Learn more about Search Results 構成

- You may be interested
- ChatGPTはデータサイエンティストを置き換...
- 「読んだものに関してのみ話すこと:LLM(...
- 「2023年の最高のAI文法チェッカーツール」
- 「画像の補完の進展:この新しいAI補完に...
- 「トランスフォーマーアーキテクチャとBER...
- 「イノベーションと持続可能性のバランス...
- 「ゼロ-ETL、ChatGPT、およびデータエンジ...
- Pythonアプリケーション | 速度と効率の向...
- 「人工知能(AI)のトップコンテンツ検出...
- 「知っておくべき3つの一般的な時系列モデ...
- 研究者たちは、AIにより優れたグラフのキ...
- RAGアプリケーションデザインにおける実用...
- 「PhysObjectsに会いましょう:一般的な家...
- 「機械学習チートシートのためのScikit-le...
- ChatGPTのクエリごとのエネルギー使用量

ラストマイルAIは、AiConfigをリリースしました:オープンソースの構成駆動型、ソースコントロールに対応したAIアプリケーション開発フレームワーク
AIアプリケーション開発の進化する風景の中で、AI Configは、LastMile Ai から登場し、開発者がAIモデルを統合し、管理する方法を根本的に変える画期的なツールとして注目されています。この革新的なアプローチは、従来の予測型機械学習開発からの脱却であり、ソフトウェアエンジニアの間でより協力的な環境を促進します。 AI Configによる開発の革新 AI Configは、アプリケーションコードをモデルのロジックから切り離す画期的な手法を導入しています。この分離により、開発者はアプリケーションコードを絶えず修正することなく、モデルのオーケストレーションの向上に集中することができます。これにより、より効率的で効率的な開発プロセスが実現されます。 AI Configの主な利点 協力的な開発:異なる個人が独立してプロンプト、モデル、およびアプリケーションコードを管理できるようにすることで、関係を切り離すことを促進します。この分割により、より協力的かつ専門的な開発環境が構築されます。 高度なプロトタイピング:AI Configは、LastMile AIワークブックの一部としてプロンプトとモデルを1つのノートブックのようなエディタに統合し、プロトタイピングと反復プロセスを大幅に加速します。 ガバナンスとコントロール:生成モデルの動作を追跡および再現するために重要なソース制御アーティファクトとして機能します。これには、プロンプトチェーンの管理、さまざまなプロバイダーからのモデルの選択、およびモデルパラメータの調整が含まれます。 迅速な反復と展開:開発者は、アプリケーションコードを変更せずにプロンプトの調整やモデルの切り替えなど、複数のモデルオーケストレーションに迅速に反復することができます。これにより、より迅速な展開とより安定したアプリケーションが実現されます。 ユーザーフレンドリーなインターフェース:LastMiles Aiの直感的なユーザーインターフェースにより、複雑なAI統合がさまざまなスキルレベルの開発者にもアクセス可能になり、論理的なシーケンスの作成を簡素化します。 オープンソースと拡張性:オープンソースであるAI Configは、API統合を介してクローズドソースのモデルと、ローカルでの実行のためのオープンソースのモデルの両方をサポートします。 効率的なモデル管理:AI Configでは、複数のAIモデルをシームレスに組み合わせ、プロンプトの内外のパラメータを処理することができます。以前の実行のキャッシュされた出力を直列化することで、迅速な反復と評価をサポートします。 AI開発の新時代 AI…

「グーグルディープマインドが発表したこのAI論文は、事前学習データの構成と予め訓練された変形器のコンテキスト学習との間のギャップを研究しています」
Google DeepMindの研究者は、大規模な言語モデルであるtransformerのin-context learning (ICL)の能力を探求しました。ただし、彼らの研究はドメイン外のタスクに取り組む必要があり、事前学習の分布を超えた機能の一般化に制約が存在することを明らかにしました。その結果、高容量のシーケンスモデルの印象的なICLの能力は、基本的な一般化に対する組み込みの帰納バイアスよりも事前学習データのカバレッジにより依存していることが示唆されています。 この研究は、transformerモデルがICLを使用してfew-shot learningを行う能力を調査しています。事前学習データがモデルのパフォーマンスに及ぼす影響を強調しています。本研究では、transformerが事前学習データに適切にタスクファミリーをカバーしている場合、非監視モデル選択で優れたパフォーマンスを発揮することが示されています。ただし、ドメイン外のタスクに取り組む際には制約や一般化の低下が見られます。結果として、関数クラスの混合で訓練されたモデルは、単一のクラスで訓練されたモデルとほぼ同等のパフォーマンスを示すことが明らかになりました。本研究には、各種の事前学習データ構成におけるモデルのパフォーマンスを示すICL学習曲線も含まれています。 この研究は、transformerモデルのICLの能力について掘り下げ、事前学習分布内外のタスクの学習能力に優れていることを強調しています。Transformerは高次元かつ非線形な関数の扱いにおいて優れたfew-shot learningを示します。本研究では、事前学習データがこれらの能力に与える影響を制御された設定で理解することを目的としています。それにより、データソースの構築の影響を把握し、事前学習およびドメイン外の一般化を調査します。パフォーマンス評価には、訓練時には見られなかったタスクや訓練済み関数の極端なバリエーションなども含まれます。 制御された研究では、自然言語ではなく(x, f(x))のペアで訓練されたtransformerモデルを使用し、事前学習データがfew-shot learningに与える影響を詳しく調べています。異なる事前学習データの構成を持つモデルを比較することで、研究はさまざまな評価関数に対するモデルのパフォーマンスを評価しています。関数クラスファミリー間のモデル選択とドメイン外の一般化を探求することで、ICL曲線を取り入れ、さまざまな事前学習データ構成での平均二乗誤差を示しています。事前学習分布内外のタスクについての評価では、失敗モードや一般化の低下の経験的証拠が明らかになります。 Transformerモデルは、事前学習データのバリエーションのあるタスクファミリーからほぼ最適な非監視モデル選択を示します。ただし、事前学習データの範囲外のタスクに直面すると、さまざまな失敗モードや一般化の低下が現れます。異なる事前学習データ構成に基づいてモデルを比較すると、関数クラスにのみ事前学習されたモデルとほぼ同等のパフォーマンスを発揮することが明らかになります。この研究では、スパースモデルと密なモデルの間の違いによって正規化された平均二乗誤差の平方差メトリックを導入し、基本的な一般化能力における事前学習データのカバレッジの重要性を強調しています。 結論として、事前学習データの構成は、特に自然言語の設定において、transformerモデルの正確なモデル選択において重要な役割を果たします。これらのモデルは明示的なトレーニングなしで新しいタスクを学習できますが、事前学習データを超える充電の扱いには助けが必要となる場合があり、異なる失敗モードや一般化の低下が生じます。したがって、ICLの理解と実現により、これらのモデルの総合的な効果を向上させることが重要です。

このAI論文では、「ビデオ言語計画(VLP)」という新しい人工知能アプローチを提案していますこのアプローチは、ビジョン言語モデルとテキストからビデオへのダイナミクスを組み合わせたツリーサーチ手法で構成されています
人工知能の進化により、生成モデルは急速に成長しています。物理環境と知的に相互作用するアイデアは、低レベルの基礎的なダイナミクスと高レベルの意味的な抽象化の2つの異なるレベルでの計画の重要性を強調しています。これらの2つのレイヤーは、実際の世界での活動を適切に制御するためには、ロボットシステムにとって不可欠です。 計画問題をこれらの2つのレイヤーに分割する概念は、ロボット工学では以前から認識されています。その結果、動作とタスクの計画を組み合わせ、複雑な操作作業の制御ルールを特定することを含む多くの戦略が開発されてきました。これらの方法は、作業の目標と現実の環境のダイナミクスを考慮に入れた計画を生成することを目的としています。LLMについて話すと、これらのモデルは記号的なジョブの説明を使用して高レベルの計画を作成することができますが、そのような計画を実装することには問題があります。形状、物理、制約など、タスクの具体的な部分に関しては、推論することができません。 最近の研究では、Google Deepmind、MIT、およびUC Berkeleyの研究者チームが、テキストからビデオやビジョン言語モデル(VLM)を統合することでこれらの欠点を克服する提案を行っています。両モデルの利点を組み合わせたこの統合は、Video Language Planning(VLP)として紹介されています。VLPは、長期的で複雑な活動のための視覚的な計画を容易にすることを目的として導入されました。VLPは、インターネットデータ上で広範な事前トレーニングを受けた大規模な生成モデルの最近の進展を活用しています。VLPの主な目標は、言語と視覚のドメインの両方で理解と長いアクションシーケンスを必要とするジョブを計画することを容易にすることです。これらのジョブには、単純なオブジェクトの配置から複雑なロボットシステムの操作まで、さまざまなものが含まれます。 VLPの基礎は、2つの主要部分からなるツリーサーチプロセスです。 ビジョン言語モデル:これらのモデルは値関数とポリシーの両方の役割を果たし、計画の作成と評価をサポートします。タスクの説明と利用可能な視覚情報を理解した後、作業を完了するための次のアクションを提案することができます。 テキストからビデオへのモデル:これらのモデルはダイナミクスモデルとしての役割を果たし、特定の意思決定がどのような影響を与えるかを予測する能力を持っています。これらの予測は、ビジョン言語モデルが示唆する行動から導かれる可能性のある結果を予測します。 VLPでは、長期的なタスクの指示と現在の視覚的観察が主な入力として使用されます。VLPの結果は、言語と視覚の特徴を組み合わせて最終目標を達成するための段階的な指示を提供する完全かつ詳細なビデオ計画です。これにより、書かれた作業の説明と視覚的理解とのギャップを埋めるのに役立ちます。 VLPは、バイアームの器用な操作や複数オブジェクトの再配置など、さまざまな活動を行うことができます。この柔軟性は、アプローチの幅広い可能性を示しています。実際のロボットシステムは、生成されたビデオの設計図を実際に実装することができます。目標指向のルールは、仮想計画を実際のロボットの動作に変換するのに役立ちます。これらの規則により、ロボットは中間フレームごとのビデオ計画を行動のガイドとして使用しながら、ステップバイステップでタスクを実行することができます。 VLPを使用した実験を以前の手法と比較すると、長期的なタスクの成功率の重要な向上が見られました。これらの調査は、3つの異なるハードウェアプラットフォームを使用した実際のロボットおよびシミュレーション環境で実施されました。

「CityDreamerと出会う:無限の3D都市のための構成的生成モデル」
近年、3D自然環境の作成は多くの研究の対象となっています。3D都市、3Dシナリオ、3Dアバターなど、さまざまな種類の3Dオブジェクトの作成において、大きな進歩がありました。都市は、都市計画、環境シミュレーション、ゲーム作成などの分野で、3Dコンポーネントとして重要な役割を果たしています。 GANCraftやSceneDreamerなどのモデルは、3Dシーン内の画像を体積ニューラルレンダリングアルゴリズム、3D座標、および意味ラベルを使用して生成しています。これらの技術は、SPADEの偽の正解写真を使用して、3D自然環境の作成において有望な結果を示しています。しかし、3D自然環境の作成はいくつかの制約があります。都市の作成は、自然の風景の作成よりも基本的に複雑です。なぜなら、建物は同じクラスのオブジェクトに属しているにもかかわらず、木などの自然の風景要素と比べてはるかに多様な外観を持っているからです。 これらの課題を克服するために、CityDreamerというユニークなアプローチが導入されました。これにより、よりアクセス可能でリアルな3D都市の開発が可能になりました。CityDreamerは、無制限の3D都市のために特別に作成された合成的な生成モデルです。通常、都市には道路、公園、水の特徴など、他の背景要素も存在しますが、CityDreamerは建物のインスタンスの作成を他の要素から分離するというユニークな戦略を採用しています。この分割は、モデル内の複数のモジュールを介して達成されました。 また、OSMとGoogleEarthという2つの大規模データセットが作成され、生成された3D都市のレイアウトと美的外観の信憑性を向上させるために使用されました。これらのデータベースには実際の都市の画像が大量に含まれています。実際の世界からの特徴と違いを追加することで、構築される3D都市のリアリズムを高めることを試みています。CityDreamerは、試行とレビューを通じて、3D都市開発の分野での先端技術に優れていることを証明しています。都市の複雑さや正確で高品質な結果の要求といった困難を克服し、さまざまなリアルな3D都市を作成する能力を示しました。 CityDreamerプロジェクトの主な貢献は次のとおりです。 CityDreamerモデル:この研究の中心的な貢献は、CityDreamerモデルの導入です。このモデルは、無制限の3D都市の生成に特化しています。建物のインスタンスの生成を道路、緑地、水などの他の背景オブジェクトから分離するというユニークなアプローチを採用しており、モデル内の異なるモジュールを使用してより正確な制御と向上したリアリズムを実現しています。 データセットの構築:最初のデータセットであるOSMは、OpenStreetMapからデータを取得することでより現実的な都市のレイアウトを提供しています。道路、建物、緑地、水の位置に関する貴重な情報をセマンティックマップと高さフィールドで提供します。2番目のデータセットであるGoogleEarthは、Google Earth Studioでキャプチャされた画像を含んでおり、マルチビューの一貫性を備えており、より包括的で現実的な都市環境の表現が可能です。 定量的および定性的評価:CityDreamerのパフォーマンスは、定量的および定性的な評価を通じて評価されています。大規模で多様な3D都市の生成能力を示すために、既存の最先端の3D生成モデルと比較されています。

IBMの研究者が、深層学習推論のためのアナログAIチップを紹介:スケーラブルなミックスドシグナルアーキテクチャの重要な構成要素を披露
AI革命が進行中であり、ライフスタイルや職場を再構築することが期待されています。深層ニューラルネットワーク(DNN)は、基盤モデルと生成AIの出現により重要な役割を果たしています。しかし、これらのモデルをホストする従来のデジタルコンピューティングフレームワークは、パフォーマンスとエネルギー効率の潜在的な制約となっています。AI固有のハードウェアが登場していますが、多くの設計ではメモリと処理ユニットを分離しているため、データのシャッフルと効率の低下が生じます。 IBM Researchは、AI計算を再構想するための革新的な方法を追求しており、アナログインメモリコンピューティングまたはアナログAIという概念を提案しています。このアプローチは、神経回路網がニューロンの通信を制御するシナプスの強度から着想を得ています。アナログAIは、相変化メモリ(PCM)などのナノスケールの抵抗デバイスを使用して、導電性の値としてシナプスの重みを格納します。PCMデバイスは非終励性を持ち、範囲の値をエンコードし、重みをローカルに保存することができます。 IBM Researchは、最近のNature Electronics誌で、アナログAIの実現に向けて重要な進展を達成しました。彼らは、さまざまなDNN推論タスクに適した最先端のミックスドシグナルアナログAIチップを紹介しました。このチップは、IBMのアルバニーナノテックコンプレックスで製造され、各々が256×256のクロスバーアレイのシナプスユニットセルを持つ64個のアナログインメモリコンピュートコアを特徴としています。統合されたコンパクトな時間ベースのアナログ・デジタル変換器により、アナログとデジタルのドメイン間のシームレスな切り替えが可能となっています。さらに、各コア内のデジタル処理ユニットは基本的なニューロン活性化関数とスケーリング演算を処理します。 このチップのアーキテクチャにより、各コアはDNNレイヤーに関連する計算を処理する能力を持っています。シナプスの重みはPCMデバイスにアナログ導電値としてエンコードされます。グローバルなデジタル処理ユニットは、特定のニューラルネットワークの実行に重要な複雑な操作を管理します。チップのデジタル通信パスは、すべてのタイルと中央のデジタル処理ユニットを接続しています。 性能に関しては、このチップはCIFAR-10画像データセットで92.81%という印象的な正答率を示し、アナログインメモリコンピューティングにおいて非常に優れた成果を収めています。この研究では、アナログインメモリコンピューティングをデジタル処理ユニットとデジタル通信ファブリックとシームレスに統合することで、より効率的なコンピューティングエンジンを実現しました。チップの面積あたりのGiga-operations per second(GOPS)におけるスループットは、従来の抵抗メモリベースのインメモリコンピューティングチップの15倍以上を超えるエネルギー効率を維持しながら実現されました。 アナログ・デジタル変換器、積和演算能力、およびデジタル計算ブロックの突破的な進歩を活用し、IBM Researchは高速で低消費電力のアナログAI推論アクセラレータチップに必要な多くの要素を実現しました。以前提案されたアクセラレータのアーキテクチャは、多数のアナログインメモリコンピューティングタイルを専用のデジタルコンピュートコアに接続し、並列な2Dメッシュを介して接続されています。このビジョンとハードウェアに対するトレーニング技術は、将来のさまざまなモデルでソフトウェアと同等のニューラルネットワークの精度を提供すると期待されています。

UC BerkeleyとDeepmindの研究者は、SuccessVQAという成功検出の再構成を提案しましたこれは、Flamingoなどの事前学習済みVLMに適したものです
最高のパフォーマンス精度を達成するためには、トレーニング中にエージェントが正しいまたは望ましいトラック上にあるかどうかを理解することが重要です。これは、強化学習においてエージェントに報酬を与えることや、評価指標を使用して最適なポリシーを特定することで実現できます。そのため、このような成功した振る舞いを検出できる能力は、高度なインテリジェントエージェントを訓練する際に基本的な前提条件となります。これが成功検出器が登場する場所であり、エージェントの振る舞いが成功したかどうかを分類するために使用できます。先行研究によれば、ドメイン固有の成功検出器を開発する方が、より一般的なものよりも比較的容易であることが示されています。これは、ほとんどの現実世界のタスクにおいて何が成功と見なされるかを定義することが非常に難しいためであり、しばしば主観的なものです。たとえば、AIによって生成された美術作品は、一部の人を魅了するかもしれませんが、全体の観客に同じことが言えるわけではありません。 過去数年間、研究者たちはさまざまなアプローチを提案してきましたが、成功検出器を開発するためのものの1つは、好みのデータを使用した報酬モデリングです。しかし、これらのモデルには特定のタスクと環境条件にしか適用できないという欠点があります。したがって、一般化を確保するためには、幅広いドメインをカバーするためにより多くの注釈が必要であり、非常に労力を要する作業です。一方、ビジョンと言語の両方を入力とするモデルを訓練する場合、一般化可能な成功検出は、言語のバリエーションと視覚的なバリエーションの両方で正確な測定を提供する必要があります。既存のモデルは通常、固定条件とタスクに対して訓練されているため、このようなバリエーションに一般化することはできません。また、新しい条件に適応するには、新しい注釈付きデータセットを収集してモデルを再訓練する必要があり、常に実現可能ではありません。 この問題に取り組んでいるDeepMindの子会社であるAlphabetの研究者チームは、言語の仕様と知覚条件の両方の変動に耐えうる堅牢な成功検出器を訓練する手法を開発しました。彼らは、Flamingoなどの大規模な事前学習済みのビジョン言語モデルと人間の報酬注釈を活用することで、これを達成しました。この研究は、Flamingoを多様な言語と視覚データに対して大量に事前学習することが、より堅牢な成功検出器のトレーニングにつながるという研究者の観察に基づいています。研究者らは、彼らの最も重要な貢献は、一般化可能な成功検出のタスクを視覚的な質問応答(VQA)の問題として再定義したことであり、これをSuccessVQAと呼んでいます。このアプローチでは、対象のタスクを単純な「はい/いいえ」の質問として指定し、状態環境を定義する短いクリップと、望ましい振る舞いを説明するテキストだけで構成される統一されたアーキテクチャを使用します。 DeepMindチームはまた、Flamingoを人間の注釈で微調整することで、家庭内シミュレーション、現実世界のロボット操作、野外の視点主体の人間のビデオなど、3つの主要なドメインで一般化可能な成功検出を実証しました。SuccessVQAタスクの普遍的な性質により、研究者は同じアーキテクチャとトレーニングメカニズムを異なるドメインの幅広いタスクに使用することができます。さらに、Flamingoのような事前学習済みのビジョン言語モデルを使用することで、大規模なマルチモーダルデータセットでの事前学習の利点を十分に活用することができました。チームは、これにより言語と視覚のバリエーションの両方において一般化が可能になったと考えています。 成功検出の再定義を評価するために、研究者たちは見知らぬ言語と視覚のバリエーションにわたるいくつかの実験を行いました。これらの実験の結果、事前学習済みのビジョン言語モデルは、ほとんどの分布内タスクで同等の性能を発揮し、分布外のシナリオではタスク固有の報酬モデルよりも優れたパフォーマンスを示すことが明らかになりました。調査結果では、これらの成功検出器は、既存の報酬モデルが失敗する言語とビジョンのバリエーションへのゼロショットの一般化が可能であることが示されました。DeepMindの研究者が提案した新しいアプローチは、非常に優れたパフォーマンスを持っていますが、ロボティクス環境に関連するタスクなど、いくつかの欠点もあります。研究者らは、今後の研究ではこの領域でさらなる改善を行う予定であると述べています。DeepMindは、研究コミュニティが彼らの初期の研究を成功検出と報酬モデリングに関してさらなる成果を達成するための礎として評価してくれることを期待しています。

スタンフォード大学の研究者が「局所的に条件付けられた拡散(Locally Conditioned Diffusion):拡散モデルを使用した構成的なテキストから画像への生成手法」を紹介しました
3Dシーンモデリングは従来、特定の知識を持つ人々に限られた時間のかかる手続きでした。パブリックドメインには多くの3D素材がありますが、ユーザーの要件に合う3Dシーンを見つけることは珍しいです。そのため、3Dデザイナーは個々の3Dオブジェクトをモデリングし、シーンに組み立てるために数時間または数日を費やすことがあります。3Dの作成を簡単にし、同時にその構成要素を制御できるようにすることは、経験豊富な3Dデザイナーと一般の人々(例:個々のオブジェクトのサイズと位置)とのギャップを埋めるのに役立ちます。 最近、3Dシーンモデリングのアクセシビリティが改善されました。3D生成モデルに取り組むことで、3Dオブジェクトの合成において有望な結果が得られています。3Daware生成対抗ネットワーク(GAN)を使用して3Dオブジェクトの合成に関する有望な結果が得られており、作成されたアイテムをシーンに組み合わせるための第一歩となっています。しかし、GANは特定のアイテムカテゴリに特化しており、結果のバラエティが制限され、シーンレベルのテキストから3Dへの変換が困難です。これに対し、拡散モデルを使用したテキストから3Dへの生成は、さまざまなカテゴリの3Dオブジェクトの作成を促すことができます。 現在の研究では、異なる可能なシーン表現の描画ビューにグローバルな条件付けを課すために、インターネットスケールのデータで学習された堅牢な2Dイメージ拡散事前分布を使用して、単語のプロンプトを使用しています。これらの手法は、優れたオブジェクト中心の生成物を生み出すことができますが、複数のユニークな特徴を持つシーンを生成するためには支援が必要です。グローバルな条件付けは、ユーザー入力が単一のテキストプロンプトに制限され、作成されたシーンのデザインに影響を与える方法がないため、制御性を制限します。Stanfordの研究者は、局所的な条件付き拡散と呼ばれる拡散モデルを使用した構成的なテキストからイメージへの生成手法を提供しています。 彼らの提案手法は、テキストプロンプトと3Dバウンディングボックスを入力として使用し、個々のオブジェクトのサイズと位置を制御しながら、一貫性のある3Dセットを構築します。彼らのアプローチでは、入力セグメンテーションマスクと一致するテキストプロンプトを使用して特定の部分の画像に条件付き拡散ステージを選択的に適用し、ユーザー指定の構成に従って出力を生成します。スコア蒸留サンプリングに基づくテキストから3D生成パイプラインに彼らの手法を組み込むことで、彼らは構成的なテキストから3Dシーンを作成することもできます。 彼らは具体的に以下の貢献を提供しています: • 2D拡散モデルにより構成的な柔軟性を持たせる局所的な条件付け拡散を提案します。 • 構成的な3D生成に不可欠な重要なカメラの姿勢サンプリング手法を提案します。 • スコア蒸留サンプリングベースの3D生成パイプラインに局所的な条件付け拡散を追加することで、構成的な3D合成の手法を紹介します。

「Amazon SageMaker Studioを使用してAmazon RedshiftクラスターのクロスアカウントアクセスをVPCピアリングで構成する」
クラウドコンピューティングにより、計算能力とデータがより利用可能になったことで、機械学習(ML)は今やあらゆる産業に影響を与え、すべてのビジネスや産業の核となっていますAmazon SageMaker Studioは、ウェブベースの視覚的なインターフェースを持つ、初めての完全統合型ML開発環境(IDE)ですすべてのML開発を行うことができます[…]
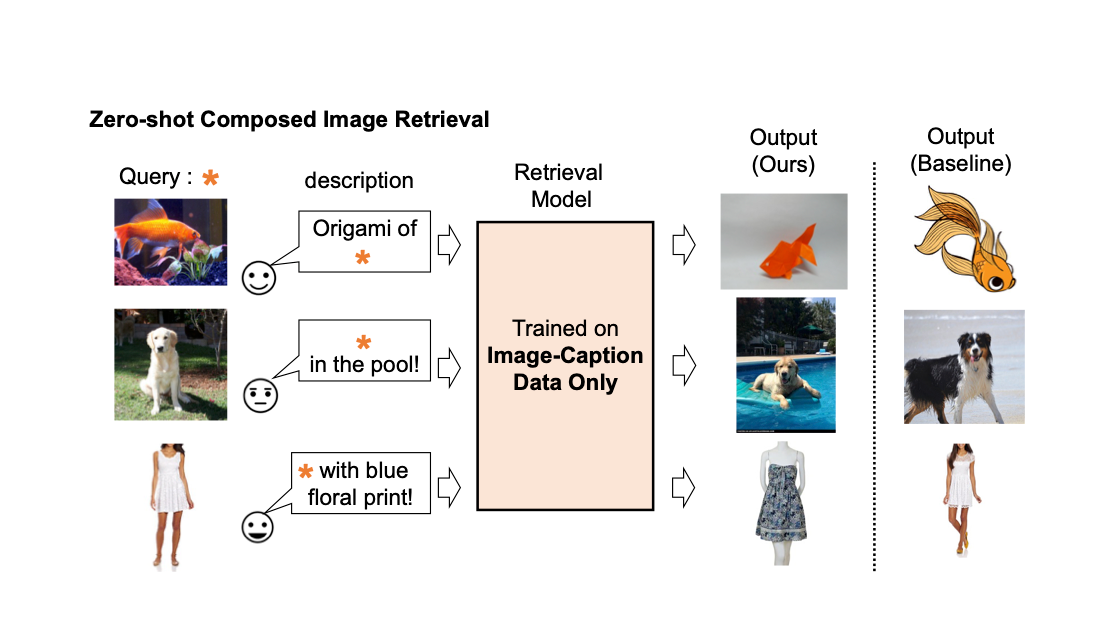
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。 しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。 これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。 既存の組み合わせ画像検索モデルの説明。 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 手法の概要 私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。 トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 評価 さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。 ドメイン変換 まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。 教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。 ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。…

Allen Institute for AI の研究者が、自然言語の指示に基づいて複雑で構成的な視覚的タスクを解決するための神経記号アプローチである VISPROG を紹介します
汎用AIシステムを探すことで、熟練したエンドツーエンドトレーニングモデルの開発が促進され、多くのモデルがユーザーがモデルと対話するためのシンプルな自然言語インターフェースを提供することを目的としています。大規模な自己教示学習に続く監視多目的学習がこれらのシステムを開発するための最も一般的な方法でした。彼らは最終的に、これらのシステムが困難なジョブの無限長尾にスケールするように望んでいます。しかしながら、この戦略は各タスクについて慎重に選択されたデータセットが必要です。自然言語で述べられた困難なアクティビティを、エンドツーエンドトレーニングされた特殊なモデルや他のプログラムが処理できるように、より単純なフェーズに分解することにより、この作業では大言語モデルを使用して複雑なタスクの長い尾を処理する方法について研究しています。 「この画像からBig Bang Theoryの7人の主要キャラクターをタグ付けしてください」とコンピュータビジョンプログラムに伝えます。システムは、以下の手順を実行する前に、指示の目的を最初に理解する必要があります。顔を検出し、知識ベースからBig Bang Theoryの主要キャラクターのリストを取得し、キャラクターリストを使用して顔を分類し、認識されたキャラクターの名前と顔を画像にタグ付けします。いくつかのビジョンおよび言語システムが各タスクを実行できますが、自然言語タスクの実行はエンドツーエンドトレーニングシステムの範囲外です。 図1:組成ビジュアル推論のためのモジュラーで解釈可能なニューロシンボリックシステム-VISPROG。 VISPROGは、自然言語の指示の少数のインスタンスと必要な高レベルのプログラムが与えられたGPT-3内の文脈学習を使用して、新しい指示ごとにプログラムを作成し、プログラムを入力画像に実行して予測を取得します。さらに、VISPROGは中間出力を理解可能な視覚的な正当化に縮小します。知識検索、算術、論理操作のさまざまなモジュールを組み合わせる呼び出しを行うジョブを実行するためにVISPROGを使用します。また、画像の分析と操作にも使用します。 AI研究所の研究者は、VISPROGと呼ばれるプログラムを提案しました。このプログラムは、視覚情報(単一の画像または画像のコレクション)と自然言語命令を入力とし、一連の命令、すなわちビジュアルプログラムを作成し、これらの命令を実行して必要な結果を生成します。ビジュアルプログラムの各行は、システムが現在サポートしている多くのモジュールの1つを呼び出します。モジュールは、事前に構築された言語モデル、OpenCV画像処理サブルーチン、算術および論理演算子であることができます。また、事前に構築されたコンピュータビジョンモデルにすることもできます。コードの前の行を実行して生成された入力は、モジュールによって消費され、後で使用できる中間出力を生成します。 前述の例では、VISPROGが作成したビジュアルプログラムで、顔検出器、GPT-3を知識検索システムとして、CLIPをopen-vocabulary画像分類器として使用して必要な出力を提供します(図1を参照)。VISPROGによってビジョンアプリケーションのプログラムの生成と実行の両方が向上します。ニューラルモジュールネットワーク(NMN)は、専門の、微分可能なニューラルモジュールを組み合わせて、ビジュアル質問応答(VQA)問題のための質問固有のエンドツーエンドトレーニング可能なネットワークを作成します。これらの方法は、REINFORCEの弱い回答監視を使用してレイアウトジェネレータをトレーニングするか、脆弱な、事前に構築された意味解析器を使用してモジュールのレイアウトを決定的に生成します。 対照的に、VISPROGは、強力な言語モデル(GPT-3)と文脈に限定された例を使用して、事前のトレーニングなしに複雑なプログラムを構築できるようにします。訓練された最先端のモデル、非ニューラルPythonサブルーチン、およびNMNよりも高い抽象レベルを呼び出すことにより、VISPROGプログラムはNMNよりも抽象的です。これらの利点により、VISPROGは迅速で効果的で柔軟なニューロシンボリックシステムです。さらに、VISPROGは非常に解釈可能です。まず、VISPROGは、ユーザーが確認できる論理的な正確さを持つ理解しやすいプログラムを作成します。第二に、予測を管理可能な部分に分解することにより、VISPROGはユーザーが中間段階の結果を調べて欠陥を見つけ、必要に応じてロジックを修正できるようにします。 予測の視覚的な正当化として、テキスト、バウンディングボックス、セグメンテーションマスク、生成された画像などの中間ステップの出力が接続された完成したプログラムが、情報の流れを示すために役立ちます。彼らはVISPROGを4つの異なる活動に使用して、その汎用性を紹介しています。これらのタスクには、一般的なスキル(画像解析など)が必要ですが、専門的な思考力と視覚的な操作スキルも必要です。これらのタスクには以下が含まれます: 構成的な視覚的質問に答えること。 画像ペアに対するゼロショットNLVR。 NL指示からの事実知識オブジェクトラベリング。 言語による画像操作。 彼らは、モジュールまたは言語モデルのいずれもが変更されていないことを強調しています。自然言語のコマンドと適切なプログラムのいくつかの文脈の例があれば、VISPROGを任意のタスクに適応することができます。VISPROGは使いやすく、構成的なVQAテストで2.7ポイントの大幅な利益、NLVRのゼロショットの正確さが62.4%、そして知識タグ付けと画像編集のタスクでの質的・量的な結果が良好です。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.