にネイティブサポートを提供するCatBoostライブラリからグラディエントブースティング決定木についてカバーします...

「効果的なマーケティング戦略開発のための機械学習の活用」
マーケティングアトリビューションモデルは、マーケティング戦略を構築するために広く使用されていますこれらの戦略は、顧客の旅程全体において各タッチポイントにクレジットを割り当てることに基づいていますたくさんの...
Scikit-Learnのパイプラインを使用して、機械学習モデルのトレーニングと予測を自動化する
Scikit-Learnのパイプラインは、機械学習のライフサイクル(主にデータの前処理、モデルの作成、テストデータでの予測)で複数の操作をつなぐために使用されますこれにより、時間と労力を節約することができます...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.