「自然言語処理のマスタリングへの7つのステップ」
「美容とファッション業界でのマスタリングへの7つのステップ」

自然言語処理(NLP)に取り組むには、これほどワクワクする時代はありません。機械学習モデルの構築経験があり、自然言語処理を探求したいと思っている場合は、ChaGPTのようなLLMパワードアプリケーションを使用した経験があるかもしれません。そして、それらの有用性を認識し、自然言語処理に深く没頭したいと思うかもしれません。
もちろん、他にも理由はあるかもしれません。でも、ここに来た以上、NLPについて学ぶための7つのステップガイドを紹介します。各ステップでは以下を提供します:
- 学び、理解すべき概念の概要
- いくつかの学習リソース
- 構築できるプロジェクト
さあ、始めましょう。
ステップ1:Pythonと機械学習
まず、Pythonプログラミングで堅固な基盤を築く必要があります。また、データ操作のためのNumPyやPandasなどのライブラリに熟達することも必要です。NLPに取り組む前に、データ前処理や探索から評価と選択まで、一般的に使用される教師あり学習と教師なし学習アルゴリズムを含む機械学習モデルの基礎を押さえましょう。
Scikit-Learnのようなライブラリを使えるようになると、機械学習アルゴリズムの実装が容易になります。
要点をまとめると、以下のことを知っておく必要があります:
- Pythonプログラミング
- NumPyやPandasなどのライブラリに習熟していること
- データ前処理から探索、評価、選択までの機械学習の基礎
- 教師あり学習と教師なし学習の両方に精通していること
- Pythonでの機械学習のためのScikit-Learnなどのライブラリ
こちらのfreeCodeCampによるScikit-Learnクラッシュコースを見てみてください。
以下は、取り組むことができるいくつかのプロジェクトです:
- 住宅価格予測
- ローン不履行予測
- 顧客セグメンテーションのためのクラスタリング
ステップ2:ディープラーニングの基礎
機械学習に習熟し、モデルの構築や評価に慣れた後は、ディープラーニングに進むことができます。
まず、ニューラルネットワークとその構造、データの処理方法について理解しましょう。活性化関数、損失関数、および最適化アルゴリズムについて学びます。これらはニューラルネットワークのトレーニングに必須です。
バックプロパゲーションと勾配降下法という概念について理解し、実際の実装にはTensorFlowやPyTorchなどのディープラーニングフレームワークに慣れることが重要です。
要点をまとめると、以下のことを知っておく必要があります:
- ニューラルネットワークとそのアーキテクチャ
- 活性化関数、損失関数、最適化アルゴリズム
- バックプロパゲーションと勾配降下法
- TensorFlowやPyTorchなどのフレームワーク
以下のリソースは、PyTorchとTensorFlowの基礎を学ぶのに役立ちます:
以下のプロジェクトで学んだことを実践してみましょう:
- 手書き数字認識
- CIFAR-10などの画像分類
ステップ3:NLP 101および基本的な言語学の概念
まずは、NLPとその広範な応用、感情分析から機械翻訳、質問応答などを理解することから始めましょう。テキストをより小さな単位(トークン)に分割するトークン化など、言語学的な概念を理解しましょう。語幹処理や見出し語化など、単語をその原形に縮小する技術についても学びます。
また、品詞タグ付けや固有表現認識などのタスクについても探求します。
要点をまとめると、以下のことを理解する必要があります:
- NLPの概要とその応用
- トークン化、語幹処理、見出し語化
- 品詞タグ付けと固有表現認識
- 構文、意味、依存解析などの基本的な言語学の概念
CS 224nの依存構造解析の講義は、言語学の概念についての良い概要を提供しています。無料の書籍Pythonによる自然言語処理(NLTK)も参考資料としておすすめです。
自分の選択したユースケース(履歴書やその他のドキュメントの解析)において、Named Entity Recognition(NER)アプリを作成してみてください。
ステップ4:伝統的な自然言語処理技術
NLPを革新する前の伝統的な技術が基盤を築いています。テキストデータを機械学習モデルに数値形式に変換するためのBag of Words(BoW)およびTF-IDF表現について理解する必要があります。
単語の文脈を捉えるN-gramと、テキスト分類におけるその応用について学びましょう。また、感情分析やテキスト要約の技術も探求してください。さらに、品詞タグ付けなどのためのHidden Markov Models(HMMs)やトピックモデリングのためのLatent Dirichlet Allocation(LDA)など、他のアルゴリズムも理解してください。
以下に精通する必要があります:
- Bag of Words(BoW)およびTF-IDF表現
- N-gramとテキスト分類
- 感情分析、トピックモデリング、およびテキスト要約
- 品詞タグ付けのためのHidden Markov Models(HMMs)
学習に役立つリソース:Pythonでの自然言語処理の完全なチュートリアル
また、いくつかのプロジェクトのアイデア:
- スパム分類器
- ニュースフィードなどのデータセットにおけるトピックモデリング
ステップ5:深層学習を用いた自然言語処理
今点で、NLPと深層学習の基礎的な知識についてはお馴染みです。さて、深層学習の知識をNLPのタスクに適用してみましょう。まずはWord2VecやGloVeなどの単語埋め込みを始めてください。これらは、単語を密なベクトルとして表現し、意味的な関係を捉えるものです。
次に、Sequentialデータの処理におけるRecurrent Neural Networks(RNNs)などのシーケンスモデルについて探求しましょう。Long Short-Term Memory(LSTM)やGated Recurrent Units(GRU)について理解しましょう。これらは、テキストデータの長期的な依存関係を捉える能力で知られています。また、機械翻訳などのタスクにおけるシーケンス-シーケンスモデルも探求してみてください。
要約すると:
- RNNs
- LSTMおよびGRUs
- シーケンス-シーケンスモデル
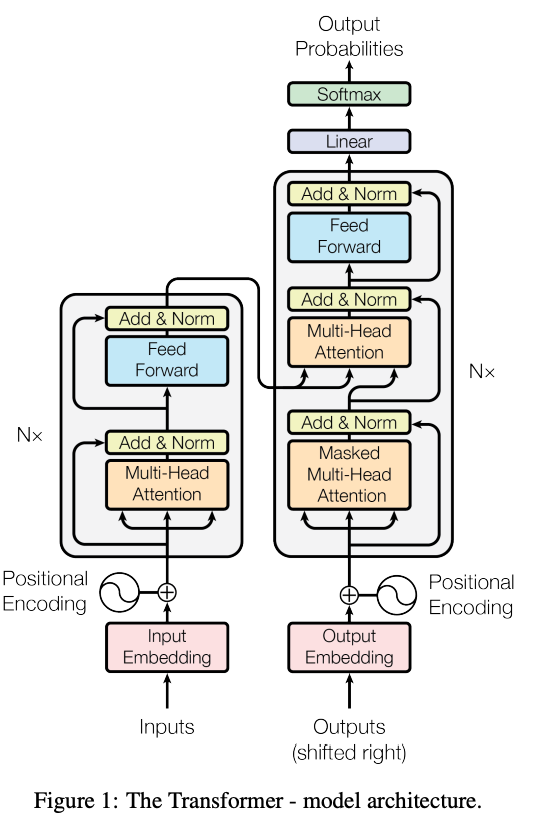
最も総合的なTransformersによるNLPの学習リソースは、HuggingFaceチームによるTransformerコースです。
ビルドできる興味深いプロジェクトには:
- 顧客チャットボット/バーチャルアシスタント
- テキストにおける感情検出
ステップ7:プロジェクトの構築、学習の継続、最新情報の把握
自然言語処理(または一般的などの)急速に進歩する分野では、より困難なプロジェクトを経験しながら学び続け、進歩していくことが不可欠です。
実践的な経験を提供し、概念の理解を強化するために、プロジェクトに取り組むことが重要です。さらに、ブログ、研究論文、オンラインコミュニティを通じてNLP研究コミュニティと連携することで、NLPの最新の進歩に遅れを取らないようにすることができます。
OpenAIのChatGPTは2022年末に市場に登場し、GPT-4は2023年初にリリースされました。同時に(目にしており、今でも目にしている)多数のオープンソースの大規模言語モデル、LLMを活用したコーディングアシスタント、革新的でリソース効率の高いファインチューニング技術などがリリースされています。
LLMのスキルを向上させたい場合、以下の2部構成の役立つリソースをご紹介します:
また、LangchainやLlamaIndexなどのフレームワークを活用して、有用で興味深いLLMを活用したアプリケーションを開発することもできます。
最後に
このNLPのマスターのためのガイドが役に立つことを願っています。以下に、7つのステップの概要をご紹介します:
- ステップ1:Pythonと機械学習の基礎
- ステップ2:ディープラーニングの基礎
- ステップ3:NLP 101および基本的な言語学の概念
- ステップ4:伝統的なNLP技術
- ステップ5:NLPのためのディープラーニング
- ステップ6:トランスフォーマーを使ったNLP
- ステップ7:プロジェクトの構築、学習の継続、最新の情報を把握
チュートリアル、プロジェクトの解説などをお探しの場合は、VoAGIのNLPリソースのコレクションをチェックしてください。
Bala Priya Cは、インド出身の開発者兼技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での作業が好きです。彼女の関心と専門知識の範囲には、DevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、そしてコーヒーを楽しみます!現在は、チュートリアル、解説ガイド、意見記事などを作成することによって、開発者コミュニティと彼女の知識を共有するための学習に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles