GPTQによる4ビット量子化
4ビット量子化 by GPTQ
AutoGPTQを使用して独自のLLMを量子化する
重み量子化の最近の進歩により、私たちはGPTQ、GGML、およびNF4のような性能低下が最小限の4ビット量子化技術を使用して、LLaMA-30BモデルをRTX 3090 GPU上の一般消費者向けハードウェアで実行することができるようになりました。
前の記事では、素朴な8ビット量子化技術と優れたLLM.int8()を紹介しました。今回の記事では、人気のあるGPTQアルゴリズムを探求し、AutoGPTQライブラリを使用して実装してみます。
コードはGoogle ColabとGitHubで見つけることができます。
🧠 最適な脳量子化
まず、解決しようとしている問題を紹介しましょう。ネットワークの各層ℓに対して、元の重みWₗの量子化バージョンŴₗを見つけたいとします。これを層ごとの圧縮問題と呼びます。具体的には、性能低下を最小限に抑えるために、これらの新しい重みの出力(ŴᵨXᵨ)が元の出力(WᵨXᵨ)にできるだけ近くなるようにしたいとします。つまり、次のようなものを見つけたいとします:
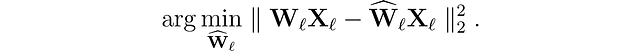
この問題を解決するためにはさまざまなアプローチが提案されていますが、ここでは最適な脳量子化(OBQ)フレームワークに興味があります。
このメソッドは、完全にトレーニングされた密なニューラルネットワークから重みを慎重に削除するための剪定技術(Optimal Brain Surgeon)に触発されています。これは近似技術を使用し、最良の単一の重みw𐞥を削除するための明示的な式と、残りの非量子化された重みFを調整するための最適な更新δꟳを提供します:
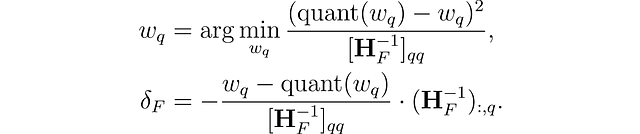
ここで、quant(w)は量子化による重みの丸めを表し、Hꟳはヘッシアンです。
OBQを使用することで、最も簡単な重みを最初に量子化し、その精度損失を補うために残りの非量子化重みFを調整します。次に、次の重みを量子化し、以降の作業を続けます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






