時系列のLSTMモデルの5つの実践的な応用とコード
5 practical applications and code for LSTM models in time series
異なる複数の時系列コンテキストで高度なニューラルネットワークモデルを実装する方法
私が2022年1月に「Exploring the LSTM Neural Network Model for Time Series」を執筆した際、私の目標は、私自身の仕事とプロジェクトを容易にするために開発した時系列ライブラリであるscalecastを使用して、高度なニューラルネットワークをPythonで実装する方法を紹介することでした。私はそれが何万回も閲覧され、発行後1年以上にわたって「lstm forecasting python」と検索した際にGoogleの最初のヒットとして表示されることは思ってもいませんでした(今日確認した時点でも2番目でした)。
私はその記事にあまり注目していませんでしたし、今でもあまり良くないと思っています。それはLSTMモデルを実装する最善の方法に関するガイドではなく、むしろ時系列予測のためのユーティリティの単純な探求でした。デフォルトのパラメータでモデルを実行した場合に何が起こるか、このようにパラメータを調整した場合に何が起こるか、他のモデルに比べてどのようなデータセットで簡単に負けるかなど、そういった質問に答えようとしました。しかし、その記事のコードをそのままコピーしたブログ記事やKaggleのノートブック、そしてUdemyのコースまで現れるのを見ると、多くの人々が前者の価値を持つものとして記事を受け取ったことは明らかです。私は今、自分の意図を明確に伝えていなかったことを理解しています。
今日は、その記事を拡張するために、LSTMニューラルネットワークモデルをどのように適用するか、少なくとも私がどのように適用するか、時系列予測問題の価値を十分に実現する方法を紹介したいと思います。最初の記事を書いた後、scalecastライブラリにはLSTMモデルをよりシームレスに使用するための多くの新しい革新的な機能が追加されました。ここでは、私のお気に入りのいくつかを探求します。ライブラリを使用して次の5つのLSTMアプリケーションが素晴らしく機能すると考えています:単変量予測、多変量予測、確率予測、動的確率予測、および転移学習。
開始する前に、ターミナルまたはコマンドラインで次のコマンドを実行してください:
- XGBoost ディープラーニングがグラディエントブースティングと決定木を置き換える方法 – パート2:トレーニング
- GoogleのPaLM 2:言語モデルの革命化
- LLMの出力解析:関数呼び出し対言語チェーン
pip install --upgrade scalecastこの記事のために開発された完全なノートブックはこちらにあります。
最後の注意:各例では、「RNN」と「LSTM」の用語を同等に使用することがあります。また、LSTMの予測のグラフにRNNが表示される場合もあります。長短期記憶(LSTM)ニューラルネットワークは、追加のメモリ関連パラメータを持つ再帰型ニューラルネットワーク(RNN)の一種です。scalecastでは、rnnモデルクラスを使用して、tensorflowから移植されたモデルに単純なRNNとLSTMセルの両方を適合させることができます。
1. 単変量予測
LSTMモデルを使用する最も一般的で明らかな方法は、単純な単変量予測問題を行う場合です。このモデルは、トレンド、季節性、および短期のダイナミクスを効果的に学習するための多くのパラメータを適合させるはずですが、私はそれがステーショナリデータ(トレンドや季節性を示さないデータ)の場合にはるかに優れたパフォーマンスを発揮することを見つけました。したがって、Kaggleでオープンデータベースライセンスで利用可能な航空旅客データセットを使用して、データのトレンドを取り除き、季節性を除去するだけで、正確で信頼性のある予測を簡単に作成できます:
transformer = Transformer( transformers = [ ('DetrendTransform',{'poly_order':2}), 'DeseasonTransform', ],)また、結果を元のレベルに戻すことも忘れないようにしましょう:
reverter = Reverter( reverters = [ 'DeseasonRevert', 'DetrendRevert', ], base_transformer = transformer,)これで、ネットワークのパラメータを指定できます。この例では、18のラグ、1つのレイヤー、tanh活性化関数、および200のエポックを使用します。自分自身の良いパラメータを探索してください!
def forecaster(f): f.set_estimator('rnn') f.manual_forecast( lags = 18, layers_struct = [ ('LSTM',{'units':36,'activation':'tanh'}), ], epochs=200, call_me = 'lstm', )すべてをパイプラインに統合し、モデルを実行し、結果を視覚的に表示します:
pipeline = Pipeline( steps = [ ('Transform',transformer), ('Forecast',forecaster), ('Revert',reverter), ])f = pipeline.fit_predict(f)f.plot()plt.show()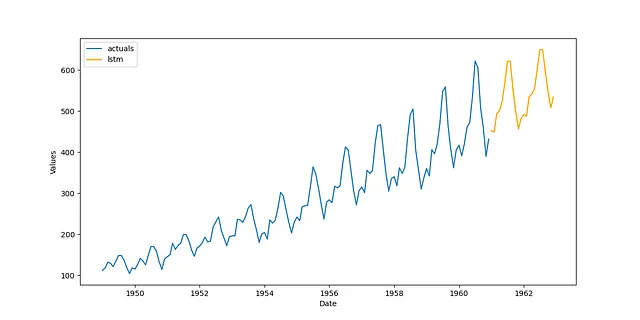
十分であり、他の記事で示したものよりもはるかに優れています。このアプリケーションを拡張するために、異なるラグオーダーを使用してみたり、モデルにフーリエ項の季節性を追加したり、より良い系列変換を見つけたり、モデルのハイパーパラメータを交差検証で調整したりすることができます。これについての一部は、後続のセクションでデモンストレーションされます。
2. 多変量予測
移動すると予測される2つの系列があるとしましょう。予測の際に、両方の系列を考慮に入れるLSTMモデルを作成して、モデルの全体的な精度を向上させることを期待することができます。これが、もちろん、多変量予測です。
この例では、オープンデータベースライセンスでKaggleで利用可能なAvocadosデータセットを使用します。これは、アメリカ合衆国のさまざまな地域で週単位でアボカドの価格と販売数量を測定しています。経済理論からは、価格と需要は密接に関連していることがわかっており、価格を先行指標として使用することで、単変量の文脈での歴史的な需要だけではなく、アボカドの販売数量をより正確に予測することができるかもしれません。
まず、各系列を変換します。以下のコードを実行して、「最適な」変換(つまり、アウトオブサンプルでスコアリングされた変換)を検索することができます:
data = pd.read_csv('avocado.csv')# demandvol = data.groupby('Date')['Total Volume'].sum()# priceprice = data.groupby('Date')['AveragePrice'].sum()fvol = Forecaster( y = vol, current_dates = vol.index, test_length = 13, validation_length = 13, future_dates = 13, metrics = ['rmse','r2'],)transformer, reverter = find_optimal_transformation( fvol, set_aside_test_set=True, # prevents leakage so we can benchmark the resulting models fairly return_train_only = True, # prevents leakage so we can benchmark the resulting models fairly verbose=True, detrend_kwargs=[ {'loess':True}, {'poly_order':1}, {'ln_trend':True}, ], m = 52, # what makes one seasonal cycle? test_length = 4,)このプロセスからの推奨される変換は、季節調整(52期間で1シーズンを作ると仮定)および頑健なスケール(外れ値に対して頑健なスケーリング)です。その変換を系列にフィットさせ、単変量LSTMモデルを呼び出してマルチバリエートモデルと比較します。今回は、アクティベーション関数、レイヤーサイズ、ドロップアウト値の可能なグリッドを生成することで、ハイパーパラメータのチューニングプロセスを使用します:
rnn_grid = gen_rnn_grid( layer_tries = 10, min_layer_size = 3, max_layer_size = 5, units_pool = [100], epochs = [25,50], dropout_pool = [0,0.05], callbacks=EarlyStopping( monitor='val_loss', patience=3, ), random_seed = 20,) # creates a grid of hyperparameter values to tune the LSTM modelこの関数は、管理可能なグリッドをオブジェクトに取り込む良い方法を提供するだけでなく、十分なランダム性も持っているため、選択するパラメータの良い候補を持つことができます。次に、単変量モデルをフィットします:
fvol.add_ar_terms(13) # the model will use 13 series lagsfvol.set_estimator('rnn')fvol.ingest_grid(rnn_grid)fvol.tune() # uses a 13-period validation setfvol.auto_forecast(call_me='lstm_univariate')これを多変量の文脈に拡張するには、価格時系列も他の系列と同じ変換セットで変換します。その後、Forecasterオブジェクトに13の価格ラグを取り込み、新しいLSTMモデルをフィットします:
fprice = Forecaster( y = price, current_dates = price.index, future_dates = 13,)fprice = transformer.fit_transform(fprice)fvol.add_series(fprice.y,called='price')fvol.add_lagged_terms('price',lags=13,drop=True)fvol.ingest_grid(rnn_grid)fvol.tune()fvol.auto_forecast(call_me='lstm_multivariate')また、ナイーブモデルのベンチマークを行い、元のシリーズレベルで結果をプロットすることもできます。さらに、テストセットの外部サンプルと共に結果をプロットします:
# ベンチマーク用のナイーブ予測fvol.set_estimator('naive')fvol.manual_forecast()fvol = reverter.fit_transform(fvol)fvol.plot_test_set(order_by='TestSetRMSE')plt.show()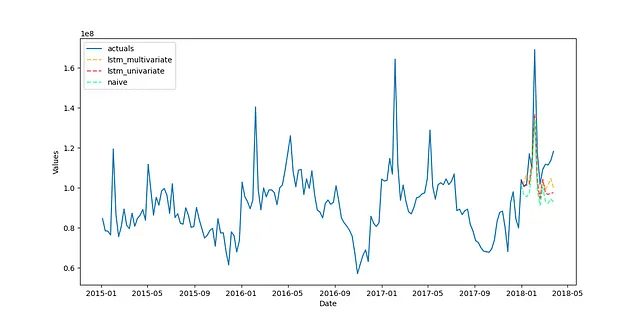
3つのモデルが視覚的にまとまっていることから、この特定のシリーズでの正確さのほとんどは、適用された変換によるものです。そのため、ナイーブモデルがLSTMモデルの両方と比較可能になったのです。それにもかかわらず、LSTMモデルは改善されており、多変量モデルのスコアとR-squaredは38.37%であり、単変量モデルは26.35%です。これは、ベースラインの-6.46%と比較しています。
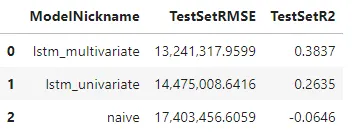
このシリーズでLSTMモデルがより良いパフォーマンスを発揮できなかった要因の1つは、その長さが短いためです。169の観測値しかないため、モデルがパターンを十分に学習するための十分な履歴ではないかもしれません。しかし、ナイーブまたは単純なモデルよりも改善があれば、成功と考えることができます。
3. 確率予測
確率予測とは、モデルがポイント予測だけでなく、予測がどれくらい外れる可能性があるかの推定値を提供する能力を指します。確率予測は、信頼区間を用いた予測に似ており、長い間存在している概念です。確率予測を生成するための新しく急速に普及している方法は、モデルに適用するための適正性確信区間を使用し、実際の将来のポイントの推定のばらつきを決定するためのキャリブレーションセットを使用することです。このアプローチは、モデルが入力または残差の分布についてどのような仮定を行っているかに関係なく、任意の機械学習モデルに適用することができます。また、MLプラクティショナーに非常に有用な特定のカバレッジ保証も提供します。LSTMモデルに適用して確率予測を生成するために、適正性確信区間を適用することができます。
この例では、FREDという経済時系列のオープンソースデータベースで利用可能な月次住宅開始データセットを使用します。1959年1月から2022年12月までのデータ(768の観測値)を使用します。まず、各変換の試行ごとにスコアリングするために、10エポックを持つLSTMモデルを使用して、最適な変換セットを再度検索します:
transformer, reverter = find_optimal_transformation( f, estimator = 'lstm', epochs = 10, set_aside_test_set=True, # リークを防ぐためにテストセットを取り除く return_train_only = True, # リークを防ぐためにトレーニングセットのみを返す verbose=True, m = 52, # 1つの季節の周期 test_length = 24, num_test_sets = 3, space_between_sets = 12, detrend_kwargs=[ {'loess':True}, {'poly_order':1}, {'ln_trend':True}, ],)ハイパーパラメータグリッドを再びランダムに生成しますが、今度はその検索空間を非常に大きくすることができます。後でモデルを適合させるときに手動で10回に制限します。これにより、パラメータを合理的な時間内でクロスバリデーションできます:
rnn_grid = gen_rnn_grid( layer_tries = 100, min_layer_size = 1, max_layer_size = 5, units_pool = [100], epochs = [100], dropout_pool = [0,0.05], validation_split=.2, callbacks=EarlyStopping( monitor='val_loss', patience=3, ), random_seed = 20,) # 本当に大きなグリッドを作成し、手動で制限次に、パイプラインを構築して適合させることができます:
def forecaster(f,grid): f.auto_Xvar_select( try_trend=False, try_seasonalities=False, max_ar=100 ) f.set_estimator('rnn') f.ingest_grid(grid) f.limit_grid_size(10) # 大きなグリッドを10にランダムに削減 f.cross_validate(k=3,test_length=24) # 3つの交差検証 f.auto_forecast()pipeline = Pipeline( steps = [ ('Transform',transformer), ('Forecast',forecaster), ('Revert',reverter), ])f = pipeline.fit_predict(f,grid=rnn_grid)十分なサイズのテストセットをForecasterオブジェクトに設定したため、結果は各ポイント推定値に対して90%の確率分布を自動的に提供します:
f.plot(ci=True)plt.show()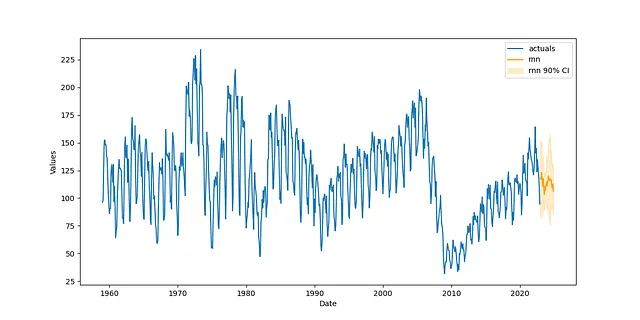
4. 動的確率予測
上記の例では、各予測値に対して上限と下限が等しく、他の予測値にも同じくらい離れている静的な確率予測が提供されます。将来予測を行う際には、予測が遠く離れるほど、エラーが広がると直感的に理解されますが、これは静的な区間では捉えられないニュアンスです。バックテストを使用して、LSTMモデルを使用してより動的な確率予測を実現する方法があります。
バックテストは、モデルを反復的にフィットし、異なる予測期間で予測し、各反復でそのパフォーマンスをテストするプロセスです。最後の例で指定されたパイプラインを10回バックテストします。90%の信頼区間を構築するためには、少なくとも10回のバックテスト反復が必要です:
backtest_results = backtest_for_resid_matrix( f, pipeline=pipeline, alpha = .1, jump_back = 12, params = f.best_params,)backtest_resid_matrix = get_backtest_resid_matrix(backtest_results)各反復で残差の絶対値を視覚的に分析することができます:
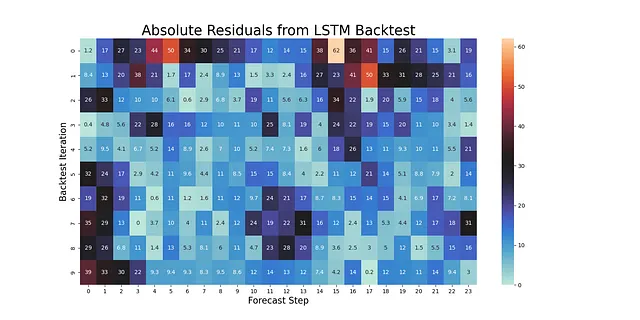
この特定の例で興味深いのは、最大のエラーが通常予測の最後のステップにはなく、実際にはステップ14〜17であることです。これは奇妙な季節パターンを持つ系列で起こることがあります。外れ値の存在もこのパターンに影響を与える可能性があります。いずれにせよ、これらの結果を使用して、静的な信頼区間を各ステップに沿って適用する動的な区間に置き換えることができます:
overwrite_forecast_intervals( f, backtest_resid_matrix=backtest_resid_matrix, alpha=.1, # 90%の区間)f.plot(ci=True)plt.show()5. 転移学習
転移学習は、モデルを適合させたコンテキスト以外でモデルを使用したい場合に有用です。特定のシナリオでは、新しいデータが利用可能になったときの予測や、傾向や季節性が似ている関連する時系列データの予測など、その有用性を示します。
シナリオ1: 同じ系列の新しいデータ
前の2つの例と同じ住宅データセットを使用することができますが、今回は経過した時間があり、2023年6月までのデータが利用可能になりました。
df = pdr.get_data_fred( 'CANWSCNDW01STSAM', start = '2010-01-01', end = '2023-06-30',)f_new = Forecaster( y = df.iloc[:,0], current_dates = df.index, future_dates = 24, # 2年間の予測期間)同じ変換を使用してパイプラインを再作成しますが、今回は通常のスケールキャスト予測手順の代わりに転移予測を使用します。転移予測手順ではモデルもフィットします:
def transfer_forecast(f_new,transfer_from): f_new = infer_apply_Xvar_selection(infer_from=transfer_from,apply_to=f_new) f_new.transfer_predict(transfer_from=transfer_from,model='rnn',model_type='tf')pipeline_can = Pipeline( steps = [ ('Transform',transformer), ('Transfer Forecast',transfer_forecast), ('Revert',reverter), ])f_new = pipeline_can.fit_predict(f_new,transfer_from=f)関連する関数の名前はまだfit_predict()ですが、実際にはパイプライン内ではフィッティングは行われず、予測のみが行われます。これにより、モデルの再フィットと再最適化にかかる時間が大幅に短縮されます。次に結果を表示します:
f_new.plot()plt.show('Housing Starts Forecast with Actuals Through June, 2023')plt.show()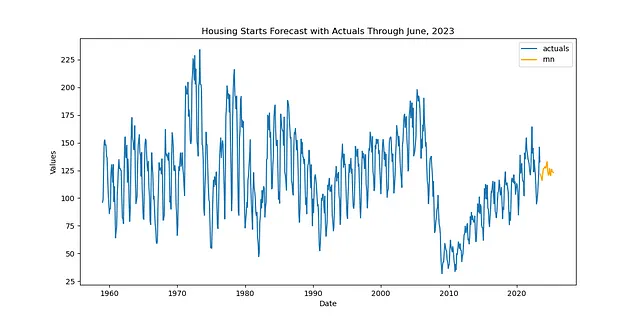
シナリオ2:類似した特性を持つ新しい時系列
2番目のシナリオでは、米国の住宅動向で訓練されたモデルを使用して、カナダの住宅着工数を予測するという仮想的な状況を考えることができます。免責事項:これが実際に良いアイデアかどうかはわかりません。ただし、これをデモンストレーションするために考えた1つのシナリオです。しかし、これは有用であり、関連するコードは他の状況にも転用できます(すでにパフォーマンスの良いモデルに適合したより長い系列と似た動学を持つ短い系列の場合など)。その場合、コードは実際にはシナリオ1のコードとまったく同じです。唯一の違いは、オブジェクトに読み込むデータです:
df = pdr.get_data_fred( 'CANWSCNDW01STSAM', start = '2010-01-01', end = '2023-06-30',)f_new = Forecaster( y = df.iloc[:,0], current_dates = df.index, future_dates = 24, # 2年間の予測の範囲)def transfer_forecast(f_new,transfer_from): f_new = infer_apply_Xvar_selection(infer_from=transfer_from,apply_to=f_new) f_new.transfer_predict(transfer_from=transfer_from,model='rnn',model_type='tf')pipeline_can = Pipeline( steps = [ ('Transform',transformer), ('Transfer Forecast',transfer_forecast), ('Revert',reverter), ])f_new = pipeline_can.fit_predict(f_new,transfer_from=f)f_new.plot()plt.show('Candian Housing Starts Forecast')plt.show()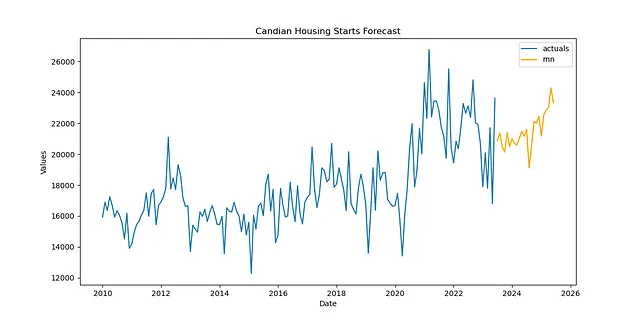
この予測は、LSTM転移学習の興味深い応用例として十分に信頼できると思います。
結論
多くの予測のユースケースにおいて、LSTMモデルは興味深い解決策となる場合があります。この記事では、Pythonコードを使用してLSTMモデルを5つの異なる目的に適用する方法を示しました。役に立った場合は、GitHubでscalecastにスターを付け、最新の情報を知るためにVoAGIで私をフォローしてください。このコードに対するフィードバック、建設的な批判、または質問がある場合は、お気軽にメールでお問い合わせください:[email protected]。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「生成タスクを分類タスクに変換する」
- 「ユナイテッド航空がコスト効率の高い光学文字認識アクティブラーニングパイプラインを構築した方法」
- 『NVIDIAのCEO、ジェンソン・ファング氏がテルアビブで開催されるAIサミットの主演を務めます』
- AIはクリエイティブな思考のタスクで人間を上回ることができるのか?この研究は人間と機械学習の創造性の関係についての洞察を提供します
- 「AIとブロックチェーンの交差点を探る:機会と課題」
- 「AIを活用した言語モデル(ChatGPTなど)を使用する際の倫理的考慮事項 💬」
- 「LLaMaをポケットに収めるトリック:LLMの効率とパフォーマンスを結ぶAIメソッド、OmniQuantに出会おう」