Learn more about Search Results BYOL

- You may be interested
- トレンドのAI GitHub リポジトリ 2023年10...
- 「T2Iアダプタを使用した効率的で制御可能...
- 「InstagramがAIによって生成されたコンテ...
- 事前学習済みのViTモデルを使用した画像キ...
- 「NExT-GPT あらゆるモダリティに対応した...
- スタンフォード大学とUTオースティンの研...
- Pythonにおける例外とエラー処理
- 「40歳以上の方におすすめのクールなAIツ...
- コンセプトスライダー:LoRAアダプタを使...
- 「データ管理におけるメタデータの役割」
- 事前訓練された視覚表現は、長期的なマニ...
- ディープラーニングシステムは、外部から...
- アルゴリズムは、不妊症の男性の精子を医...
- データサイエンティストの役割の典型
- 『ブンブンの向こう側 産業における生成型...

BYOL(Bootstrap Your Own Latent)— コントラスティブな自己教示学習の代替手段
『今日の論文分析では、BYOL(Bootstrap Your Own Latent)の背後にある論文に詳しく触れますこれは、対比的な自己教師あり学習技術の代替手法を提供します...』

「SimCLRの最大の問題を修正する〜BYOL論文の解説」
SimCLRは対比学習のアイデアを成功裏に実装し、当時新たな最先端の性能を達成しました!それにもかかわらず、このアイデアには根本的な弱点があります!…に対する感度が高いのです
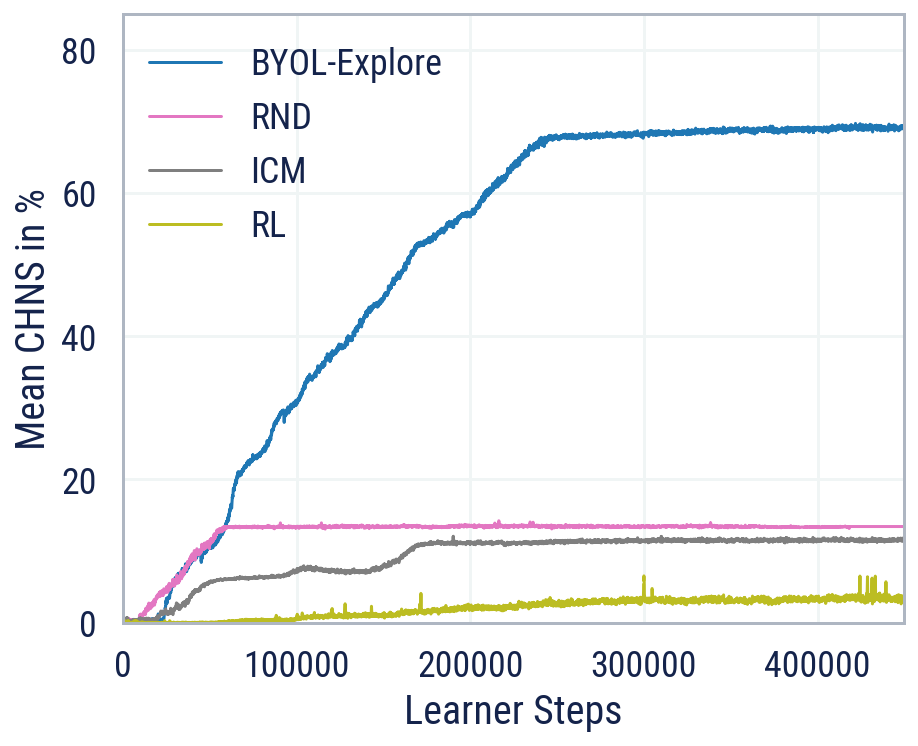
BYOL-Explore ブートストラップ予測による探索
BYOL-Exploreを紹介しますこれは、視覚的に複雑な環境での好奇心に基づいた探索のための概念的にシンプルでありながら一般的なアプローチですBYOL-Exploreは、追加の補助的な目的ではなく、潜在空間での単一の予測損失を最適化することによって、世界表現、世界の動態、および探索方針をすべて一緒に学習します我々は、BYOL-Exploreが視覚的に豊かな3D環境を持つ難解な部分観測可能な連続アクションの困難な探索ベンチマークであるDM-HARD-8で効果的であることを示します

パフォーマンスの向上と最適化されたリソース使用のためのダイナミックなLoRAローディング
私たちは、拡散モデルに基づくLoRAのハブ内の推論速度を大幅に高速化することができました。これにより、計算リソースを節約し、より良いユーザーエクスペリエンスを提供することができました。 モデルへの推論を行うには、2つのステップがあります: ウォームアップフェーズ – モデルのダウンロードとサービスのセットアップ(25秒)。 推論ジョブ自体(10秒)。 これらの改善により、ウォームアップ時間を25秒から3秒に短縮することができました。数百の異なるLoRAに対する推論を、たった5つのA10G GPU以下で提供することができます。さらに、ユーザーリクエストへの応答時間は35秒から13秒に短縮されました。 一つのサービスで多くの異なるLoRAを動的に提供するために、Diffusersライブラリで開発された最近の機能を活用する方法についてもっと話しましょう。 LoRA LoRAは「パラメータ効率」(PEFT)メソッドの一環である、微調整技術です。このメソッドは、微調整プロセスによって影響を受けるトレーニング可能なパラメータの数を減らすことを試みます。微調整の速度を高めながら、微調整済みチェックポイントのサイズを減らすことができます。 モデルの全ての重みに微小な変更を行うことによってモデルを微調整する代わりに、ほとんどの層を固定し、注意ブロック内の特定の一部の層のみをトレーニングします。さらに、これらの層のパラメータに触れず、二つの小さな行列の積を元の重みに加えることで、これらの層のパラメータを更新します。これらの小さな行列は微調整プロセス中に更新され、ディスクに保存されます。これにより、元のモデルのパラメータはすべて保存され、適応方法を使用してLoRAの重みを上にロードすることができます。 LoRA(Low Rank Adaptation)という名前は、先ほど言及した小さな行列から来ています。このメソッドについての詳細は、この記事または元の論文をご覧ください。 上記の図は、LoRAアダプタの一部として保存される二つの小さなオレンジ色の行列を示しています。後でこれらのLoRAアダプタをロードし、青いベースモデルと結合して黄色の微調整モデルを取得することができます。重要なことは、アダプタをアンロードすることも可能なので、いつでも元のベースモデルに戻すことができるということです。 言い換えると、LoRAアダプタは、必要に応じて追加および削除が可能なベースモデルのアドオンのようなものです。AとBの小さなランクのため、モデルサイズと比較して非常に軽量です。したがって、ロード時間は全体のベースモデルをロードするよりもはるかに高速です。 例えば、多くのLoRAアダプタのベースモデルとして広く使用されているStable Diffusion XL Base 1.0モデルリポジトリを見ると、そのサイズは約7 GBです。しかし、このモデルのような典型的なLoRAアダプタは、わずか24 MBのスペースしか使用しません!…

潜在一貫性LoRAsによる4つのステップでのSDXL
潜在的一貫性モデル(LCM)は、ステーブルディフュージョン(またはSDXL)を使用してイメージを生成するために必要なステップ数を減らす方法です。オリジナルモデルを別のバージョンに蒸留し、元の25〜50ステップではなく4〜8ステップ(少ない)だけを必要とするようにします。蒸留は、新しいモデルを使用してソースモデルからの出力を再現しようとするトレーニング手順の一種です。蒸留されたモデルは、小さく設計される場合があります(これがDistilBERTや最近リリースされたDistil-Whisperの場合)または、この場合のように実行に必要なステップ数を減らします。これは通常、膨大な量のデータ、忍耐力、およびいくつかのGPUが必要な長時間かかる高コストのプロセスです。 それが今日までの現状でした! 私たちは、Stable DiffusionとSDXLを、まるでLCMプロセスを使用して蒸留されたかのように、速くする新しい方法を発表できることを喜ばしく思います!3090で7秒の代わりに約1秒、Macで10倍速くSDXLモデルを実行する、というのはどうですか?詳細は以下をご覧ください! 目次 メソッドの概要 なぜこれが重要なのか SDXL LCM LoRAsによる高速推論 品質の比較 ガイダンススケールとネガティブプロンプト 品質 vs. ベースのSDXL 他のモデルとのLCM LoRAs フルディフューザーズの統合 ベンチマーク 今日リリースされたLCM LoRAsとモデル ボーナス:通常のSDXL LoRAsとの組み合わせ LCM…

「SDXLのためのシンプルな最適化の探究」
ステーブル ディフュージョン XL (SDXL)は、Stability AIによる高品質な超現実的な画像生成を目的とした最新の潜在ディフュージョンモデルです。これは、手やテキストの正確な生成、および空間的に正しい構成といった、以前のステーブル ディフュージョンモデルの課題を克服しています。さらに、SDXLはコンテキストにより適応しており、より見栄えの良い画像を生成するために、プロンプトで少ない単語数を必要とします。 しかし、これらの改善は、かなり大きなモデルのコストで実現されています。具体的には、基本のSDXLモデルには35億のパラメータ(特にUNet)があり、それは以前のステーブル ディフュージョンモデルのおよそ3倍の大きさです。 SDXLの推論速度とメモリ使用量を最適化する方法を探るために、A100 GPU(40 GB)でいくつかのテストを行いました。各推論実行において、4つの画像を生成し、それを3回繰り返し行います。推論レイテンシを計算する際には、3回のイテレーションのうち最終イテレーションのみを考慮します。 つまり、デフォルトの精度とデフォルトのアテンションメカニズムを使用してSDXLをそのまま実行すると、メモリを28GB消費し、72.2秒かかります! from diffusers import StableDiffusionXLPipelinepipeline = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0").to("cuda")pipeline.unet.set_default_attn_processor() しかし、これは非常に実用的ではなく、特に4つ以上の画像を生成する場合には遅くなる可能性があります。また、よりパワフルなGPUを持っていない場合、メモリ不足のエラーメッセージに遭遇するかもしれません。では、どのようにしてSDXLを最適化して推論速度を向上させ、メモリ使用量を減らすことができるでしょうか? 🤗 Diffusersでは、SDXLのようなメモリ集中型モデルを実行するための最適化のトリックとテクニックを数多く提供しています。以下では、推論速度とメモリに焦点を当てます。 推論速度 ディフュージョンはランダムなプロセスですので、好みの画像が得られる保証はありません。よくあるのは、複数回の推論を実行して反復する必要があることです。そのため、速度の最適化が重要です。このセクションでは、低精度の重みとメモリ効率の良いアテンションおよびPyTorch 2.0のtorch.compileの使用に焦点を当てて、速度を向上させ、推論時間を短縮する方法を紹介します。…

「DINO — コンピュータビジョンのための基盤モデル」
「コンピュータビジョンにとっては、エキサイティングな10年です自然言語の分野での大成功がビジョンの領域にも移されており、ViT(ビジョントランスフォーマー)の導入などが含まれています...」(Konpyūta bijon ni totte wa, ekisaitinguna jūnen desu. Shizen gengo no bunya de no daiseikō ga bijon no ryōiki ni mo utsusarete ori, ViT…

「CMUの研究者たちは、スロット中心のモデル(Slot-TTA)を用いたテスト時の適応を提案していますこれは、シーンを共通してセグメント化し、再構築するスロット中心のボトルネックを備えた半教師付きモデルです」
コンピュータビジョンの最も困難で重要なタスクの1つは、インスタンスセグメンテーションです。画像や3Dポイントクラウド内のオブジェクトを正確に区別し、カテゴリ分けする能力は、自律走行から医療画像解析までさまざまなアプリケーションに基盤となるものです。これらの最先端のインスタンスセグメンテーションモデルの開発においては、長年にわたって著しい進歩が達成されてきました。しかし、これらのモデルは、しばしばトレーニング分布から逸脱した多様な現実のシナリオとデータセットに対して助けが必要です。セグメンテーションモデルをこれらの分布外(OOD)シナリオに適応させるというこの課題は、革新的な研究を促しています。そのような画期的なアプローチの1つであるSlot-TTA(テスト時適応)は、非常に注目されています。 計算機ビジョンの急速な進化の中で、インスタンスセグメンテーションモデルは顕著な進歩を遂げ、画像や3Dポイントクラウド内のオブジェクトを認識し、正確にセグメント化することが可能となりました。これらのモデルは、医療画像解析から自動運転車まで、さまざまなアプリケーションの基盤となっています。しかし、それらは共通の困難な敵に直面しています。それは、トレーニングデータを超える多様な現実のシナリオとデータセットに適応することです。異なるドメイン間でシームレスに移行することのできなさは、これらのモデルを効果的に展開するための重要な障壁となっています。 カーネギーメロン大学、Google Deepmind、Google Researchの研究者たちは、この課題に対処する画期的なソリューションであるSlot-TTAを発表しました。この新しいアプローチは、インスタンスセグメンテーションのテスト時適応(TTA)に設計されています。Slot-TTAは、スロット中心の画像とポイントクラウドレンダリングコンポーネントの能力と最先端のセグメンテーション技術を結びつけています。Slot-TTAの核となるアイデアは、インスタンスセグメンテーションモデルがOODシナリオに動的に適応できるようにすることであり、これにより精度と汎用性が大幅に向上します。 Slot-TTAは、その主なセグメンテーション評価指標として調整済みランド指数(ARI)の基礎に基づいて動作します。Slot-TTAは、マルチビューの姿勢付きRGB画像、単一ビューのRGB画像、複雑な3Dポイントクラウドなど、さまざまなデータセットで厳密なトレーニングと評価を行います。Slot-TTAの特徴的な特徴は、テスト時適応のための再構成フィードバックを活用する能力です。このイノベーションは、以前に見たことのない視点とデータセットに対してセグメンテーションとレンダリングの品質を反復的に改善することを含みます。 マルチビューの姿勢付きRGB画像において、Slot-TTAは強力な競合相手として浮上します。その適応性は、MultiShapeNetHard(MSN)データセットの包括的な評価によって示されます。このデータセットには、リアルワールドのHDR背景に対して注意深くレンダリングされた51,000以上のShapeNetオブジェクトが含まれています。MSNデータセットの各シーンには、Slot-TTAのトレーニングとテストのために入力ビューとターゲットビューに戦略的に分割された9つの姿勢付きRGBレンダリング画像があります。研究者たちは、トレーニングセットとテストセットの間のオブジェクトインスタンスとシーン中のオブジェクトの数に重なりがないように特別な配慮をしています。この厳格なデータセットの構築は、Slot-TTAの堅牢性を評価するために重要です。 評価では、Slot-TTAはMask2Former、Mask2Former-BYOL、Mask2Former-Recon、Semantic-NeRFなどのいくつかのベースラインと対決します。これらのベースラインは、Slot-TTAのパフォーマンスをトレーニング分布内外で比較するためのベンチマークです。その結果は驚くべきものです。 まず最初に、OODシーンにおいて特にMask2Formerと比較して、Slot-TTA with TTAは優れた性能を発揮します。これは、Slot-TTAが多様な現実のシナリオに適応する能力の優れていることを示しています。 次に、Mask2Former-BYOLにおけるBartlerらの自己教師あり損失の追加は、改善をもたらさないことが明らかになります。これは、すべてのTTA手法が同じくらい効果的ではないことを強調しています。 さらに、セグメンテーション監督なしのSlot-TTAは、OSRT(Sajjadi et al., 2022a)のようなクロスビュー画像合成にのみトレーニングされたバリアントと比較して、Mask2Formerのような監督セグメンターに比べて大幅に性能が低下します。この観察結果は、効果的なTTAのためには訓練中のセグメンテーション監督の必要性を強調しています。 Slot-TTAの能力は、新しい、以前に見たことのないRGB画像ビューの合成と分解にも広がります。前述のデータセットとトレーニングとテストの分割を使用して、研究者はSlot-TTAのピクセル単位の再構成品質とセグメンテーションARIの精度を、5つの新しい、以前に見たことのない視点について評価します。この評価には、TTAのトレーニング中に見られなかったビューも含まれます。その結果は驚くべきものです。 Slot-TTA(Slot-centric Temporal Test-time Adaptation)による未知の視点におけるレンダリングの品質は、テスト時の適応によって大幅に向上し、新しいシナリオでのセグメンテーションとレンダリングの品質を向上させる能力を示しています。これに対し、強力な競合であるSemantic-NeRFは、これらの未知の視点への一般化に苦労しており、Slot-TTAの適応性と潜在能力を示しています。 結論として、Slot-TTAはコンピュータビジョンの分野における重要な進歩を表しており、多様な現実世界のシナリオにセグメンテーションモデルを適応させるという課題に取り組んでいます。スロット中心のレンダリング技術、高度なセグメンテーション手法、およびテスト時の適応を組み合わせることで、Slot-TTAはセグメンテーションの精度と汎用性の両方で顕著な改善を提供します。この研究は、モデルの制約を明らかにするだけでなく、コンピュータビジョンの将来のイノベーションへの道を開拓します。Slot-TTAは、コンピュータビジョンの絶えず進化する領域で、インスタンスセグメンテーションモデルの適応性を向上させることを約束します。

「なんでもセグメント:任意のオブジェクトのセグメンテーションを促す」
今日の論文解説はビジュアルになります!私たちはMetaのAI研究チームによる論文「Segment Anything」を分析しますこの論文は研究コミュニティだけでなく、あらゆる分野でも話題となりました...

「T2Iアダプタを使用した効率的で制御可能なSDXL生成」
T2I-Adapterは、オリジナルの大規模なテキストから画像へのモデルを凍結しながら、事前学習されたテキストから画像へのモデルに追加のガイダンスを提供する効率的なプラグアンドプレイモデルです。T2I-Adapterは、T2Iモデル内部の知識を外部の制御信号と整合させます。さまざまな条件に応じてさまざまなアダプタをトレーニングし、豊富な制御と編集効果を実現することができます。 ControlNetは同様の機能を持ち、広く使用されている現代の作業です。しかし、実行するには計算コストが高い場合があります。これは、逆拡散プロセスの各ノイズ除去ステップで、ControlNetとUNetの両方を実行する必要があるためです。さらに、ControlNetは制御モデルとしてUNetエンコーダのコピーを重要視しており、パラメータ数が大きくなるため、生成はControlNetのサイズによって制約されます(サイズが大きければそれだけプロセスが遅くなります)。 T2I-Adapterは、この点でControlNetに比べて競争力のある利点を提供します。T2I-Adapterはサイズが小さく、ControlNetとは異なり、T2I-Adapterはノイズ除去プロセス全体の間ずっと一度だけ実行されます。 過去数週間、DiffusersチームとT2I-Adapterの著者は、diffusersでStable Diffusion XL(SDXL)のT2I-Adapterのサポートを提供するために協力してきました。このブログ記事では、SDXLにおけるT2I-Adapterのトレーニング結果、魅力的な結果、そしてもちろん、さまざまな条件(スケッチ、キャニー、ラインアート、深度、およびオープンポーズ)でのT2I-Adapterのチェックポイントを共有します。 以前のバージョンのT2I-Adapter(SD-1.4/1.5)と比較して、T2I-Adapter-SDXLはまだオリジナルのレシピを使用しており、79Mのアダプタで2.6BのSDXLを駆動しています!T2I-Adapter-SDXLは、強力な制御機能を維持しながら、SDXLの高品質な生成を受け継いでいます。 diffusersを使用してT2I-Adapter-SDXLをトレーニングする 私たちは、diffusersが提供する公式のサンプルを元に、トレーニングスクリプトを作成しました。 このブログ記事で言及するT2I-Adapterモデルのほとんどは、LAION-Aesthetics V2からの3Mの高解像度の画像テキストペアで、以下の設定でトレーニングされました: トレーニングステップ:20000-35000 バッチサイズ:データ並列、単一GPUバッチサイズ16、合計バッチサイズ128。 学習率:定数学習率1e-5。 混合精度:fp16 コミュニティには、スピード、メモリ、品質の間で競争力のあるトレードオフを打つために、私たちのスクリプトを使用してカスタムでパワフルなT2I-Adapterをトレーニングすることをお勧めします。 diffusersでT2I-Adapter-SDXLを使用する ここでは、ラインアートの状態を例にとって、T2I-Adapter-SDXLの使用方法を示します。まず、必要な依存関係をインストールします: pip install -U git+https://github.com/huggingface/diffusers.git pip install…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.