「データクリーニングと前処理の技術をマスターするための7つのステップ」
7 Steps to Master Data Cleaning and Preprocessing Techniques
データクリーニングおよび前処理技術の習得は、多くのデータサイエンスプロジェクトを解決するために必要な基礎です。データサイエンスを学ぶ学生の期待と、実際のデータサイエンティストの仕事の現実を比較したミームでも、その重要性を簡単に示すことができます。
実際の経験を持つ前は、職種を理想化してしまいがちですが、現実は常に予想とは異なるものです。実世界の問題に取り組む際には、データのドキュメントがなく、データセットが非常に汚れていることがよくあります。まず、問題について深く掘り下げ、どのような手がかりが欠けているのか、どのような情報を抽出できるのかを理解する必要があります。
問題を理解した後、データセットを機械学習モデルに適した形に整える必要があります。初期状態のデータは十分ではないためです。この記事では、データセットの前処理とクリーニングに役立つ7つのステップを紹介します。
- 「LP-MusicCapsに会ってください:データの乏しさ問題に対処するための大規模言語モデルを使用したタグから疑似キャプション生成アプローチによる自動音楽キャプション作成」
- 「ゼロから効果的なデータ品質戦略を構築するためのステップバイステップガイド」
- 「貪欲であることはどれほど悪いのか?」
ステップ1:探索的データ分析
データサイエンスプロジェクトの最初のステップは、探索的分析です。これにより、問題を理解し、次のステップで意思決定することができます。このステップをスキップすることはよくありますが、後でモデルがエラーを返したり、期待通りのパフォーマンスを発揮しなかった理由を見つけるために時間を無駄にすることになります。
データサイエンティストとしての経験に基づいて、探索的分析を以下の3つのパートに分けることができます:
- データセットの構造、統計量、欠損値、重複値、カテゴリ変数の一意の値をチェックすること
- 変数の意味と分布を理解すること
- 変数間の関係を研究すること
データセットの構造を分析するためには、次のPandasのメソッドが役立ちます:
df.head()
df.info()
df.isnull().sum()
df.duplicated().sum()
df.describe([x*0.1 for x in range(10)])
for c in list(df):
print(df[c].value_counts())
変数を理解しようとする際には、数値特徴とカテゴリ特徴に分けて分析することが有用です。まず、ヒストグラムや箱ひげ図を通じて可視化できる数値特徴に焦点を当てることができます。次に、カテゴリ変数に注目します。バイナリ問題の場合は、クラスがバランスしているかどうかを確認するのが良いでしょう。その後は、残りのカテゴリ変数について、棒グラフを使用して分析します。最後に、数値変数の各ペア間の相関関係を確認することができます。その他、散布図や箱ひげ図などのデータの視覚化も有用です。数値変数とカテゴリ変数の関係を観察するために使用できます。
ステップ2:欠損値の処理
最初のステップで、各変数に欠損値があるかどうかを調査しました。欠損値がある場合、その問題の処理方法を理解する必要があります。最も簡単な方法は、NaN値を含む変数または行を削除することですが、問題を解決するために役立つ情報を失う可能性があるため、避ける方が良いでしょう。
数値変数を扱う場合、欠損値を埋めるためのいくつかのアプローチがあります。最も人気のある方法は、欠損値をその特徴の平均値/中央値で埋めることです:
df['age'].fillna(df['age'].mean())
df['age'].fillna(df['age'].median())
別の方法として、グループごとの代入を使用してブランクを置き換える方法があります:
df['price'].fillna(df.group('type_building')['price'].transform('mean'),
inplace=True)
数値特徴とカテゴリ特徴の間に強い関係がある場合、これはより良いオプションになるかもしれません。
同様に、カテゴリ変数の欠損値をその変数の最頻値で埋めることができます:
df['type_building'].fillna(df['type_building'].mode()[0])
ステップ3:重複値と外れ値の処理
データセット内に重複がある場合は、重複する行を削除する方が良いです:
df = df.drop_duplicates()
重複の処理方法は簡単ですが、外れ値の処理は難しいことがあります。自分自身に「外れ値を除外するかどうか?」と尋ねる必要があります。
外れ値は、ノイズのみを提供することが確かである場合に削除するべきです。例えば、データセットには年齢が0から90の範囲内であるのに対して、200歳の2人のデータが含まれている場合、これらのデータポイントを削除する方が良いです。
df = df[df.Age<=90]
残念ながら、外れ値を削除することは重要な情報を失う可能性がほとんどです。最も効率的な方法は、数値特徴に対して対数変換を適用することです。
私の最後の経験で見つけたもう1つの技術は、クリッピングメソッドです。この技術では、上限と下限を選択します。下限は0.1パーセンタイル、上限は0.9パーセンタイルであることがあります。下限以下の特徴の値は下限値に置き換えられ、上限以上の値は上限値に置き換えられます。
for c in columns_with_outliers:
transform= 'clipped_'+ c
lower_limit = df[c].quantile(0.10)
upper_limit = df[c].quantile(0.90)
df[transform] = df[c].clip(lower_limit, upper_limit, axis = 0)
ステップ4:カテゴリカル特徴量のエンコード
次のフェーズでは、カテゴリカル特徴量を数値特徴量に変換します。実際、機械学習モデルは数値のみで動作するため、文字列では動作しません。
さらに進む前に、2つのタイプのカテゴリ変数を区別する必要があります:非順序変数と順序変数。
非順序変数の例は、性別、婚姻状況、仕事のタイプです。変数が順序に従わない場合は非順序ですが、順序特徴量とは異なります。順序変数の例は、教育(値が「子供時代」、「小学校」、「中学校」、「大学」など)や所得(「低所得」、「中所得」、「高所得」など)です。
非順序変数を扱う場合、最も一般的なテクニックはワンホットエンコーディングです。
この方法では、カテゴリ特徴量の各レベルに対して新しいバイナリ変数を作成します。各バイナリ変数の値は、レベルの名前がレベルの値と一致する場合に1になり、それ以外の場合は0になります。
from sklearn.preprocessing import OneHotEncoder
data_to_encode = df[cols_to_encode]
encoder = OneHotEncoder(dtype='int')
encoded_data = encoder.fit_transform(data_to_encode)
dummy_variables = encoder.get_feature_names_out(cols_to_encode)
encoded_df = pd.DataFrame(encoded_data.toarray(), columns=encoder.get_feature_names_out(cols_to_encode))
final_df = pd.concat([df.drop(cols_to_encode, axis=1), encoded_df], axis=1)
変数が順序の場合、最も一般的に使用されるテクニックは順序エンコーディングです。これは、カテゴリ変数の一意の値を、順序に従う整数に変換するものです。例えば、所得のレベル「低所得」、「中所得」、「高所得」は、それぞれ0、1、2としてエンコードされます。
from sklearn.preprocessing import OrdinalEncoder
data_to_encode = df[cols_to_encode]
encoder = OrdinalEncoder(dtype='int')
encoded_data = encoder.fit_transform(data_to_encode)
encoded_df = pd.DataFrame(encoded_data.toarray(), columns=["Income"])
final_df = pd.concat([df.drop(cols_to_encode, axis=1), encoded_df], axis=1)
他にもエンコーディング技術は存在しますので、興味があればここで探索できます。代替手法に興味がある場合は、こちらをご覧ください。
ステップ5:データセットをトレーニングセットとテストセットに分割する
データセットを3つの固定のサブセットに分割する時が来ました。最も一般的な選択肢は、トレーニングに60%、検証に20%、テストに20%を使用することです。データの量が増えるにつれて、トレーニングの割合が増え、検証とテストの割合が減少します。
3つのサブセットを持つことは重要です。トレーニングセットはモデルのトレーニングに使用され、バリデーションセットとテストセットはモデルが新しいデータでどのように動作しているかを理解するために役立ちます。
データセットを分割するために、scikit-learnのtrain_test_splitを使用することができます:
from sklearn.model_selection import train_test_split
X = final_df.drop(['y'],axis=1)
y = final_df['y']
train_idx, test_idx,_,_ = train_test_split(X.index,y,test_size=0.2,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,random_state=123)
df_train = final_df[final_df.index.isin(train_idx)]
df_test = final_df[final_df.index.isin(test_idx)]
df_val = final_df[final_df.index.isin(val_idx)]分類問題でクラスのバランスが取れていない場合は、トレーニング、バリデーション、テストセットのクラスの比率が同じであることを確認するためにstratify引数を設定することがベターです。
train_idx, test_idx,y_train,_ = train_test_split(X.index,y,test_size=0.2,stratify=y,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,stratify=y_train,random_state=123)この層化交差検証は、3つのサブセットにおいて目的変数の割合が同じであることを保証し、モデルのより正確なパフォーマンスを提供するのにも役立ちます。
ステップ6:特徴のスケーリング
線形回帰、ロジスティック回帰、KNN、サポートベクターマシン、ニューラルネットワークなど、特徴のスケーリングが必要な機械学習モデルがあります。特徴のスケーリングは、変数を同じ範囲にするだけで、分布を変えずに行います。
最も一般的な特徴のスケーリング手法は、正規化、標準化、ロバストスケーリングの3つです。
正規化(ミニマックススケーリングとも呼ばれる)は、変数の値を0から1の範囲にマッピングすることで実現します。これは、特徴の値から特徴の最小値を引き、その差で最大値と最小値の間の差で除算することで可能です。
from sklearn.preprocessing import MinMaxScaler
sc=MinMaxScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])もう一つの一般的なアプローチは標準化で、列の値を標準正規分布の特性に従うように再スケールします。これは平均が0で分散が1である標準正規分布の特性を尊重するためです。
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])外れ値が含まれていて削除できない場合、より好ましい方法はロバストスケーリングです。これは、中央値、第1四分位数、第3四分位数に基づいて特徴の値を再スケールします。再スケーリングされた値は、元の値から中央値を引き、その後、特徴の第75パーセンタイルと第25パーセンタイルの間の差で除算することによって得られます。
from sklearn.preprocessing import RobustScaler
sc=RobustScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])一般的には、統計量をトレーニングセットを基に計算し、それらをトレーニング、バリデーション、テストセットの値の再スケーリングに使用することが好ましいです。これは、トレーニングデータしか持っていないと仮定し、後で新しいデータでモデルをテストすることを意図しているためであり、その新しいデータはトレーニングセットと同様の分布を持つはずです。
ステップ7:不均衡データの処理
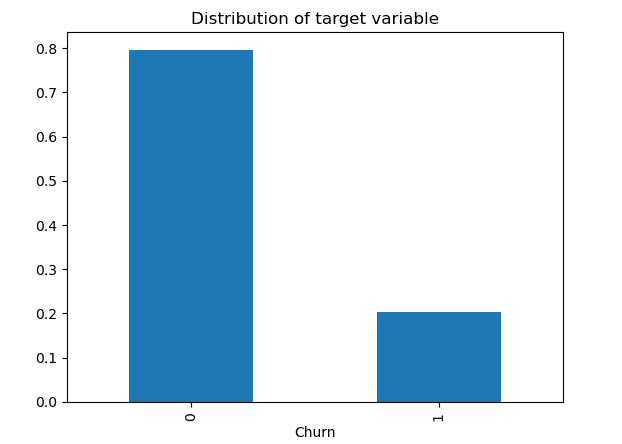
このステップは、分類問題でクラスが不均衡であることが判明した場合にのみ含まれます。
例えば、クラス1が観測の40%を含み、クラス2が残りの60%を含んでいる場合、片方のクラスのサンプル数を変更するためにオーバーサンプリングやアンダーサンプリングの技術を適用する必要はありません。データセットがバランスしている場合にのみ優れた指標である正確性に注目する必要はなく、適合率、再現率、F1スコアなどの評価指標にのみ注意すれば十分です。
しかし、肯定的なクラスのデータポイントの割合が非常に低い(0.2)のに対して、ネガティブなクラス(0.8)と比較して非常に低い割合のデータポイントを持つ場合があります。観測数が少ないクラスでは機械学習がうまく機能せず、タスクの解決に失敗する可能性があります。
この問題を解決するためには、2つの方法があります。多数派クラスのアンダーサンプリングと少数派クラスのオーバーサンプリングです。アンダーサンプリングは、多数派クラスからいくつかのデータポイントをランダムに削除することでサンプル数を減らすものであり、オーバーサンプリングは、少数派クラスの観測数を増やすために、より頻度の低いクラスからランダムにデータポイントを追加するものです。データセットをバランスさせるためのimblearnというライブラリがあり、数行のコードでバランスを取ることができます:
# アンダーサンプリング
from imblearn.over_sampling import RandomUnderSampler,RandomOverSampler
undersample = RandomUnderSampler(sampling_strategy='majority')
X_train, y_train = undersample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
# オーバーサンプリング
oversample = RandomOverSampler(sampling_strategy='minority')
X_train, y_train = oversample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
ただし、いくつかの観測を削除または複製することは、モデルのパフォーマンスの向上には時に効果がない場合があります。少数派クラスに新しい人工データポイントを作成する方が良いでしょう。この問題を解決するために提案された手法の1つがSMOTEです。これは、少数派クラスにおいて合成レコードを生成することで知られています。KNNのように、少数派クラスに属する観測のk個の最近傍の観測を特定し、特定の距離(たとえばt)に基づいて、これらのk個の最近傍の間のランダムな場所に新しい点が生成されます。このプロセスは、データセットが完全にバランスするまで新しい点を作成し続けます。
from imblearn.over_sampling import SMOTE
resampler = SMOTE(random_state=123)
X_train, y_train = resampler.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
これらのアプローチは、トレーニングセットのリサンプリングにのみ適用する必要があります。機械モデルが堅牢に学習し、新しいデータに対して予測を行うことができるようにしたいのです。
最後の考察
この包括的なチュートリアルが役立つことを願っています。これらの技術について十分に理解せずに最初のデータサイエンスプロジェクトを始めることは難しいかもしれません。私のコードはこちらで見つけることができます。
この記事では取り上げなかった他の手法も確かにありますが、私は最も人気があり知られている手法に焦点を当てることを選びました。他に提案はありますか?有益な提案があれば、コメントに投稿してください。
役立つリソース:
- 探索的データ分析のための実践的ガイド
- どのモデルが正規化されたデータを必要とするか?
- 不均衡な分類のためのランダムオーバーサンプリングとアンダーサンプリング
Eugenia Anelloは現在、イタリアのパドヴァ大学情報工学部で研究フェローを務めています。彼女の研究プロジェクトは連続学習と異常検知を組み合わせたものに焦点を当てています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
