「5つの最高のオープンソースLLM」
5 best open source LLM
人工知能(AI)の急速な進化する世界では、Large Language Models(LLMs)が基盤となり、革新を推進し、技術とのやり取りの方法を再構築しています。
これらのモデルがますます洗練されるにつれ、それらへのアクセスを民主化することがますます重要になっています。特にオープンソースのモデルは、研究者、開発者、愛好家にとって、それらの複雑さに深く没頭したり、特定のタスクに適合させたり、さらにはその基盤を構築したりする機会を提供しています。
このブログでは、AIコミュニティで話題をさらっているトップオープンソースLLMsをいくつか紹介します。それぞれが独自の強みと機能を持ち、テーブルに持ち込んでいます。
1. Llama 2
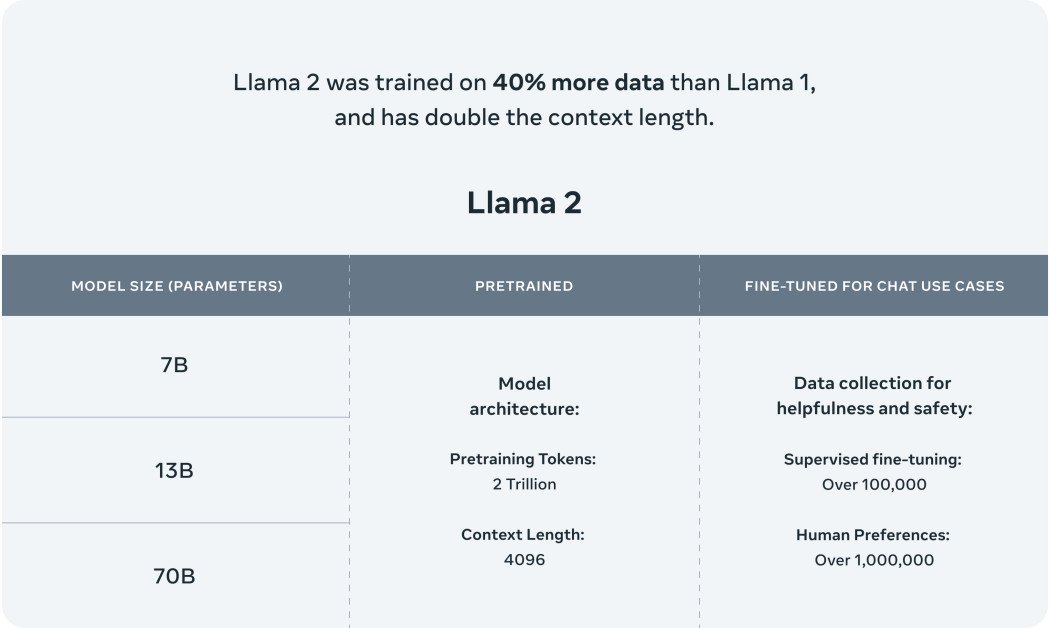
MetaのLlama 2は、彼らのAIモデルラインアップにおける画期的な追加です。これはただの別のモデルではありません。最先端のアプリケーションを推進するために設計されています。 Llama 2のトレーニングデータは広範で多様であり、これにより、その前身よりも大幅に進歩しています。このトレーニングの多様性により、Llama 2は単なる改善ではなく、AI駆動の相互作用の将来に向けた重要な一歩となっています。
MetaとMicrosoftの協力関係は、Llama 2の可能性を広げました。このオープンソースモデルは、AzureやWindowsなどのプラットフォームでサポートされており、開発者や組織が生成的なAI駆動のエクスペリエンスを作成するためのツールを提供することを目指しています。このパートナーシップは、AIをよりアクセス可能で開放的にするという両社の取り組みを裏付けています。
Llama 2は、元のLlamaモデルの後継者にすぎません。それはチャットボットの領域におけるパラダイムシフトを表しています。最初のLlamaモデルは、テキストとコードの生成において革命的でしたが、誤用を防ぐためにその利用は制限されていました。一方、Llama 2は、より広範なユーザーに届くことになりました。AWS、Azure、Hugging FaceのAIモデルホスティングプラットフォームなどのプラットフォームに最適化されています。また、MetaとMicrosoftの協力関係により、Llama 2はWindowsだけでなく、QualcommのSnapdragonシステムオンチップを搭載したデバイスにも影響を与えることになります。
Llama 2の設計には安全性が重要です。GPTなど、以前の大規模言語モデルが時に誤解を招いたり有害なコンテンツを生成したりするという課題を認識し、MetaはLlama 2の信頼性を確保するために徹底した対策を講じています。モデルは「幻想」、誤情報、バイアスを最小限に抑えるために厳格なトレーニングを受けています。
LLaMa 2の主な特徴:
- 多様なトレーニングデータ: Llama 2のトレーニングデータは幅広く多様であり、包括的な理解とパフォーマンスを保証しています。
- Microsoftとの協力: Llama 2はAzureやWindowsなどのプラットフォームでサポートされており、その応用範囲が広がっています。
- オープンな提供: 先代のLlamaとは異なり、Llama 2はより広範なユーザーに提供され、複数のプラットフォームでの微調整に対応しています。
- 安全性を重視した設計: Metaは安全性を重視し、Llama 2が正確かつ信頼性の高い結果を生成する一方で、有害な出力を最小限に抑えるようにしています。
- 最適化されたバージョン: Llama 2には2つの主要なバージョンがあります。Llama 2とLlama 2-Chatで、後者は特に双方向の会話に特化しています。これらのバージョンは、70億パラメータから700億パラメータまでの複雑さを持っています。
- 強化されたトレーニング: Llama 2は、元のLlamaの1.4兆トークンから、200万トークンでトレーニングされました。
2. Claude 2

Anthropicの最新のAIモデル、Claude 2は、単なるアップグレードではなく、AIモデルの能力の大幅な向上を表しています。強化されたパフォーマンスメトリックを備えたClaude 2は、ユーザーに拡張された一貫した応答を提供するよう設計されています。このモデルのアクセス性は広範であり、APIと専用のベータウェブサイトの両方を通じて利用できます。ユーザーフィードバックによれば、Claudeとのインタラクションは直感的であり、モデルは詳細な説明を提供し、拡張されたメモリ容量を示しています。
学術的および推論能力において、Claude 2は注目すべき成果を上げています。モデルはバー試験の多肢選択問題の部分で76.5%のスコアを獲得し、Claude 1.3の73.0%からの向上を示しています。大学院プログラムの準備をする大学生と比較した場合、Claude 2はGREのリーディングとライティング試験で90パーセンタイル以上の成績を収め、複雑な内容の理解と生成における熟練度を示しています。
クロード2の柔軟性も注目に値します。このモデルは最大100,000トークンの入力を処理することができ、技術マニュアルから包括的な書籍まで幅広い文書をレビューすることができます。さらに、クロード2は公式なコミュニケーションから詳細な物語まで、シームレスに拡張文書を生成する能力を持っています。また、クロード2のコーディング能力も向上し、Pythonのコーディング評価で71.2%、学校の数学の課題であるGSM8kで88.0%のスコアを達成しました。
安全性はAnthropicにとって重要な関心事です。クロード2が潜在的に有害または不適切なコンテンツを生成しにくいようにするために、努力が集中しています。緻密な内部評価と高度な安全性の手法の適用により、クロード2は前任者と比較して有害な応答を生成する可能性が著しく低下したことが示されています。
クロード2の主な特徴の概要
- パフォーマンスの向上: クロード2はより高速な応答時間を提供し、より詳細な対話を可能にします。
- 複数のアクセスポイント: このモデルはAPIまたは専用のベータウェブサイトclaude.aiを介してアクセスできます。
- 学術的な卓越性: クロード2はGREの読解とライティングのセグメントで優れた結果を示しました。
- 拡張入出力の能力: クロード2は最大100,000トークンの入力を処理し、1回のセッションで拡張文書を生成する能力があります。
- 高度なコーディングの熟練度: このモデルのコーディングスキルは改善され、コーディングと数学の評価でのスコアが証明しています。
- 安全性のプロトコル: クロード2が有害な出力を生成しないようにするために、厳格な評価と高度な安全技術が採用されています。
- 拡大計画: クロード2は現在、米国と英国で利用可能ですが、近い将来、その利用範囲をグローバルに拡大する予定です。
3. MPT-7B

MosaicML Foundationsは、最新のオープンソースLLMであるMPT-7Bを導入することで、この分野に大きな貢献をしています。MPT-7Bは、MosaicML Pretrained Transformerの頭字語であり、GPTスタイルのデコーダー専用トランスフォーマーモデルです。このモデルには、パフォーマンスを最適化したレイヤーの実装や、トレーニングの安定性を確保するためのアーキテクチャの変更など、いくつかの改良が施されています。
MPT-7Bの特筆すべき特徴の一つは、1兆トークンのテキストとコードから成る広範なデータセットでのトレーニングです。この厳格なトレーニングは、9.5日間のMosaicMLプラットフォーム上で実行されました。
MPT-7Bのオープンソースの性質は、商業アプリケーションにとって貴重なツールと位置付けています。これは予測分析やビジネスや組織の意思決定プロセスに大きな影響を与える可能性を持っています。
ベースモデルに加えて、MosaicML Foundationsは特定のタスクに対応した専門モデルもリリースしており、例えば短いフォームの指示に従うためのMPT-7B-Instructや対話生成のためのMPT-7B-Chat、長い形式のストーリー作成のためのMPT-7B-StoryWriter-65k+などがあります。
MPT-7Bの開発の過程は包括的であり、MosaicMLチームがデータの準備から展開までの各段階を数週間で管理しました。データはさまざまなリポジトリから取得され、EleutherAIのGPT-NeoXや20Bのトークナイザーなどのツールを利用して、多様で包括的なトレーニングミックスが確保されました。
MPT-7Bの主な特徴の概要:
- 商用ライセンス: MPT-7Bは商業利用のためにライセンスされており、ビジネスにとって価値のある資産です。
- 広範なトレーニングデータ: このモデルは1兆トークンの広範なデータセットでトレーニングされています。
- 長い入力の処理: MPT-7Bは妥協することなく非常に長い入力を処理するために設計されています。
- 速度と効率性: このモデルは迅速なトレーニングと推論のために最適化されており、タイムリーな結果を保証します。
- オープンソースコード: MPT-7Bには効率的なオープンソースのトレーニングコードが付属しており、透明性と使いやすさを促進しています。
- 比較的な卓越性: MPT-7Bは7B-20Bの範囲の他のオープンソースモデルに対して優位性を示し、その品質はLLaMA-7Bに匹敵します。
4. Falcon(ファルコン)

Falcon LLM(ファルコンLLM)は、LLMの階層で迅速にトップに上昇したモデルです。特にFalcon-40Bは、400億のパラメータを備えた基礎的なLLMであり、1兆のトークンでトレーニングされました。これは、直前のトークンに基づいてシーケンス内の次のトークンを予測する、自己回帰デコーダーモデルとして動作します。このアーキテクチャはGPTモデルを思い起こさせます。特筆すべきは、FalconのアーキテクチャがGPT-3よりも優れたパフォーマンスを示しており、トレーニングコンピュート予算の75%のみを使用して推論時にはかなり少ないコンピュートを必要としていることです。
Technology Innovation Instituteのチームは、Falconの開発中にデータの品質に重点を置いています。LLMがトレーニングデータの品質に対して敏感であることを認識し、彼らは数万のCPUコアにスケールするデータパイプラインを構築しました。これにより、迅速な処理とウェブからの高品質なコンテンツの抽出が可能となりました。このデータパイプラインは、広範なフィルタリングと重複排除のプロセスを経て実現されました。
Falcon-40Bに加えて、TIIはFalcon-7Bなどの他のバージョンも導入しています。Falcon-7Bは70億のパラメータを備え、1500億のトークンでトレーニングされています。Falcon-40B-InstructやFalcon-7B-Instructなどの専門モデルもあります。
Falcon-40Bのトレーニングは、広範なプロセスで行われました。モデルは、TIIが構築した巨大な英語のウェブデータセットであるRefinedWebデータセットでトレーニングされました。このデータセットはCommonCrawlの上に構築され、品質を保証するために厳格なフィルタリングが行われました。モデルの準備が整った後、EAI Harness、HELM、BigBenchなどのいくつかのオープンソースのベンチマークに対して検証が行われました。
Falcon LLMの主な特徴の概要:
- 広範なパラメータ: Falcon-40Bは400億のパラメータを備えており、包括的な学習とパフォーマンスを保証しています。
- 自己回帰デコーダーモデル: このアーキテクチャにより、FalconはGPTモデルと同様に、直前のトークンに基づいて次のトークンを予測することができます。
- 優れたパフォーマンス: Falconは、トレーニングのコンピュート予算の75%のみを使用しながら、GPT-3を上回るパフォーマンスを発揮します。
- 高品質のデータパイプライン: TIIのデータパイプラインは、モデルのトレーニングに不可欠なウェブからの高品質なコンテンツの抽出を保証します。
- 多様なモデル: Falcon-40Bに加えて、TIIではFalcon-7BやFalcon-40B-Instruct、Falcon-7B-Instructなどの専門モデルも提供しています。
- オープンソースの利用可能性: Falcon LLMはオープンソース化されており、AIの領域でのアクセシビリティと包括性を促進しています。
Vicuna-13B(ビクーニャ13B)

LMSYS ORGは、Vicuna-13Bの導入により、オープンソースのLLMの領域で大きな影響を与えました。このオープンソースのチャットボットは、LLaMAをユーザー共有のShareGPTからの会話を微調整することで緻密にトレーニングされました。GPT-4を審査員として使用した予備評価では、Vicuna-13BがOpenAI ChatGPTやGoogle Bardなどの有名なモデルの品質の90%以上を達成していることが示されています。
驚くべきことに、Vicuna-13Bは、LLaMAやStanford Alpacaなどの他の注目すべきモデルを90%以上のケースで上回っています。Vicuna-13Bのトレーニング全体の費用は約300ドルで実行されました。その能力を探求したい人々のために、コード、ウェイト、オンラインデモが非営利目的で公開されています。
Vicuna-13Bモデルは、70,000件のユーザー共有のChatGPT会話で微調整されており、より詳細でよく構造化された応答を生成することができます。これらの応答の品質はChatGPTと比較可能です。ただし、チャットボットの評価は複雑な作業です。GPT-4の進化により、ベンチマーク生成やパフォーマンス評価のための自動評価フレームワークとしての潜在能力についての興味が高まっています。GPT-4に基づく予備評価では、VicunaはBard/ChatGPTなどのモデルの能力の90%を達成しています。
Vicuna-13Bの主な特徴の概要:
- オープンソース性: Vicuna-13Bは一般の方々もアクセスできるように公開されており、透明性とコミュニティの参加を促進しています。
- 豊富なトレーニングデータ:このモデルは、70,000件のユーザー間で共有された会話を基にトレーニングされており、多様なインタラクションの包括的な理解が可能です。
- 競争力のあるパフォーマンス: Vicuna-13Bのパフォーマンスは、ChatGPTやGoogle Bardなどの業界のリーダーと同等です。
- 効率的なトレーニング: Vicuna-13Bのトレーニングプロセス全体は、約$300という低コストで実行されました。
- LLaMAでのファインチューニング:このモデルはLLaMAでファインチューニングされており、パフォーマンスと応答品質が向上しています。
- オンラインデモの提供:ユーザーは対話型のオンラインデモを利用してVicuna-13Bの機能をテストし、体験することができます。
大規模言語モデルの拡大する領域
大規模言語モデルの領域は広大で絶えず拡大し、新しいモデルごとに可能性の限界を押し上げています。このブログで紹介されているLLMのオープンソース性は、AIコミュニティの協力的な精神を示すだけでなく、将来のイノベーションの道を切り開いています。
Vicunaの印象的なチャットボットの能力からFalconの優れたパフォーマンス指標まで、これらのモデルは現在のLLM技術の頂点を代表しています。この分野で急速な進歩を目撃しながら、オープンソースモデルがAIの未来を形作る重要な役割を果たすことは明らかです。
熟練した研究者、新たなAI愛好家、またはこれらのモデルのポテンシャルに興味を持つ方々にとって、これらの広大な可能性を探求するのに最適な時期と言えます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






