次回のデータプロジェクトで興味深いデータセットを取得する5つの方法(Kaggle以外)
5 ways to acquire interesting datasets for the next data project (other than Kaggle)
KaggleやFiveThirtyEightに飽きた方へ。高品質でユニークなデータセットを入手するための代替戦略を紹介します
優れたデータサイエンスのプロジェクトの鍵は、優れたデータセットですが、優れたデータを見つけることは簡単ではありません。
私は1年以上前にデータサイエンスの修士号を取得していた時を覚えています。そのコース中、プロジェクトアイデアを考えることは簡単だったのですが、最も苦労したのは良いデータセットを見つけることでした。私は何時間もインターネットを検索し、ジューシーなデータソースを見つけようとして髪を引き抜いていましたが、何も見つかりませんでした。
それ以来、私はアプローチを大幅に改善し、この記事では、私がデータセットを見つけるために使用する5つの戦略を共有したいと思います。KaggleやFiveThirtyEightのような標準的なソースに飽きた場合、これらの戦略を使用することで、特定のユースケースに合わせたユニークなデータを取得できます。
1. 自分自身でデータを作成する
そうです、信じられないかもしれませんが、これは実際に正当な戦略です。それにはさえ、ファンシーな技術用語があります(「合成データ生成」)。
新しいアイデアを試してみたり、非常に具体的なデータ要件がある場合、合成データを作成することは、オリジナルでターゲットに合わせたデータセットを取得するための素晴らしい方法です。
たとえば、顧客が会社を離れる可能性を予測できるモデルである離反予測モデルを構築しようとしているとします。離反は多くの企業が直面する一般的な「運用上の問題」であり、このような問題に取り組むことは、以前に私が主張したように、商業的に関連する問題を解決するためにMLを使用できることを採用担当者に示す素晴らしい方法です。
ポートフォリオを際立たせるユニークなデータサイエンスのプロジェクトアイデアを見つける方法
タイタニック号やMNISTを忘れ、スキルを構築し、人々から際立つユニークなプロジェクトを選びましょう
towardsdatascience.com
ただし、「離反データセット」とオンラインで検索すると、(執筆時点で)一般に公開されている主要なデータセットは2つしかないことがわかります。銀行顧客離反データセットと電気通信離反データセットです。これらのデータセットは素晴らしい出発点ですが、他の産業での離反のモデリングに必要な種類のデータを反映していないかもしれません。
代わりに、よりターゲットに合わせた合成データを作成してみることができます。
これが信じられないほど良い方法のように聞こえる場合は、簡単なプロンプトによって作成したこの例のデータセットをご覧ください。
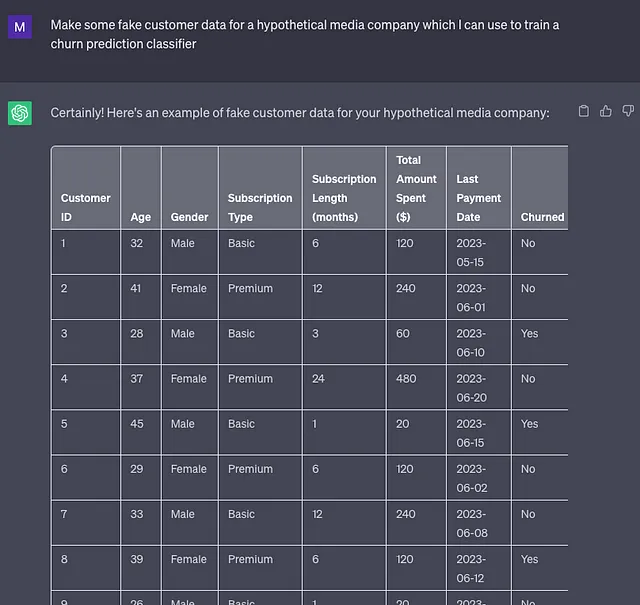
もちろん、ChatGPTはデータセットを作成する速度とサイズに制限があるため、このテクニックを拡大する場合は、Pythonライブラリfakerまたはscikit-learnのsklearn.datasets.make_classificationおよびsklearn.datasets.make_regression関数を使用することをお勧めします。これらのツールは、瞬時に巨大なデータセットをプログラムで生成するのに最適であり、完璧な概念実証モデルを構築するのに最適です。
実際には、私はデータセット全体を生成するために合成データ作成技術を使用する必要があることはほとんどありませんでした(後で説明するように、これを行う場合は注意を払うことが賢明です)。代わりに、これは私がモデルの弱点をテストし、より堅牢なバージョンを構築するために、敵対的な例を生成したり、データセットにノイズを加えるために使用する非常に便利なテクニックだと思います。しかし、このテクニックをどのように使用するにせよ、あなたの使い捨て可能なツールとして非常に有用です。
会社にデータを丁寧にお願いする
合成データを作成することは、探しているデータのタイプが見つからない場合の良い回避策ですが、明らかな問題は、データが実際の人口の良い表現である保証がないことです。
データが現実的であることを保証したい場合は、やはり実際にリアルなデータを探すことが最良の方法です。
その方法の1つは、そのようなデータを保持する可能性のある企業にアプローチして、あなたと共有することに興味があるかどうか尋ねることです。あきらかなことを言うリスクがありますが、高度に機密性が高いデータを提供する企業はないでしょう。商業的または非倫理的な目的で使用する場合も同様です。それはただの愚かさになるでしょう。
ただし、研究(例えば、大学のプロジェクトのための)にデータを使用する意図がある場合、共同研究契約の文脈で提供することに開放的である場合があります。
これはどういう意味ですか? 実際にはかなりシンプルです。それは、彼らがあなたに(匿名化/データ保護された)データを提供し、あなたが彼らの利益になるような研究を行うことです。たとえば、離反予測の研究に興味がある場合は、さまざまな離反予測技術を比較する提案をまとめて、いくつかの企業と提案を共有し、一緒に働く可能性があるかどうか尋ねることができます。広くネットワークを張り、粘り強く取り組めば、研究の結果を共有することで彼らが研究から利益を得ることができる企業が見つかる可能性が高いです。
あまりにも良いと思われる場合、私は修士課程中にまさにこれを行ったことを知っているでしょう。私は、彼らのデータを研究に使用する方法の提案を伴ういくつかの企業にアプローチし、データを他の目的には使用しないことを確認するためにいくつかの書類に署名し、現実的なデータを使用して本当に楽しいプロジェクトを実施しました。それは本当にできることです。
私がこの戦略で特に好きなもう1つのことは、それがデータサイエンティストの日常生活で必要な非常に幅広いスキルセットを行使し、開発する方法を提供することです。あなたはよくコミュニケーションをし、商業的な意識を示し、利害関係者の期待を管理するプロにならなければならないため、これらはすべてデータサイエンティストにとって必須のスキルです。
ジャーナル記事にコードを保存するリポジトリを見る
Kaggleなどのプラットフォームに公開されていない多くの学術研究で使用されるデータセットは、他の研究者が使用できるようになっています。
これらのデータセットを見つける最良の方法の1つは、学術論文に関連するリポジトリを見ることです。なぜなら、多くのジャーナルでは、貢献者に基礎となるデータを公開することを求めているからです。たとえば、私が修士課程中に使用した2つのデータソース(Fragile FamiliesデータセットとHate Speech Dataウェブサイト)は、Kaggleでは利用できませんでした。それらは学術論文と関連するコードリポジトリを通じて見つけました。
これらのリポジトリをどのように見つけることができますか? 実際、非常に簡単です。私はpaperswithcode.comを開いて、興味のある分野の論文を検索し、利用可能なデータセットを見つけるまで見ます。私の経験では、これはKaggleで大衆によって行き詰まっていないデータセットを見つけるための本当に素晴らしい方法です。
BigQueryパブリックデータセット
正直に言って、BigQueryパブリックデータセットを利用しない人々がもっといる理由がわかりません。Google検索トレンドからロンドン自転車の貸し出し、カンナビスのゲノムシークエンシングまで、あらゆるものをカバーする何百ものデータセットがあります。
このソースの特に気に入っていることの1つは、これらのデータセットの多くが非常に商業的に関連していることです。フラワー分類や数字予測のようなニッチな学術的トピックとはおさらばできます。BigQueryには、広告のパフォーマンス、ウェブサイト訪問数、経済予測など、実際のビジネス問題に関するデータセットがあります。
これらのデータセットにはSQLスキルが必要なため、多くの人が避けています。しかし、SQLを知らずにPythonやRなどの言語しか知らなくても、基本的なSQLを1〜2時間学んでからこれらのデータセットにクエリを投げることをお勧めします。すぐに始めることができ、これらは本当に高価値のデータ資産の宝庫です。
BigQuery Public Datasetsのデータセットを使用するには、完全に無料のアカウントを登録し、こちらの指示に従ってサンドボックスプロジェクトを作成することができます。クレジットカードの詳細などを入力する必要はありません。名前、メールアドレス、プロジェクトに関する少しの情報を入力するだけで、すぐに利用できます。後でより多くのコンピューティングパワーが必要になった場合は、プロジェクトを有料にアップグレードしてGCPのコンピュートリソースや高度なBigQueryの機能にアクセスすることができますが、私は個人的にこれを必要としたことはありませんでした。サンドボックスは十分でした。
データセット検索エンジンを試してみる
最後のヒントは、データセット検索エンジンを試してみることです。これらは、わずか数年前に登場した非常に便利なツールであり、簡単に利用可能なものをすばやく見ることができます。私のお気に入りは次の3つです。
- Harvard Dataverse
- Google Dataset Search
- Papers with Code
これらのツールを使用して検索すると、データセットに関するメタデータが提供され、使用頻度や公開日に応じてランク付けすることができるため、一般的な検索エンジンを使用するよりも効果的な戦略になることがあります。私にとっては、かなり巧妙なアプローチです。
読んでいただきありがとうございます!これらの5つの戦略が役立つことを願っています。何かフィードバックや質問がある場合は、お気軽にお問い合わせください 🙂
もう1つ — あなたは私の1%になれますか?
VoAGIの読者のうち、1%未満の人が私の「フォロー」ボタンをクリックしています。VoAGI、Twitter、LinkedInでどこでもクリックしていただけると、本当に嬉しいです。
私のストーリー(およびVoAGI.comの残り)に無制限アクセスしたい場合は、紹介リンクから1か月5ドルでサインアップすることができます。一般的なサインアップページからサインアップする場合と比較して、追加費用はかかりません。少しの手数料が入るため、私の執筆をサポートしていただけます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
