「大型言語モデル(LLM)のマスターに至る7つのステップ」
『LLM(大型言語モデル)マスターへの道:7つのステップ』
GPT-4、Llama、Falconなど、その他多くの――大規模言語モデル――LLMは、今年のトピックでありまさに話題です。もしあなたがこれを読んでいるなら、チャットインターフェースやAPIを介して、すでに1つまたは複数のこれらの大規模言語モデルを使用したことがあるかもしれません。
もしLLMが一体何なのか、どのように機能し、何を構築できるかについて疑問を抱いたことがあるなら、このガイドはあなたのためです。大規模言語モデルに興味のあるデータ専門家や単に興味を持っている人を対象に、LLMの領域を詳しく説明します。
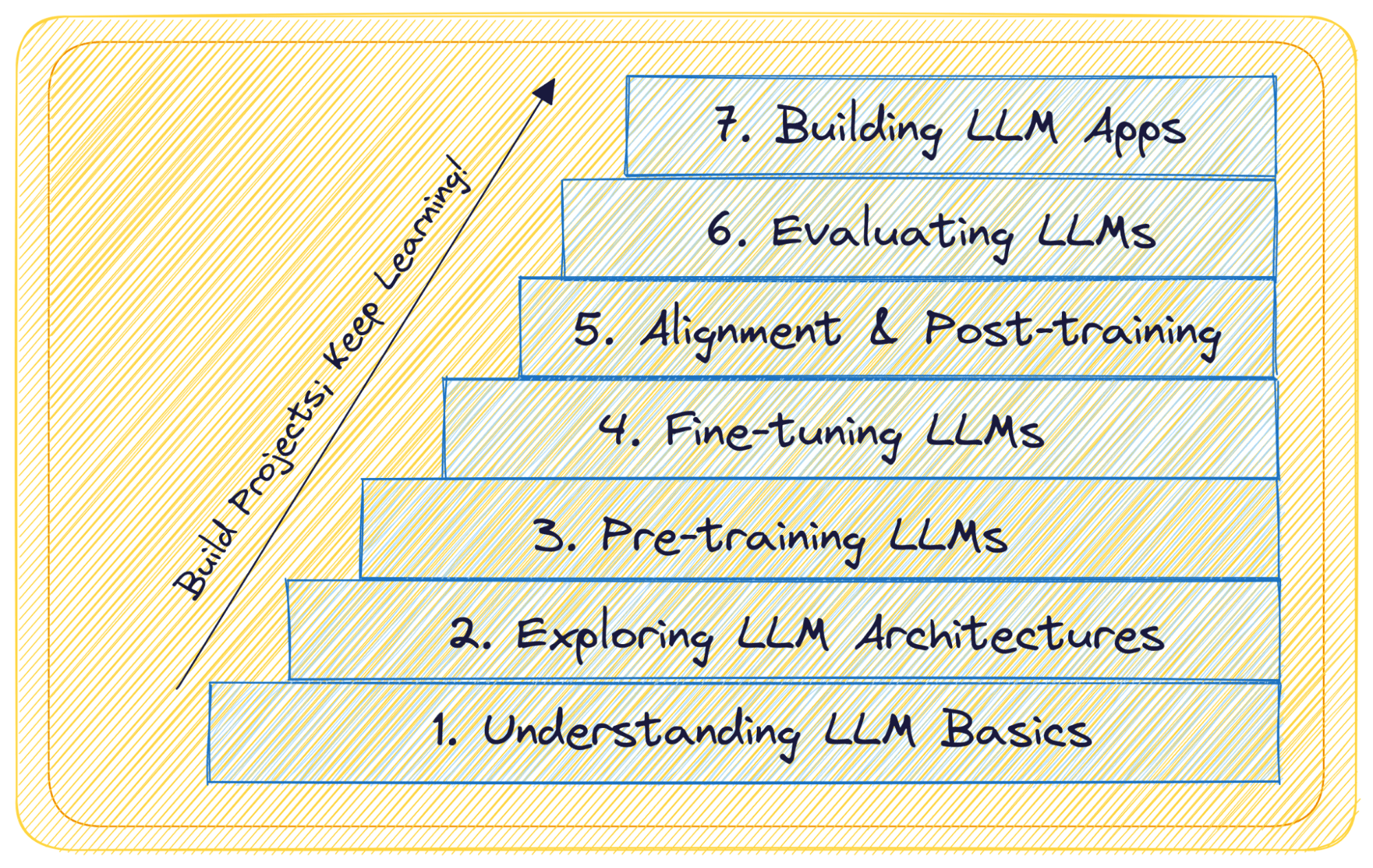
LLMの基本的な内容からLLMを使ってアプリケーションを構築し、展開するまで、以下の7つの簡単なステップにわたって大規模言語モデルの学習について詳しく説明します:
- AIテクノロジーを使ってあなたの牛を見守る
- Amazon PersonalizeとAmazon OpenSearch Serviceの統合により、検索結果をパーソナライズします
- 「Amazon PharmacyはAmazon SageMakerを使用して、LLMベースのチャットボットを作成する方法を学びましょう」
- 知っておくべきこと
- 概要
- 学習のリソース
それでは、始めましょう!
ステップ1:LLMの基礎を理解する
大規模言語モデルに初めて触れる方には、LLMの概要を高レベルで把握することが役立ちます。以下の質問に答えてみることから始めましょう:
- LLMとは具体的に何ですか?
- なぜ彼らは人気があるのですか?
- LLMは他の深層学習モデルとどのように異なりますか?
- 一般的なLLMの使用例は何ですか?(既にご存じかもしれませんが、リストアップしておくことも良い運動です)
それらすべてに答えることができましたか?それでは、一緒にやってみましょう!
LLMとは何ですか?
大規模言語モデル、またはLLMは、膨大なテキストデータのコーパスを基にトレーニングされた深層学習モデルのサブセットです。これらは巨大なモデルであり、何十億ものパラメータを持ち、自然言語のさまざまなタスクで非常に優れたパフォーマンスを発揮します。
なぜ彼らは人気がありますか?
LLMは、一貫性があり、文脈に即した、文法的に正確なテキストを理解し生成する能力を持っています。彼らの人気や広範な採用の理由は以下の通りです:
- 幅広い言語タスクにおける優れたパフォーマンス
- 事前トレーニングされたLLMのアクセス性と利用可能性により、AIによる自然言語理解と生成が民主化された
では、LLMは他の深層学習モデルとどのように異なりますか?
LLMは、サイズとアーキテクチャが異なるため、他の深層学習モデルとは異なります。そのキーな違いは次の通りです:
- 自然言語処理を革新し、LLMの基盤となるトランスフォーマーアーキテクチャ
- テキスト内の長距離依存関係を捉え、より良い文脈理解を可能にする能力
- テキスト生成から翻訳、要約、質問応答まで、幅広い言語タスクの処理能力
LLMの一般的な使用例は何ですか?
LLMは、次のような言語タスクに応用されています:
- 自然言語理解:感情分析や固有表現認識、質問応答などのタスクにおいて優れたパフォーマンスを発揮
- テキスト生成:チャットボットや他のコンテンツ生成タスクで人間らしいテキストを生成する能力(もしChatGPTやその代替を使用したことがあれば、これはまったく驚くことではありません)
- 機械翻訳:LLMによって機械翻訳の品質が大幅に向上しました
- コンテンツ要約:LLMは長文書の簡潔な要約文を生成できます。YouTubeの動画の要約を試したことはありますか?
今では、LLMの概要とその能力について概観ができたので、さらに探求したい場合のいくつかのリソースを以下に紹介します:
ステップ2:LLMアーキテクチャの探索
LLMについて理解したので、これらのパワフルなLLMの基盤となるトランスフォーマーアーキテクチャを学ぶための次のステップに進みましょう。つまり、あなたのLLMの旅では、トランスフォーマーがすべての注意を必要とします(貴重な意味での注意です)。
論文「Attention Is All You Need」で紹介されたオリジナルのトランスフォーマーアーキテクチャは、自然言語処理を革新しました。
- 主な特徴:自己注意層、マルチヘッド注意、前方伝播型ニューラルネットワーク、エンコーダーデコーダーアーキテクチャ
- 使用例:トランスフォーマーは、BERTやGPTなどの著名なLLMの基盤となっています。
オリジナルのトランスフォーマーアーキテクチャはエンコーダーデコーダーアーキテクチャを使用しますが、エンコーダーのみやデコーダーのみのバリエーションも存在します。以下では、これらの詳細、著名なLLM、使用例について包括的な概要を提供します。
|
主な特徴 | 著名なLLM | 使用例 |
|
双方向の文脈を捉え、自然言語理解に適したアーキテクチャ |
ベースのRoBERTa、XLNet |
分類 – 質問応答 |
|
単方向の言語モデル;自己回帰的な生成 |
|
|
| エンコーダーデコーダー | 入力テキストから対象のテキストへの変換;任意のテキスト対テキストタスク |
|
分類 |
トランスフォーマーについて学ぶための素晴らしいリソースは以下の通りです:
- Attention Is All You Need(必読)
- Jay Alammarによるイラスト付きトランスフォーマー
- Stanford CS324のモデリングモジュール:大規模言語モデル
- HuggingFace Transformersコース
ステップ3:LLMの事前学習
Large Language Models (LLMs)とトランスフォーマーアーキテクチャの基礎を知ったので、LLMの事前学習について学ぶことができます。事前学習は、LLMの基盤を形成するために大量のテキストデータにさらすことで、言語の側面やニュアンスを理解することを可能にします。
以下は知っておくべき概念の概要です:
- 事前学習LLMの目的:LLMに大量のテキストコーパスを公開して、言語パターン、文法、文脈を学習させること。特定の事前学習タスク(マスクされた言語モデリングや次の文予測など)について学ぶ。
- LLM事前学習のテキストコーパス:LLMは、ウェブ記事、書籍、その他のソースなど、大量かつ多様なテキストコーパスで訓練されます。これらは数十億から数兆のテキストトークンを持つ大規模なデータセットです。一般的なデータセットには、C4、BookCorpus、Pile、OpenWebTextなどがあります。
- トレーニング手順:最適化アルゴリズム、バッチサイズ、トレーニングエポックなどの事前学習の技術的側面を理解する。データの偏りを軽減するなどの課題について学ぶ。
もっと学びたい場合は、CS324:大規模言語モデルのLLMトレーニング モジュールを参照してください。
このような事前学習済みLLMは、特定のタスクのファインチューニングの出発点となります。ファインチューニングLLMが次のステップです!
ステップ4:LLMのファインチューニング
大量のテキストコーパスでLLMを事前学習した後、次のステップは特定の自然言語処理タスクに対してLLMをファインチューニングすることです。ファインチューニングによって、事前学習済みモデルを特定のタスク(感情分析、質問応答、翻訳など)により正確かつ効率的に適応させることができます。
なぜLLMをファインチューニングするのか
ファインチューニングは、以下の理由から必要です:
- 事前学習済みLLMは、一般的な言語理解を獲得しているが、特定のタスクでのパフォーマンスを向上させるためにはファインチューニングが必要です。そして、ファインチューニングによってモデルは対象タスクの微妙なニュアンスを学習します。
- ファインチューニングは、ゼロからモデルを訓練する場合と比べて、必要なデータと計算量を大幅に削減します。事前学習済みモデルの理解を活用するため、ファインチューニング用のデータセットは事前学習用のデータセットよりもはるかに小さくなる場合があります。
LLMのファインチューニング方法
では、LLMのファインチューニングの具体的な手順について説明します:
-
- 事前学習済みLLMの選択:タスクに合った事前学習済みLLMを選択します。例えば、質問応答のタスクを行う場合は、自然言語理解を促進するアーキテクチャを持つ事前学習済みモデルを選択します。
- データの準備:LLMに遂行させたい特定のタスク用のデータセットを準備します。ラベル付きの例が含まれ、適切な形式でフォーマットされていることを確認します。
- ファインチューニング:ベースのLLMを選択し、データセットを準備したら、実際にモデルをファインチューニングします。
- しかし、具体的にはどうやってファインチューニングするのでしょうか?
- パラメータ効率の良いテクニックはありますか?記憶すべきは、LLMは数百億のパラメータを持っています。重み行列は膨大です!
- 重みにアクセスできない場合はどうなりますか?
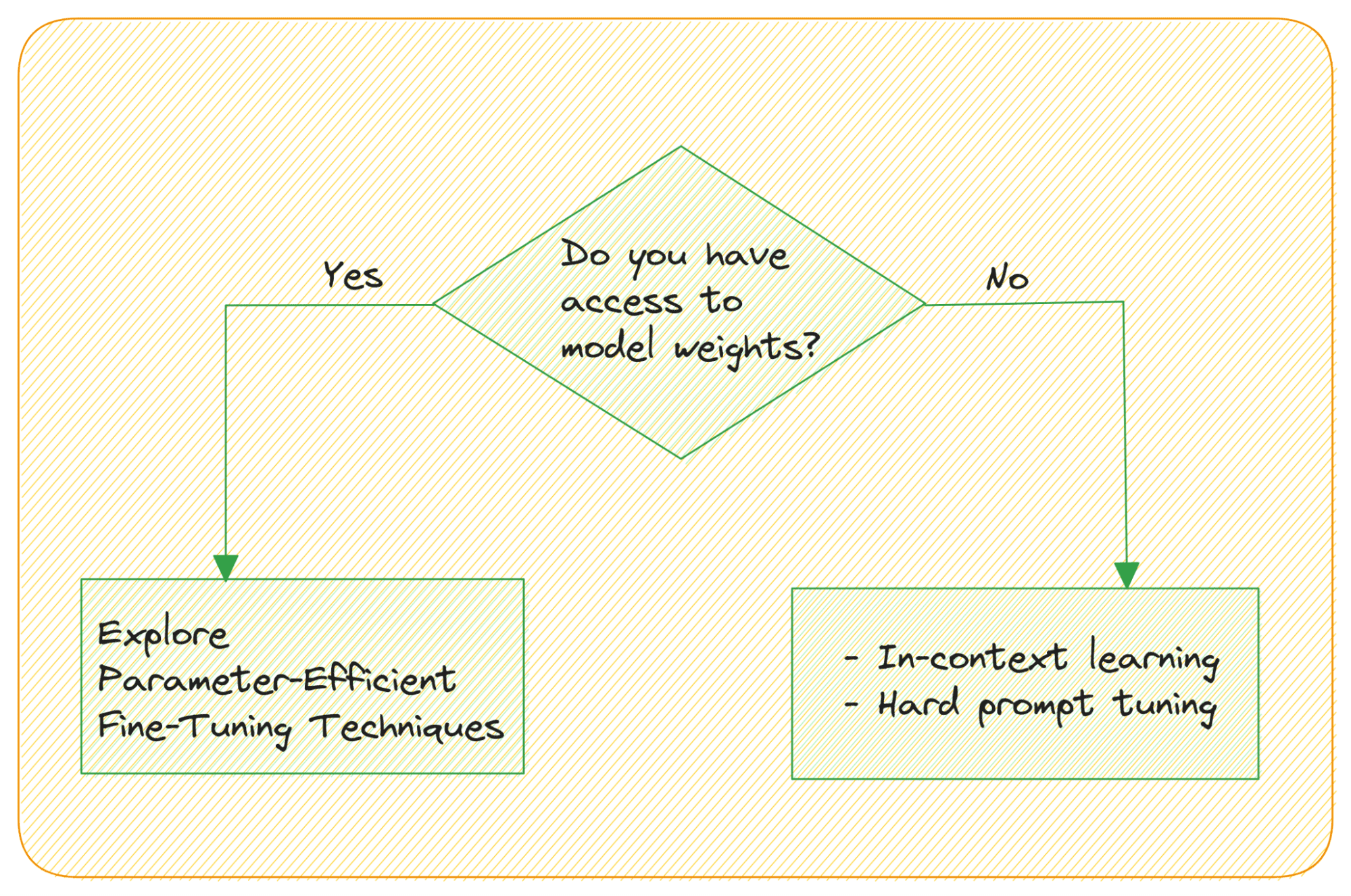
モデルの重みにアクセスすることができず、APIを通じてモデルにアクセスする場合、LLMのファインチューニングをどのように行いますか?大規模言語モデルは、入力を提供することによって文脈学習が可能であり、明示的なファインチューニングのステップは必要ありません。タスクのサンプル出力例を提供することによって、彼らの類推能力を活用することができます。
ハードプロンプトチューニングは、プロンプトの入力トークンを直接修正することを意味し、モデルの重みを更新しません。
ソフトプロンプトチューニングは、入力埋め込みと学習可能なテンソルを連結します。関連するアイデアとして、プレフィックスチューニングがあります。それは入力埋め込みだけでなく、各Transformerブロックに学習可能なテンソルを使用します。
ご紹介した通り、大規模な言語モデルには数百億のパラメータがあります。そのため、全ての層の重みを微調整することはリソースの消費量が多い作業です。最近では、LoRAやQLoRAのような「パラメータ効率の良い微調整技術(PEFT)」が人気となっています。QLoRAを使用すれば、単一の一般向けGPU上で4ビット量子化されたLLMを性能に影響を与えることなく微調整することができます。
これらの技術は、全体の重み行列の代わりに調整可能なパラメータである「アダプタ」を導入しています。以下は、LLMの微調整に関する情報を学ぶのに役立つリソースです:
- QLoRA is all you need – Sentdex
- Making LLMs even more accessible with bitsandbytes, 4-bit quantization, and QLoRA
ステップ 5:LLM のアラインメントと事後学習
大規模な言語モデルは、有害な、偏った、またはユーザーの実際の要望や期待と一致しないコンテンツを生成する可能性があります。アラインメントは、LLMの動作を人間の好みや倫理的な原則に合わせるプロセスを指します。バイアス、議論のある応答、有害なコンテンツの生成など、モデルの振る舞いに関連するリスクを軽減することを目指します。
以下のようなテクニックを探求することができます:
- 人間のフィードバックからの強化学習(RLHF)
- 対比的な事後学習
RLHFでは、LLMの出力に対する人間の好みの注釈を使用し、それらに対して報酬モデルを作成します。対比的な事後学習では、対比技術を活用して好みのペアを自動的に構築します。 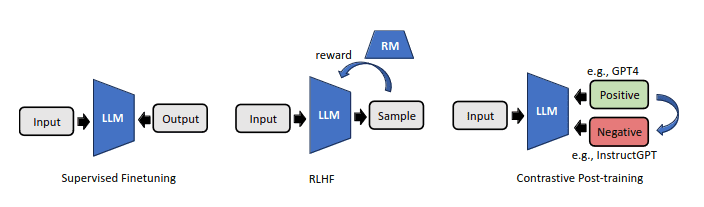
詳細は、以下のリソースを参照してください:
- Illustrating Reinforcement Learning from Human Feedback (RLHF)
- Contrastive Post-training Large Language Models on Data Curriculum
ステップ 6:LLM の評価と継続的な学習
特定のタスクに対してLLMを微調整した後は、その性能を評価し、継続的な学習と適応の戦略を考慮することが重要です。これにより、LLMが効果的で最新の情報を反映していることが保証されます。
LLM の評価
効果を評価し、改善のための領域を特定するためにパフォーマンスを評価します。LLMの評価の主な側面は以下の通りです:
- タスク固有の指標:タスクに適した指標を選択します。例えば、テキスト分類では、正解率、適合率、再現率、またはF1スコアなどの従来の評価指標を使用することがあります。言語生成の場合、パープレキシティやBLEUスコアなどの指標が一般的です。
- 人間の評価:専門家やクラウドソーシングのアノテーターによって生成されたコンテンツの品質やモデルの応答が現実のシナリオでどのように評価されるかを評価します。
- バイアスと公平性:特に実世界のアプリケーションで展開する場合、LLMのバイアスや公平性に関して評価します。モデルが異なる人口グループでどのように機能するかを分析し、任意の格差に対処します。
- 頑健性と敵対的なテスト:LLMの頑健性をテストするために、敵対的な攻撃や挑戦的な入力を行います。これにより、脆弱性が明らかになり、モデルのセキュリティが向上します。
継続的な学習と適応
LLMを新しいデータとタスクに更新し続けるために、以下の戦略を考慮してください:
- データの拡張:最新の情報の欠如によるパフォーマンスの低下を防ぐために、データストアを継続的に拡張します。
- 再学習:新しいデータでLLMを定期的に再学習し、進化するタスクに対して微調整します。最新のデータでの微調整により、モデルは最新の情報を反映し続けます。
- アクティブラーニング:モデルが不確かな状況や誤りを起こしそうなインスタンスを特定するために、アクティブラーニング技術を実装します。これらのインスタンスのアノテーションを収集し、モデルを改善します。
LLM(Language Level Model)のもう一つのよくある落とし穴は、幻覚です。幻覚を軽減するために、検索補完などの技術を試してみてください。
以下はいくつかの役立つ資源です:
ステップ7: LLMアプリケーションの構築と展開
特定のタスクに合わせてLLMを開発・微調整した後、LLMの能力を活用した有用な現実世界のソリューションを構築・展開してください。基本的には、LLMを使って実用的な現実世界の解決策を構築することです。 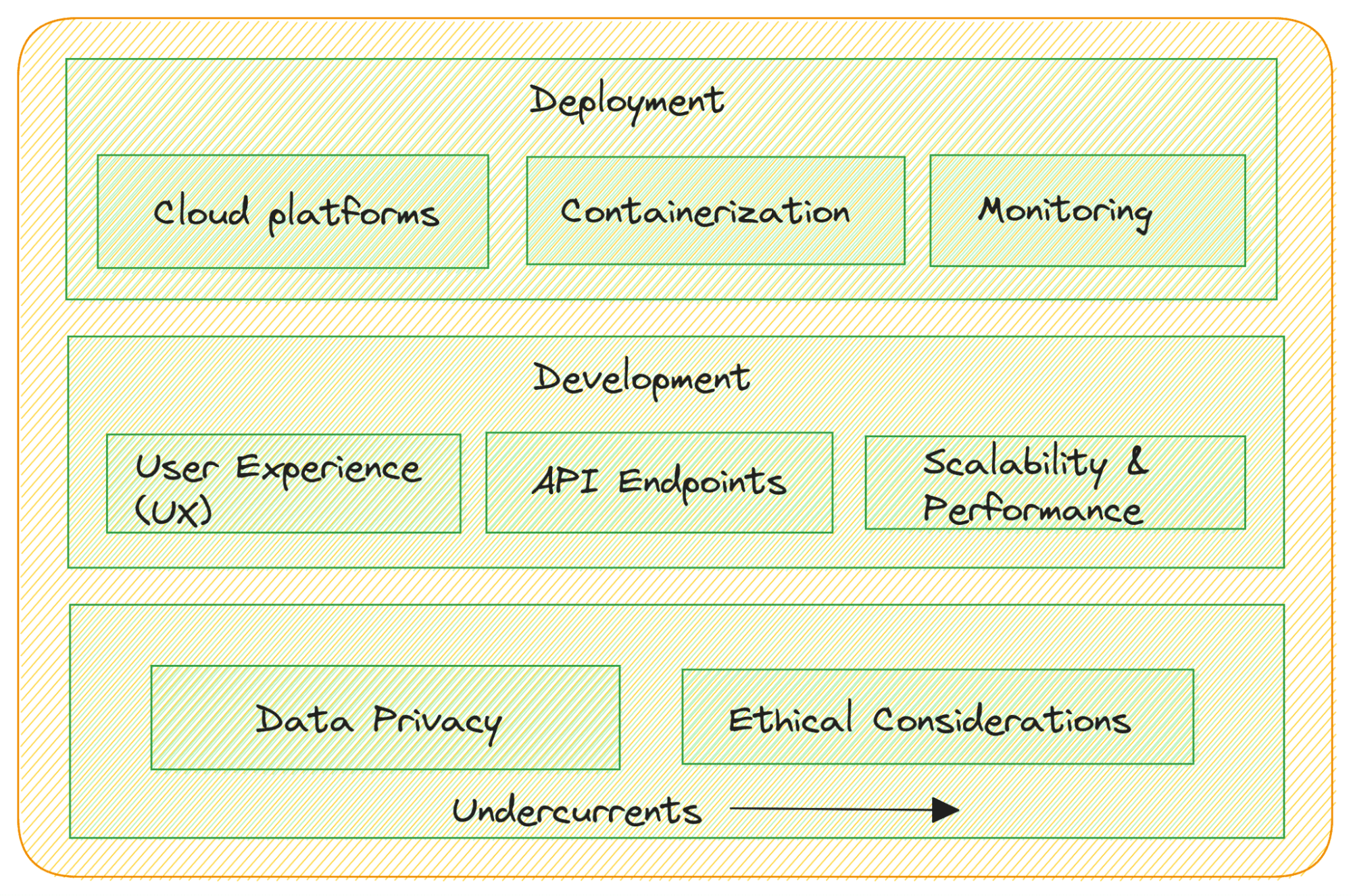
LLMアプリケーションの構築
以下の点に留意してください:
- タスク固有のアプリケーション開発:特定のユースケースに合わせたアプリケーションを開発します。ウェブベースのインターフェース、モバイルアプリ、チャットボット、または既存のソフトウェアシステムとの統合などが含まれる場合があります。
- ユーザーエクスペリエンス(UX)デザイン:LLMアプリケーションが直感的で使いやすいものになるよう、ユーザーセンタードデザインに重点を置きましょう。
- APIの統合:LLMが言語モデルのバックエンドとして機能する場合、RESTful APIやGraphQLエンドポイントを作成して、他のソフトウェアコンポーネントがモデルとシームレスにやり取りできるようにします。
- 拡張性とパフォーマンス:様々なトラフィックや需要に対応できるようにアプリケーションを設計します。パフォーマンスと拡張性に最適化し、スムーズなユーザーエクスペリエンスを確保しましょう。
LLMアプリケーションの展開
LLMアプリケーションを本番環境に展開する準備が整いました。以下のことに留意してください:
- クラウド展開:スケーラビリティと管理の容易さのために、AWS、Google Cloud、またはAzureなどのクラウドプラットフォームにLLMアプリケーションを展開することを検討してください。
- コンテナ化:DockerやKubernetesなどのコンテナ化技術を使用してアプリケーションをパッケージ化し、異なる環境でも一貫した展開を実現します。
- 監視:デプロイされたLLMアプリケーションのパフォーマンスを追跡し、リアルタイムで問題を検出・解決するための監視を実装します。
コンプライアンスと規制
データプライバシーや倫理的な考慮事項には次のような要素があります:
- データプライバシー:ユーザーデータや個人識別情報(PII)の取り扱いにおいてデータプライバシーの規制に準拠するようにしてください。
- 倫理的な考慮事項:バイアス、誤情報、有害コンテンツの生成を軽減するため、LLMアプリケーションを展開する際には倫理的なガイドラインに従ってください。
また、LlamaIndexやLangChainといったフレームワークを使用することで、エンドツーエンドのLLMアプリケーションの構築をサポートできます。以下はいくつかの役立つ資源です:
まとめ
大規模言語モデルの定義や人気の理由から技術的な側面について徐々に掘り下げ、注意深い計画、ユーザー中心のデザイン、堅牢なインフラストラクチャを重視しつつ、データプライバシーと倫理を最優先に考えたLLMアプリケーションの構築や展開について説明しました。
もっとも重要なのは、この分野の最新の動向について常に最新情報をキャッチアップし、プロジェクトを継続して構築することです。自然言語処理の経験がある場合、このガイドは基盤を築いた上でさらに進めるでしょう。もし経験がなくても心配ありません。私たちは自然言語処理のマスタリングのための7つのステップガイドでサポートします。楽しい学習を!
[Bala Priya C](https://twitter.com/balawc27) はインド出身の開発者であり技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点で働くことが好きです。彼女の関心と専門知識のある分野には、DevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、そしてコーヒーが好きです!現在は、チュートリアル、ガイド、意見記事などの執筆により、開発者コミュニティとの知識の共有と学習に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 印象的なパフォーマンス:TensorRT-LLMを使用したRTXで最大4倍高速化された大規模言語モデル(LLM) for Windows
- 「このAIニュースレターはあなたが必要とするもの全てです #69」
- このAI論文では、「MotionDirector」という人工知能アプローチを提案しています:ビデオの動きと外観をカスタマイズするための手法
- カフカイベントストリーミングAIと自動化
- LLama Indexを使用してRAGパイプラインを構築する
- 「私たちのLLMモデルを強化するための素晴らしいプロンプトエンジニアリング技術」
- 「MozillaがFirefoxに偽レビューチェッカーAIツールを導入」