Learn more about Search Results CLIP

- You may be interested
- PaLM AI | Googleの自家製生成AI
- 「Amazon SageMaker JumpStartを使用してF...
- MLモデルのパッケージング【究極のガイド】
- 「トグルスイッチ」は、量子コンピュータ...
- データアナリストからデータサイエンティ...
- 『冬-8Bに出会ってください:冴えたプラッ...
- 「Juliaプログラミング言語の探求:MongoDB」
- NLP、NN、時系列:Google Trendsのデータ...
- オープンソース大規模言語モデルの優しい紹介
- Amazon SageMakerを使用して、オーバーヘ...
- 「Serverlessを導入するのは難しいですか?」
- 「はい!OpenTelemetryはシステムのセキュ...
- 「Rasterioを使用してラスターを回転させる」
- 「LlaMA 2の始め方 | メタの新しい生成AI」
- Instruction-tuning Stable Diffusion wit...

このAI論文は、TreeOfLife-10Mデータセットを活用して生物学と保護のコンピュータビジョンを変革するBioCLIPを紹介しています
生態学、進化生物学、生物多様性など、多くの生物学の分野が、研究ツールとしてデジタルイメージおよびコンピュータビジョンを活用しています。現代の技術は、博物館、カメラトラップ、市民科学プラットフォームから大量の画像を分析する能力を大幅に向上させました。このデータは、種の定義、適応機構の理解、個体群の構造と豊富さの推定、生物多様性の監視と保全に活用することができます。 とはいえ、生物学的な問いにコンピュータビジョンを利用しようとする際には、特定のタスクに適したモデルを見つけて訓練し、十分なデータを手動でラベリングすることは、依然として大きな課題です。これには、機械学習の知識と時間が大量に必要とされます。 オハイオ州立大学、マイクロソフト、カリフォルニア大学アーヴァイン校、レンセラーポリテクニック研究所の研究者たちは、この取り組みで生命の木の基礎的なビジョンを構築することを調査しています。このモデルは、実際の生物学的なタスクに一般的に適用できるように、以下の要件を満たす必要があります。まず、一つのクラドだけでなく、様々なクラドを調査する研究者に適用できる必要があります。そして理想的には、生命の木全体に一般化できることが求められます。さらに、生物学の分野では、同じ属内の関連種や、適応度の向上のために他の種の外観を模倣するなど、視覚的に類似した生物と遭遇することが一般的です。生命の木は生物を広義のグループ(動物、菌類、植物など)および非常に細かいグループに分類しているため、このような細かな分類の精度が重要です。最後に、生物学におけるデータ収集とラベリングの高いコストを考慮して、低データの状況(例:ゼロショットまたはフューショット)で優れた結果が得られることが重要です。 数億枚の画像で訓練された現行の汎用ビジョンモデルは、進化生物学や生態学に適用する際に十分な性能を発揮しません。しかし、これらの目標はコンピュータビジョンにとって新しいものではありません。研究者たちは、生物学のビジョン基盤モデルの作成には2つの主な障害があることを特定しています。まず、既に利用可能なデータセットは、サイズ、多様性、またはラベルの精度の点で不十分ですので、より良い事前トレーニングデータセットが必要です。さらに、現在の事前トレーニングアルゴリズムは3つの主要な目標に適切に対応していないため、生物学の独特な特性を活用したよりよい事前トレーニング方法を見つける必要があります。 これらの目標とそれらを実現するための障害を念頭に置いて、チームは以下を提示しています: TREEOFLIFE-10Mという大規模なML対応の生物学画像データセット BIOCLIPはTREEOFLIFE-10M内の適切な分類群を用いてトレーニングされた生命の木を基盤としたビジョンベースのモデルです。 TREEOFLIFE-10Mは、ML対応の広範な生物学画像データセットです。生命の木において454,000の分類群をカバーする10,000,000以上の写真が含まれており、研究者たちによって編成され、最大のML対応生物学画像データセットが公開されました。2.7百万枚の写真は、最大のML対応生物学画像コレクションであるiNat21を構成しています。iNat21やBIOSCAN-1Mなどの既存の高品質データセットもTREEOFLIFE-10Mに組み込まれています。TREEOFLIFE-10Mのデータの多様性の大部分は、新たに選択された写真が含まれているEncyclopedia of Life(eol.org)から得られています。TREEOFLIFE-10Mのすべての画像の分類階層および上位の分類順位は、可能な限り注釈が付けられています。TREEOFLIFE-10Mを活用することで、BIOCLIPや将来の生物学モデルをトレーニングすることができます。 BIOCLIPは、視覚に基づく生命の木の表現です。TREEOFLIFE10Mのような大規模なラベル付きデータセットを用いてビジョンモデルをトレーニングする一般的で簡単なアプローチは、監視付き分類ターゲットを使用して画像から分類指数を予測することを学ぶことです。ResNet50やSwin Transformerもこの戦略を使用しています。しかし、このアプローチは、分類群が体系的に関連している複雑なタクソノミーのシステムを無視し、活用していません。したがって、基本的な監視付き分類を使用してトレーニングされたモデルは、未知の分類群をゼロショット分類することができない可能性があり、トレーニング時に存在しなかった分類群に対してもうまく一般化することができないかもしれません。その代わりに、チームは、BIOCLIPの包括的な生物学的タクソノミーとCLIPスタイルの多モーダルコントラスティブ学習を組み合わせる新しいアプローチに従っています。CLIPコントラスティブ学習目的を使用することで、彼らは分類群の階層をキングダムから最も遠い分類群ランクまでフラット化して、分類名として知られる文字列に関連付けることができます。BIOCLIPは、可視化できない分類群の分類名を使用する際にも、ゼロショット分類を行うことができます。 チームは、混合テキスト型のトレーニング技術が有益であることを提案し、示しています。これは、分類名からの一般化を保ちつつ、複数のテキストタイプ(例:科学名と一般名)を組み合わせたトレーニング中に柔軟性を持つことを意味します。たとえば、ダウンストリームの使用者は一般的な種名を使用し続けることができ、BIOCLIPは非常に優れたパフォーマンスを発揮します。BIOCLIPの徹底的な評価は、植物、動物、昆虫を対象とした10の細かい画像分類データセットと、トレーニング中には使用されなかった特別に編集されたRARE SPECIESデータセットに基づいて行われています。BIOCLIPは、CLIPとOpenCLIPを大きく凌ぎ、few-shot環境では平均絶対改善率17%、zero-shot環境では18%の成績を収めました。さらに、その内在的な分析はBIOCLIPのより優れた一般化能力を説明することができます。これは、生物分類学的階層を遵守した階層的表現を学んでいることを示しています。 BIOCLIPのトレーニングは、数十万の分類群に対して視覚表現を学ぶためにCLIPの目的を利用しているということにもかかわらず、チームは分類に焦点を当てたままです。今後の研究では、BIOCLIPが細かい特徴レベルの表現を抽出できるよう、inaturalist.orgから100百万枚以上の研究用写真を取り込み、種の外見のより詳細なテキスト記述を収集する予定です。

アリゾナ州立大学のこのAI研究は、テキストから画像への非拡散先行法を改善するための画期的な対照的学習戦略「ECLIPSE」を明らかにした
拡散モデルは、テキストの提案を受け取ると、高品質な写真を生成するのに非常に成功しています。このテキストから画像へのパラダイム(T2I)の生成は、深度駆動の画像生成や主題/セグメンテーション識別など、さまざまな下流アプリケーションで成功裏に使用されています。2つの人気のあるテキスト条件付き拡散モデル、CLIPモデルと潜在的な拡散モデル(LDM)のような、しばしば安定拡散と呼ばれるモデルは、これらの進展に不可欠です。LDMは、オープンソースソフトウェアとして自由に利用可能なことで研究界で知られています。一方、unCLIPモデルにはあまり注目が集まっていません。両モデルの基本的な目標は、テキストの手がかりに応じて拡散モデルをトレーニングすることです。 テキストから画像への優位性と拡散画像デコーダを持つunCLIPモデルとは異なり、LDMには単一のテキストから画像への拡散モデルがあります。両モデルファミリーは、画像のベクトル量子化潜在空間内で動作します。unCLIPモデルは、T2I-CompBenchやHRS-Benchmarkなどのいくつかの構成ベンチマークで他のSOTAモデルを上回ることが多いため、この記事ではそれに集中します。これらのT2Iモデルは通常多くのパラメータを持つため、トレーニングには優れた画像とテキストのペアリングが必要です。LDMと比較すると、DALL-E-2、Karlo、KandinskyなどのunCLIPモデルは、約10億のパラメータを持つ前のモジュールがあるため、合計モデルサイズが大幅に大きくなります(≥ 2B)。 そのため、これらのunCLIPモデルのトレーニングデータは250M、115M、177Mの画像テキストのペアリングです。したがって、2つの重要な質問が残ります:1)テキスト構成のSOTAパフォーマンスは、テキストから画像への先行モデルを使用することで改善されるのでしょうか?2)それともモデルのサイズを増やすことが重要な要素なのでしょうか?パラメータとデータの効率性を向上させることで、研究チームはT2I先行モデルについての知識を向上させ、現在の形式に比べて重要な改善を提供することを目指しています。T2I先行モデルは、拡散プロセスの各タイムステップでノイズのない画像埋め込みを直接推定するための拡散モデルでもあり、これは以前の研究が示唆しているようです。研究チームは、この前期の普及プロセスを調査しました。 図1は、SOTAテキストから画像へのモデル間の3つの構成タスク(色、形、テクスチャ)の平均パフォーマンスとパラメータの総数を比較しています。ECLIPSEは少量のトレーニングデータしか必要とせず、少ないパラメータでより優れた結果を出します。提示されたECLIPSEは、Kandinskyデコーダを使用して、わずか5百万の画像テキストペアリングのみを利用して約3300万のパラメータでT2I先行モデルをトレーニングします。 研究チームは、拡散プロセスがわずかにパフォーマンスを低下させ、正しい画像の生成には影響を与えないことを発見しました。さらに、拡散モデルは収束が遅いため、トレーニングには大量のGPU時間または日数が必要です。そのため、非拡散モデルはこの研究では代替手段として機能します。分類子のガイダンスがないため、この手法は構成の可能性を制限するかもしれませんが、パラメータの効率性を大幅に向上させ、データの依存性を軽減します。 本研究では、Arizona State Universityの研究チームは、上記の制約を克服し、T2Iの非拡散先行モデルを強化するためのユニークな対照的学習技術であるECLIPSEを紹介しています。研究チームは、提供されたテキスト埋め込みから画像埋め込みを生成する従来のアプローチを最適化することにより、Evidence Lower Bound(ELBO)を最大化しました。研究チームは、事前学習されたビジョン言語モデルの意味的整合性(テキストと画像の間)機能を使用して、以前のトレーニングを監視しました。研究チームは、ECLIPSEを使用して、画像テキストのペアリングのわずかな断片(0.34%〜8.69%)を使用して、コンパクトな(97%小さい)非拡散先行モデル(3300万のパラメータを持つ)をトレーニングしました。研究チームは、ECLIPSEトレーニングされた先行モデルをunCLIP拡散画像デコーダバリエーション(KarloとKandinsky)に導入しました。ECLIPSEトレーニングされた先行モデルは、10億のパラメータを持つバージョンを上回り、ベースラインの先行学習アルゴリズムを上回ります。研究結果は、パラメータやデータを必要とせずに構成を改善するT2I生成モデルへの可能な道を示唆しています。 図1に示すように、彼らの総合パラメータとデータの必要性は大幅に減少し、T2Iの増加により類似のパラメータモデルに対してSOTAのパフォーマンスを達成します。貢献。1)unCLIPフレームワークでは、研究チームがテキストから画像への事前の対照的な学習に初めてECLIPSEを提供しています。 2)研究チームは包括的な実験を通じて、資源制約のある文脈でのECLIPSEの基準事前に対する優位性を証明しました。 3)注目すべきは、ECLIPSE事前のパフォーマンスを大きなモデルと同等にするために、トレーニングデータのわずか2.8%とモデルパラメータのわずか3.3%しか必要としないことです。 4)また、研究チームは現在のT2I拡散事前の欠点を検討し、経験的な観察結果を提供しています。

AI研究でα-CLIPが公開されました ターゲテッドアテンションと強化された制御によるマルチモーダル画像分析の向上
さらなる焦点化と制御された画像理解および編集のために、どのようにCLIPを改善できるでしょうか?上海交通大学、復旦大学、香港中文大学、上海AI研究所、マカオ大学、およびMThreads Inc.の研究者は、点、ストローク、またはマスクで定義された指定領域を認識する能力を強化するために、コントラスティブ ランゲージ-イメージ プリトレーニング(CLIP)の制限に対処することを目指すAlpha-CLIPを提案します。この改良により、Alpha-CLIPは、画像認識や2Dおよび3D生成タスクへの貢献を含む多様な下流タスクで、より良いパフォーマンスを発揮することができます。 マスクCLIP、SAN、MaskAdaptedCLIP、およびMaskQCLIPなど、さまざまな戦略がCLIPに領域認識を持たせるために試されてきました。一部の方法は、切り抜きやマスクを用いて入力画像を変更します(ReCLIPやOvarNetなど)。他の方法は、赤い円やマスクの輪郭を使用してCLIPの注目を誘導します(Red-CircleやFGVPなど)。これらのアプローチは、CLIPのプリトレーニングデータセットのシンボルに依存することが多く、ドメインのギャップを引き起こす可能性がありますが、Alpha-CLIPは、画像コンテンツを変更せずに指定された領域に焦点を当てるための追加のアルファチャネルを導入し、一般化性能を保持しながら領域の焦点を強化します。 CLIPおよびその派生物は、下流タスクのために画像とテキストから特徴を抽出しますが、特定の領域に焦点を当てることは、より詳細な理解とコンテンツ生成において重要です。Alpha-CLIPは、コンテンツを変更せずに指定された領域に焦点を当てるためのアルファチャネルを導入し、画像認識、マルチモーダル言語モデル、および2D/3D生成などのタスクで、CLIPを強化します。Alpha-CLIPをトレーニングするには、セグメントアニシングモデルと画像キャプショニングのためのマルチモーダルな大規模モデルを使用して、領域-テキストペアのデータを生成する必要があります。 Alpha-CLIP方法は、コンテンツを変更せずに特定の領域に焦点を当てるための追加のアルファチャネルを導入したものであり、これによりコンテキスト情報が保持されます。データパイプラインは、モデルトレーニングのためにRGBA-領域テキストペアを生成します。分類データが領域-テキスト理解に与える影響を調査するために、グラウンディングデータのみで事前トレーニングされたモデルと分類およびグラウンディングデータの組み合わせを比較することによるデータ減衰の研究が行われます。ゼロショット実験では、リファリング表現の理解においてAlpha-CLIPがCLIPに代わり、競争力のある領域-テキスト理解の結果を達成します。 Alpha-CLIPは、点、ストローク、マスクを伴うタスクにおいてCLIPを改善し、焦点を当てることができる特定の領域を拡張します。ただし、グラウンディングのみのプリトレーニングを上回り、領域の知覚能力を向上させます。ImageNetなどの大規模な分類データセットは、そのパフォーマンスに大きく貢献しています。 結論として、Alpha-CLIPモデルは元のCLIPを置き換え、領域焦点の機能を効果的に向上させることが実証されています。さらにアルファチャネルを組み込むことで、Alpha-CLIPはゼロショット認識の改善やリファリング表現理解タスクでベースラインモデルを上回る競争力のある結果を示しています。関連領域に焦点を当てるモデルの能力は、分類とグラウンディングのデータの組み合わせによる事前トレーニングによって向上されています。実験結果は、Alpha-CLIPが前景領域やマスクを持つシナリオで有用であり、CLIPの能力を拡張し、画像テキスト理解を改善する可能性があることを示しています。 将来の課題として、この研究はAlpha-CLIPの制限を解決し、その能力と適用範囲を拡大するために解像度を向上させることを提案しています。研究は、領域-知覚能力を向上させるためにより強力なグラウンディングおよびセグメンテーションモデルを活用することを提案しています。研究者は、画像コンテンツをより良く理解するために、興味のある領域に焦点を当てることの重要性について強調しています。Alpha-CLIPは、画像コンテンツを変更せずに領域の焦点を当てることができます。研究は、Alpha-CLIPのパフォーマンスを改善し、応用範囲を広げ、領域に焦点を当てたCLIPの特徴の新しい戦略を探索するための継続的な研究を提唱しています。

「ゼロショットCLIPのパフォーマンスと説明可能性の向上」
「これはZero-Shot CLIPのパフォーマンスを向上させるシリーズの第2部です 第1部では、CLIPモデルの動作の詳細な説明と簡単な方法を説明しました...」

ゼロショットCLIPのパフォーマンスを向上させる簡単な方法
「ユニモーダルモデルは、テキストまたは画像のいずれかのモードからのデータを処理するように設計されていますこれらのモデルは、選択されたモードに特化したコンテンツの理解と生成に特化しています...」

「CLIP、直感的にも網羅的に解説」
この投稿では、「コントラスティブ言語-画像事前学習(CLIP)」について学びますこれは、高度に特化したものを作るために使用できるほど良いビジョンと言語表現を作成するための戦略です...

In this translation, Notes is translated to メモ (memo), CLIP remains as CLIP, Connecting is translated to 連結 (renketsu), Text is translated to テキスト (tekisuto), and Images is translated to 画像 (gazo).
上記論文の著者たちは、最小限またはほとんど監督を必要とせずに、さまざまなタスクに使用できる画像の良い表現(特徴)を生成することを目指しています画像によって生成された使い勝手の良い特徴...

「FC-CLIPによる全局セグメンテーションの革新:統一された単一段階人工知能AIフレームワーク」
イメージセグメンテーションは、画像を意味のある部分や領域に分割する基本的なコンピュータビジョンのタスクです。 それは、コンピュータが画像内の異なるオブジェクトや領域を識別して理解できるように、絵を異なるピースに分割することのようなものです。 このプロセスは、医療画像解析から自律走行車までのさまざまな応用において重要であり、それによりコンピュータが人間のように視覚的な世界を解釈し、相互作用することができます。 セグメンテーションは、基本的にセマンティックセグメンテーションとインスタンスセグメンテーションの2つのトピックに分けることができます。 セマンティックセグメンテーションは、画像内の各ピクセルにオブジェクトの種類に応じたラベルを付けることを意味し、後者はそれらが近くにある場合でも、同じタイプの個々のオブジェクトをカウントします。 そして、セグメンテーションの王様であるパノプティックセグメンテーションがあります。 それはセマンティックセグメンテーションとインスタンスセグメンテーションの両方の課題を組み合わせ、それぞれのクラスラベルに対応する非重複のマスクを予測することを目指しています。 これまでのところ、研究者たちはパノプティックセグメンテーションモデルの性能向上について重要な進展を遂げてきました。 ただし、高精細なデータセットの注釈コストのためにセマンティッククラスの数が制限されているという基本的な課題が、これらのモデルの実世界での応用を制限しています。 これはかなりの問題です。 数千の画像を確認してそれぞれのオブジェクトをマークするのは非常に時間がかかります。 何らかの方法でこのプロセスを自動化できたらどうでしょうか? これに対する統一的なアプローチを持つことができたらどうでしょうか? そんな時が来ました。FC-CLIPに会いましょう。 FC-CLIPは、前述の制限に対処する統一された単一ステージのフレームワークです。 これにより、パノプティックセグメンテーションの革新と、オープンボキャブラリーシナリオへの適用が可能になります。 封じられた語彙のセグメンテーションの課題を克服するため、コンピュータビジョンコミュニティはオープンボキャブラリーセグメンテーションの領域を探求してきました。 このパラダイムでは、自然言語で表現されたカテゴリ名のテキスト埋め込みをラベル埋め込みとして使用します。 このアプローチにより、モデルはより広範な語彙からオブジェクトを分類することができ、より広範なカテゴリに対応する能力を大幅に向上させることができます。 事前学習されたテキストエンコーダを使用することがよくあり、意味のある埋め込みが提供されることが保証されます。 これにより、モデルはオープンボキャブラリーセグメンテーションにおいて重要な単語やフレーズの意味的なニュアンスを捉えることができます。 ViTベースとCNNベースのCLIPの両方が意味のある特徴を生成します。 出典: https://arxiv.org/pdf/2308.02487.pdf…

このAI研究は、「ComCLIP:組成画像とテキストの整列におけるトレーニングフリーな方法」を公開しています
組成画像とテキストのマッチングは、ビジョン言語研究のダイナミックなフィールドにおいて、大きな課題を提起しています。このタスクには、画像とテキストの記述の中で主語、述語/動詞、および目的語の概念を正確に整列させる必要があります。この課題は、画像検索、コンテンツ理解など、さまざまなアプリケーションに重要な影響を与えます。CLIPなどの事前学習済みのビジョン言語モデルによっても大きな進展がありましたが、既存のシステムではしばしば実現が困難な組成パフォーマンスの向上がますます求められています。この課題の核心は、広範なトレーニングプロセス中にこれらのモデルに根付いてしまうバイアスと不正確な相関です。この文脈で、研究者はこの核心の問題に取り組み、ComCLIPという画期的な解決策を紹介しています。 CLIPが大きな進歩を遂げた画像テキストマッチングの現在の状況では、従来のアプローチでは画像とテキストを統一体として扱っています。このアプローチは多くの場合効果的に機能しますが、細粒度な組成理解を必要とするタスクでは改善が必要な場合があります。ここで、ComCLIPは従来の常識から大胆に逸脱します。画像とテキストを一塊のまま扱うのではなく、ComCLIPは入力画像をその構成要素である主語、目的語、およびアクションのサブイメージに分解します。これはセグメンテーションプロセスを制御する特定のエンコーディングルールに従って行われます。このような方法で画像を分解することにより、ComCLIPはこれらの異なるコンポーネントが果たす役割の深い理解を得ます。さらに、ComCLIPは動的な評価戦略を採用し、正確な組成マッチングを達成するためにこれらのさまざまなコンポーネントの重要性を評価します。この革新的なアプローチにより、事前学習済みモデルから引き継がれるバイアスと不正確な相関の影響を軽減する可能性があり、追加のトレーニングや微調整は必要ありません。 ComCLIPの方法論には、組成画像とテキストのマッチングの課題に対処するために調和するいくつかの重要な要素が含まれています。まず、元の画像は密なキャプションモジュールを使用して処理され、シーン内のオブジェクトに焦点を当てた密な画像キャプションが生成されます。同時に、入力テキスト文は解析プロセスを経ます。解析中に、エンティティの単語が抽出され、主語-述語-目的語の形式で緻密に整理され、ビジュアルコンテンツで見つかる構造を反映します。ComCLIPが行うマジックは、これらの密な画像キャプションと抽出されたエンティティの単語との間に堅牢な整列を確立することです。この整列は、エンティティの単語を密なキャプションに基づいて画像内の対応する領域に効果的にマッピングする橋となります。 ComCLIPの中での主要なイノベーションの1つは、述語のサブイメージの作成です。これらのサブイメージは、テキストの入力で説明されるアクションまたは関係を反映するように、関連するオブジェクトと主語のサブイメージを緻密に組み合わせて作成されます。結果として得られる述語のサブイメージは、モデルの理解をさらに豊かにするアクションまたは関係を視覚的に表現します。元の文と画像、およびそれぞれの解析された単語とサブイメージとともに、ComCLIPはCLIPテキストとビジョンエンコーダーを使用します。これらのエンコーダーは、テキストとビジュアルの入力を埋め込みに変換し、各コンポーネントの本質を効果的に捉えます。ComCLIPは、各画像埋め込みと対応する単語埋め込み間のコサイン類似度スコアを計算し、これらの埋め込みの関連性と重要性を評価します。これらのスコアは、softmax層によって処理され、モデルが異なるコンポーネントの重要性を正確に評価できるようになります。最後に、ComCLIPはこれらの重み付けされた埋め込みを組み合わせて最終的な画像埋め込みを取得します-入力全体の本質を包括した表現です。 まとめると、この研究は、ビジョン言語研究内での組成的な画像とテキストのマッチングの重要な課題を明らかにし、先駆的な解決策であるComCLIPを紹介しています。ComCLIPは因果推論と構造的因果モデルの原則にしっかりと基づいた革新的なアプローチであり、組成的な理解に取り組む方法を革新します。ComCLIPは、ビジュアル入力を細かく分割されたサブイメージに分解し、動的なエンティティレベルのマッチングを行うことにより、画像とテキストの組成要素を理解し、操作する能力を大幅に向上させることを約束します。CLIPやSLIPなどの既存の手法はその価値を示していますが、ComCLIPは、分野内の基本的な問題に対処し、研究と応用の新たな可能性を開拓する有望な進歩として際立っています。
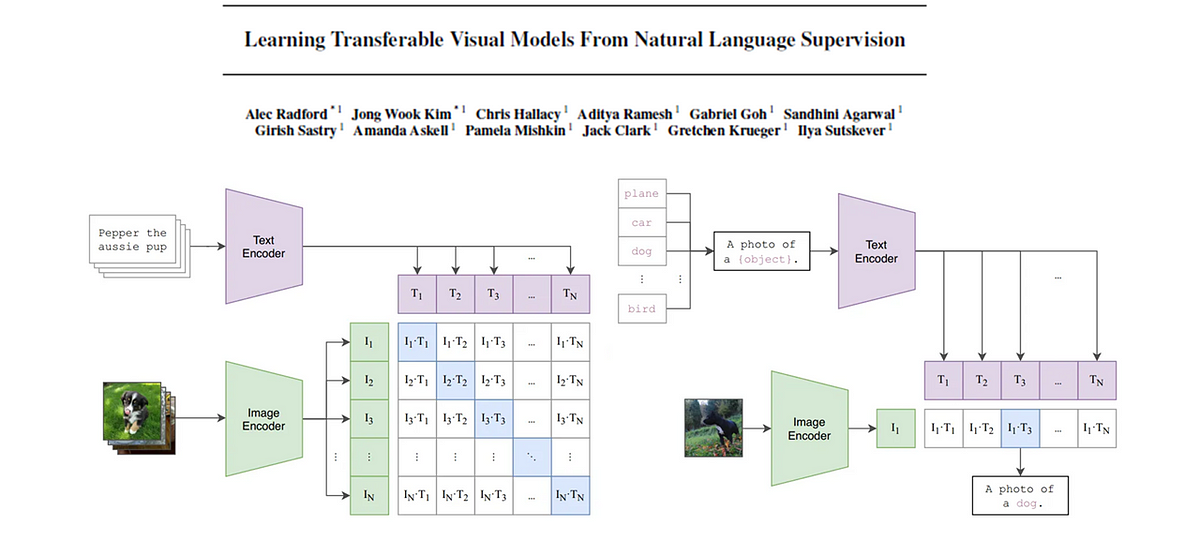
CLIP基礎モデル
この記事では、CLIP(対照的な言語画像事前学習)の背後にある論文を詳しく解説しますキーコンセプトを抽出し、わかりやすく解説しますさらに、画像...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.