Fast.AIディープラーニングコースからの7つの教訓
7 Lessons from the Fast.AI Deep Learning Course
最も人気のあるDLコースから学んだこと
最近、Fast.AIのPractical Deep Learningコースを修了しました。以前にも多くのMLコースを受講してきましたので、比較することができます。このコースは間違いなく実践的でインスピレーションを与えるものの一つです。そこで、主な学びを共有したいと思います。
コースについて
Fast.AIのコースは、Fast.AIの創設研究者であるジェレミー・ハワード氏が指導しています。彼はかつてKaggleのリーダーボードで1位になったこともありますので、彼の機械学習とディープラーニングにおける専門知識は信頼できるものです。
このコースでは、ディープラーニングとニューラルネットワークの基礎をカバーし、決定木アルゴリズムも説明しています。現在のバージョンは2022年からですので、以前のTDSのレビューとは内容が変わっていると思われます。
このコースは、ある程度のプログラミング経験を持つ人々を対象としています。ほとんどの場合、数式の代わりにコードの例が使用されます。私自身、数学の修士号を持っているにも関わらず、コードを書き続けてきた後だとコードの理解が容易です。
- Google AIは、TPUを使用して流体の流れを計算するための新しいTensorFlowシミュレーションフレームワークを導入しました
- アデプトAIラボは、Persimmon-8Bという強力なフルパーミッシブライセンスの言語モデルをオープンソース化しました
- 「Falcon 180Bをご紹介します:1800億のパラメータを持つ、公開されている最大の言語モデル」
このコースのもう一つの素晴らしい特徴は、トップダウンのアプローチです。まず、動作するMLモデルから始めます。たとえば、私はコースの2週目に最初のDLパワードアプリを作りました。それは私のお気に入りの犬の品種を検出する画像分類器です。その後の数週間で、より深く理解し、すべてがどのように機能するかを理解します。
それでは、このコースからの主な学びに移りましょう。
レッスン1:ディープラーニングを理解するために知っておくべき数学
まずは簡単に始めましょう。以下の学びはより重要なものになります。
ディープラーニングは数学のいくつかの概念に基づいていますが、これらは1日で学べるものですので、話しておくことが重要だと考えています。
ニューラルネットワークは線形関数と活性化関数の組み合わせです。以下は線形関数です。
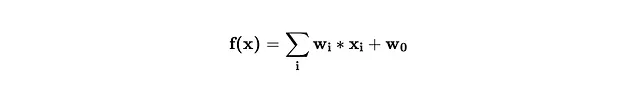
線形関数の組み合わせも線形ですので、非線形性を追加する必要がある活性化関数が必要です。
最も一般的な活性化関数はReLU(Rectified Linear Unit)です。恐ろしく聞こえるかもしれませんが、実際には次のような関数です。
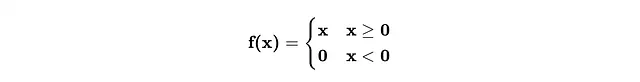
これは信号が乗り越える必要のあるバリアと考えることができます。信号がしきい値(この場合は0)以下の場合、その情報はニューラルネットワークの次の層に渡されません。
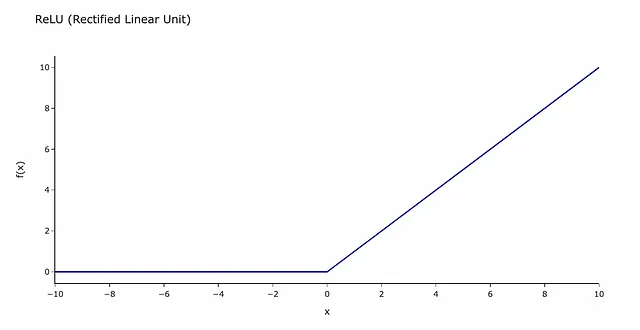
その他使用される数学的な概念:
- SGD(確率的勾配降下法) — 勾配の計算に基づく最適化手法です。その動作原理を理解するために記事を読むことをおすすめします。
- 行列の積 — 計算をバッチで高速に行うための方法です。それについても優れた記事があります。
詳細に学びたい場合は、Fast.AIのコースのニューラルネットワークの基礎のレッスンを見てください。
レッスン2:データのクリーニング方法
私たちはデータのクリーニングから分析を始めることに慣れています。何度も聞いたことのある「ゴミを入れるとゴミが出る」という言葉もあります。驚くことに、モデルを最初に適合させ、それを使用してデータをクリーニングする方が効果的な場合があります。
単純なモデルをトレーニングし、最も損失の大きなケースを見ることで潜在的な問題を見つけることができます。以前の記事では、このアプローチが不正ラベルのついた画像を見つけるのに役立ちました。
1時間以内にあなたの最初のディープラーニングアプリを作成しましょう
HuggingFace SpacesとGradioを使用したイメージ分類モデルのデプロイ
towardsdatascience.com
レッスン#3:コンピュータビジョンモデルの選び方
現在は、多くの事前学習済みモデルが存在します。例えば、PyTorch Image Models(timm)には1,242のモデルがあります。
import timmpretrained_models = timm.list_models(pretrained=True)print(len(pretrained_models))print(pretrained_models[:5])1242['bat_resnext26ts.ch_in1k', 'beit_base_patch16_224.in22k_ft_in22k', 'beit_base_patch16_224.in22k_ft_in22k_in1k', 'beit_base_patch16_384.in22k_ft_in22k_in1k', 'beit_large_patch16_224.in22k_ft_in22k']初心者の場合、多くの選択肢に悩むことがよくあります。幸いなことに、ディープラーニングアーキテクチャを選ぶための便利なツールがあります。
このグラフは、推論時間(1枚の画像の処理にかかる時間)とImagenetの精度の関係を示しています。

予想通り、速度と精度のトレードオフがありますので、どちらが重要かを決める必要があります。それはあなたのタスクに大きく依存します。モデルをより速くする必要がありますか、それともより精度を重視する必要がありますか?
小さなモデルから始めて反復する方が良いです。原則として、最初のモデルは最初の日に作成することです。したがって、異なるデータ拡張手法や外部データセットを試すことができるように、Resnet18やResnet34などのシンプルなモデルを使用することができます。シンプルなモデルであれば、反復は速く行えます。最良のバージョンを見つけたら、より遅いモデルアーキテクチャに進むことができます。
Jeremy Howardのアドバイス: 「複雑なアーキテクチャを試すのは非常に最後のことです」。
レッスン#4:Kaggleで大規模なモデルをトレーニングする方法
多くの初心者がMLにKaggleのノートブックを使用しています。KaggleのGPUはメモリが制限されているため、特に大きなモデルを使用する場合にはメモリ不足になることがあります。
この問題を解決するための便利なトリックがあります。それがGradient Accumulationです。Gradient Accumulationでは、各バッチごとに重みを更新せずに、Kバッチの勾配を合計します。その後、この累積勾配を使用してモデルの重みをK * バッチサイズのトータルバッチで更新するため、各イテレーションごとにK倍小さいバッチサイズが得られます。
Gradient Accumulationは、バッチ正規化がモデルアーキテクチャで使用されていない限り、数学的にはまったく同じです。例えば、convnextはバッチ正規化を使用していないため、違いはありません。
このようなアプローチでは、非常に少ないメモリを使用しています。つまり、巨大なGPUを購入する必要はありません-モデルをラップトップに収めることができます。
Kaggleで完全な例を見つけることができます。
レッスン#5:どのMLアルゴリズムを使用するか
現在は、さまざまなML技術があります。例えば、scikit-learnのドキュメントには少なくとも数十の監視学習アプローチがあります。
Jeremy Howardは、いくつかの重要なテクニックに焦点を当てることを提案しました:
- 構造化データを持っている場合は、決定木のアンサンブル(ランダムフォレストや勾配ブースティングアルゴリズム)から始めるべきです。
- 自然言語テキスト、音声、ビデオ、画像などの非構造化データの最適な解決策は、マルチレイヤーニューラルネットワークです。
ニューラルネットワークは構造化データにも適用できますが、決定木の方が使いやすいことがよくあります:
- 決定木のアンサンブルはトレーニングがはるかに高速です。
- 調整するパラメータが少ないです。
- トレーニングに特別なGPUは必要ありません。
- さらに、決定木は解釈しやすく、各オブジェクトごとにどのような結果が得られるのか、最も強力な予測変数はどれで、どれを安全に無視できるかを理解するのが容易です。
決定木のアンサンブルを比較すると、ランダムフォレストは使いやすく(過学習することがほとんど不可能です)、しかし勾配ブースティングの方が通常は少し良い結果を出します。
レッスン#6:便利なPython関数
私はPythonとPandasをほぼ10年間使ってきましたが、いくつかの役立つPandasライフハックも見つけました。
有名なタイタニックのデータセットは、Pandasのパワーを示すために使用されました。それを見てみましょう。
最初の例では、列を文字列に変換し、最初の文字を取得し、辞書を使用して変換する方法を示しています。辞書に値が記載されていない場合はNaNが返されます。
# 私の通常のアプローチdecks_dict = {'A': 'ABC', 'B': 'ABC', 'C': 'ABC', 'D': 'DE', 'E': 'DE', 'F': 'FG', 'G': 'FG'}df['Deck'] = df.Cabin.map( lambda x: decks_dict.get(str(x)[0]))# コースからのバージョンdf['Deck'] = df.Cabin.str[0].map(dict(A="ABC", B="ABC", C="ABC", D="DE", E="DE", F="FG", G="FG"))次の例では、transform関数を使用して頻度を計算する方法を示しています。このバージョンは、通常使用するマージに比べてより簡潔です。
# 私の通常のアプローチdf = df.merge( df.groupby('Ticket', as_index = False).PassengerId.count()\ .rename(columns = {'PassengerId': 'TicketFreq'}))# コースからのバージョンdf['TicketFreq'] = df.groupby('Ticket')['Ticket'].transform('count')最後の例は、タイトルを解析する最も複雑な例です。
# 私の通常のアプローチdf['Title'] = df.Name.map(lambda x: x.split(', ')[1].split('.')[0])df['Title'] = df.Title.map( lambda x: x if x in ('Mr', 'Miss', 'Mrs', 'Master') else None)# コースからのバージョン df['Title'] = df.Name.str.split(', ', expand=True)[1]\ .str.split('.', expand=True)[0]df['Title'] = df.Title.map(dict(Mr="Mr",Miss="Miss",Mrs="Mrs",Master="Master"))これがどのように動作するかを理解するために、最初の部分dfを見る価値があります。コードdf.Name.str.split(‘、’、expand = True)を実行すると、名前が2つの列にわたってコンマで分割されたデータフレームが表示されます。

次に、列1を選択し、ドットに基づいて同様の分割を行います。2行目は、Mr、Mrs、Miss、Masterと等しくないすべての場合にNaNに置き換えます。
率直に言って、私は最後のケースでは通常のアプローチを引き続き使用する方が良いと思います。なぜなら、私にとっては理解しやすいからです。
レッスン#7:MLのトリック
このコースでは、多くのトリックや役立つテクニックやツールが言及されています。私が役立つと思ったものを以下に示します。
マルチターゲットモデル
驚くべきことに、ニューラルネットワークに別のターゲットを追加すると、モデルの品質を向上させることができます。
Jeremyは、パディディーズクラシフィケーションコンテストのマルチターゲットモデルの例を示しました。このコンテストの目標は、写真による米の病気を予測することです。私たちは病気だけでなく、米の品種も予測することができます。これはモデルが有益な特徴を学習するのに役立つかもしれません。米の品種を予測するために役立つ特徴は、病気の検出にも役立つかもしれません。
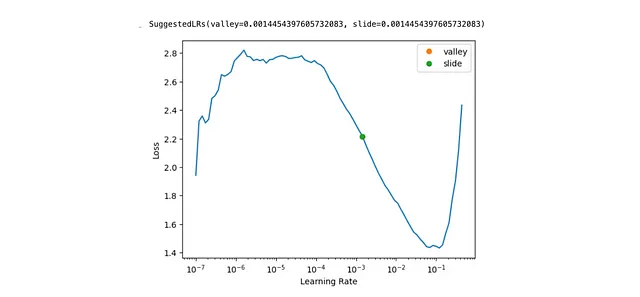
最適な学習率の見つけ方
学習率はSGD(確率的勾配降下法)の各イテレーションでのステップサイズを定義します。学習率が小さすぎると、モデルの適合が非常に遅くなります。逆に、学習率が高すぎると、モデルが最適値に収束しない可能性があります。そのため、正しい学習率を選ぶことは非常に重要です。
Fast.AIは、1行のコードでそれを行うためのツールを提供しています learn.lr_find(suggest_funcs=(valley, slide)) 。
テスト時のデータ拡張
データ拡張は、画像に対する変更(例:コントラストの改善、回転、トリミングなど)のことを指します。データ拡張は、トレーニング中に各エポックごとにわずかに異なる画像を提供するためによく使用されます。しかし、データ拡張は推論の段階でも使用することができます。この技術はテスト時のデータ拡張と呼ばれます。

この方法は非常にシンプルです。データ拡張を使用して各画像の複数のバージョンを生成し、それぞれのバージョンに対して予測を行います。その後、最大値または平均値を使用して集約結果を計算します。このアイデアはバギングと似ています。
日付の豊か化
データセットに日付が含まれている場合、データセットからより多くの情報を取得することができます。例えば、単に 2023–09–01 ではなく、月、曜日、年などの別々の特徴を見ることができます。
Fast.AIには、それを実装する必要がないようにするためのadd_datepartという関数があります。
未解決の質問: なぜシグモイド関数を使用するのですか?
このコースでは、徹底的に説明されなかった理論的な質問が1つだけありました。他の多くのMLコースと同様に、線形モデルの出力を確率に変換するためにシグモイド関数を使用する理由についての説明はありません。幸いなことに、すべての答えが記載されている長い読み物があります。
まとめると、Fast.AIのコースには、データサイエンスの経験がある場合でも考える材料がたくさん含まれています。そのため、ぜひ聴くことをお勧めします。
この記事をお読みいただき、ありがとうございました。お役に立てたことを願っています。ご質問やコメントがある場合は、コメントセクションにお書きください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






