「大規模言語モデルを改善するための簡単な方法3つ」
3 simple methods to improve large-scale language models
Llama 2のパワーアップ

大規模言語モデル(LLM)は今後も存在し続けます。最近のLlama 2のリリースにより、オープンソースのLLMはChatGPTの性能に近づき、適切なチューニングによりそれを上回ることさえ可能です。
これらのLLMを使用することは、特にLLMを特定のユースケースに適用する場合には簡単なものではありません。
この記事では、任意のLLMのパフォーマンスを向上させるための3つの最も一般的な方法について説明します:
- 「視覚化された実装と共に、Graph Attention Network(GAT)の解説」
- 「BLIVAと出会ってください:テキスト豊かなビジュアル質問をより良く扱うためのマルチモーダルな大規模言語モデル」
- 「機械学習の謎を解く」
- プロンプトエンジニアリング
- リトリーバル増強生成(RAG)
- パラメータ効率的なファインチューニング(PEFT)

他にも多くの方法がありますが、これらは簡単で、手間をかけずに大幅な改善が得られる方法です。
これらの3つの方法は、複雑度が低いとされる方法から始まり、LLMを改善するためのより複雑な方法の1つまでを網羅しています。
LLMを最大限に活用するためには、3つの方法を組み合わせることもできます!
始める前に、簡単な参照のために各方法の詳細な概要を以下に示します:
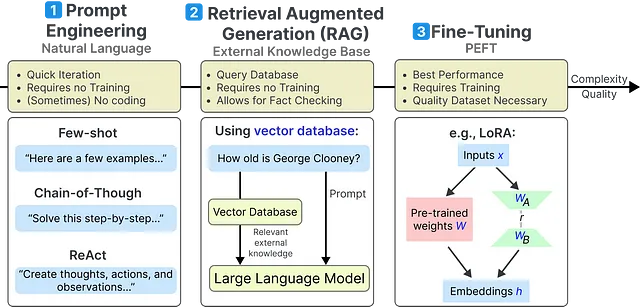
また、意図した通りにすべてが機能することを確認するために、Google Colabノートブックに従って進めることもできます。
Llama 2の読み込み 🦙
始める前に、これらの例で使用するLLMを読み込む必要があります。チュートリアルでは基本的なLlama 2を使用することにします。これは非常に優れたパフォーマンスを示しており、私は基礎モデルを使用することに大いに賛成です。
始める前に、次の手順に従ってライセンスを受け入れる必要があります:
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






