「生成モデルを本番環境に展開する際の3つの課題」
3 challenges when deploying generative models in production environments.
大規模言語および拡散モデルをユーザーを怖がらせずに製品に展開する方法

OpenAI、Google、Microsoft、Midjourney、StabilityAI、CharacterAIなど、誰もがテキストからテキスト、テキストから画像、画像から画像、画像からテキストのモデルのための最良のソリューションを提供するために競い合っています。
その理由は単純です-この領域が提供する機会の広範さです。エンターテイメントだけでなく、ロック解除が不可能だったユーティリティも含まれます。より優れた検索エンジンから、印象的で個人化された広告キャンペーン、SnapのMyAIのようなフレンドリーなチャットボットまで。
この領域は非常に流動的で、多くの移動部品とモデルチェックポイントが数日ごとにリリースされていますが、生成AIを使用するすべての会社が解決しようとしている課題があります。
ここでは、生成モデルを本番環境に展開する際の主な課題とその対処方法について説明します。生成モデルにはさまざまな種類がありますが、この記事では拡散およびGPTベースのモデルの最近の進歩に焦点を当てます。ただし、ここで議論されている多くのトピックは他のモデルにも適用できます。
- 「Javaプログラミングの未来:2023年に注目すべき5つのトレンド」
- 「人工知能(AI)とWeb3:どのように関連しているのか?」
- AWSは、大規模なゲーミング会社のために、Large Language Model (LLM) を使って有害なスピーチを分類するためのファインチューニングを行います
生成AIとは何ですか?
生成AIは、新しいコンテンツを生成できるモデルのセットを広く説明します。広く知られている生成対抗ネットワーク(GAN)は、実データの分布を学習し、追加されたノイズから変動性を生成することによってそれを行います。
生成AIの最近のブームは、モデルがスケールで人間レベルの品質を達成していることから来ています。この変革を解除する理由は単純です-私たちは今や十分な計算能力(つまり、NVIDIAの急騰株価)を持っており、高品質な結果を達成するための十分な容量を持つモデルのトレーニングとメンテナンスが可能になりました。現在の進歩は、トランスフォーマーや拡散モデルという2つの基本アーキテクチャによって推進されています。
最近の年における最も重要なブレイクスルーの一つは、OpenAIのChatGPTです。ChatGPTはテキストベースの生成モデルであり、最新のChatGPT-3.5バージョンではさまざまなトピックで会話を維持するための十分な知識ベースを持っています。ChatGPTは単一のモダリティモデルですが、テキストと画像のような複数の種類の入力と出力を受け取ることができるマルチモーダルモデルも存在します。
画像からテキストおよびテキストから画像のマルチモーダルアーキテクチャは、テキストと画像のコンセプトと共有される潜在空間で操作されます。この潜在空間は、両方のコンセプト(例:画像キャプション)を必要とするタスクでトレーニングすることによって得られ、異なるモダリティの同じコンセプト間の潜在空間の距離を罰則化します。この潜在空間が得られると、他のタスクに再利用することができます。
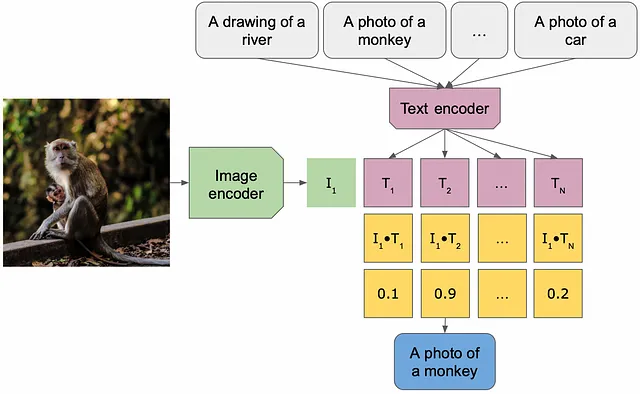
今年リリースされた注目すべき生成モデルには、DALLE / Stable-Diffusion(テキストから画像/画像から画像)およびBLIP(画像からテキストの実装)があります。DALLEモデルは、プロンプトまたは画像とプロンプトを入力として受け取り、応答として画像を生成します。一方、BLIPベースのモデルは、画像の内容に関する質問に答えることができます。
課題と解決策
残念ながら、機械学習には無料の昼食はありませんし、大規模な生成モデルは本番環境でいくつかの課題に直面します-サイズとレイテンシ、バイアスと公平性、生成された結果の品質。
モデルのサイズとレイテンシ
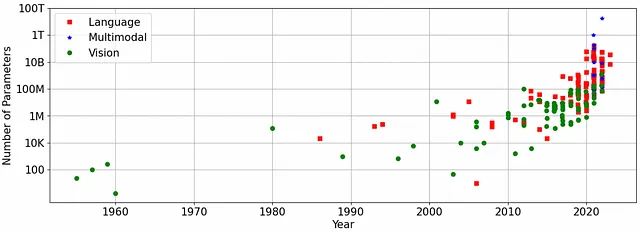
最先端のGenAIモデルは非常に大きいです。たとえば、テキストからテキストへのMetaのLLaMAモデルは7から65億のパラメータを持ち、ChatGPT-3.5は1750億のパラメータを持っています。これらの数字は正当化されています。簡略化された世界では、モデルが大きいほど、トレーニングに使用されるデータ量が多く、品質も良くなります。
テキストから画像へのモデルは、それまでの生成的対抗ネットワークの前任者よりもかなり大きくなっています。Stable Diffusion 1.5のチェックポイントは1Bパラメータ未満です(3GBのスペースを占有します)、DALLE 2.0は3.5Bのパラメータを持っています。これらのモデルを維持するためには、ほとんどのGPUには十分なメモリがありません。通常は複数の大規模モデルを維持するためのフリートが必要であり、非常に高額になる可能性があります。さらに、これらのモデルをモバイルデバイスに展開することについては言及するまでもありません。
生成モデルは出力を生成するのに時間がかかります。いくつかの場合、遅延はモデルの大きさによるものです。数十億のパラメータを複数のGPUフリートに伝播させるためには時間がかかります。また、他の場合には、高品質な結果を生成するための反復的な性質によるものです。デフォルトの設定のDiffusionモデルでは、画像を生成するために50ステップが必要です。ステップ数を減らすと、出力画像の品質が低下します。
解決策:モデルを小さくすると、より高速になることがよくあります。モデルを蒸留、圧縮、量子化することも遅延を減らすことができます。Qualcommは安定したディフュージョンモデルを圧縮してモバイルに展開する道を開拓しました。最近、Stable Diffusion(tinyとsmall)のより小さく蒸留されたバージョンがリリースされました。
モデル固有の最適化も推論の高速化に役立ちます。ディフュージョンモデルの場合、低解像度の出力を生成してから拡大するか、ステップ数を減らして別のスケジューラを使用することがあります。なぜなら、ステップ数が少ない方が最適な結果が得られる場合もあれば、より多くの反復回数で優れた品質の結果が得られる場合もあるからです。Snapは最近、Stable Diffusion 1.5で8ステップで高品質の結果を作成できることを示しました。これはトレーニング時にさまざまな最適化を行っています。
たとえば、NVIDIAのtensorrtとtorch.compileでモデルをコンパイルすると、最小限のエンジニアリング努力で遅延を大幅に削減できます。
エッジ上でのモバイルへの深層学習アプリケーションの展開
制約のあるデバイス上の深層ニューラルネットワークの効率と精度のトレードオフに関するテクニック
towardsdatascience.com
バイアス、公正さ、安全性
ChatGPTを壊すことを試みたことはありますか?多くの人々がバイアスや公正さの問題を明らかにし、OpenAIはこれらに対処するために素晴らしい仕事をしています。スケールでの修正がない場合、チャットボットは有害で安全でないアイデアや行動を広めて現実世界の問題を引き起こす可能性があります。
モデルを壊した例は政治の領域にあります。たとえば、ChatGPTはトランプについての詩を作成することを拒否しましたが、バイデンについての詩は作成しました。また、ジェンダー平等や職業に関しても同様です。特定の職業が男性向けまたは女性向けであると暗示するものです。
テキストからテキストモデルと同様に、テキストから画像や画像からテキストへのモデルにもバイアスや公正さの問題があります。Stable Diffusion 2.1モデルは、医師と看護師の画像を生成するように求められた場合、前者には白人男性を、後者には白人女性を生成します。興味深いことに、バイアスはプロンプトで指定された国に依存します。たとえば、日本の医師やブラジルの看護師などです。


BLIP画像からテキストモデルを使って、太った人や男性と女性の医師の画像を与えると、偏見のある画像の説明が得られることがあります。「太った男性」「男性の医師」「白衣と聴診器を着た女性」などです。


![著者によって生成された画像。左から右に [1] アイスクリームを食べる太った男性; [2] 白衣とネクタイを着た男性医師; [3] 白い白衣を着た女性が首に聴診器を掛けています。これらの画像は、著者によってSD 2.1インターフェースで生成され、BLIPを通過しました。](https://miro.medium.com/v2/resize:fit:640/format:webp/1*SU00ELFCZ4fNW8wTbKcDyw.png)
問題のテスト方法: これはかなり診断が難しい問題です。多くの場合、何を探すかを知る必要があります。各回答に対して、問題が発生する場合と発生しない場合のテンプレート応答や警告フラグを検出するための幅広いプロンプトを備えた別のベンチマークデータセット、さらにはさまざまなバックグラウンドと複数のシナリオの人間のデータセットを使用して、写真の人物に関するすべての可能な属性を保存する必要があります。これらのデータセットは、信頼性のある統計情報を得るために数十万のエントリを持つ必要があります。
解決策: ほとんどのバイアス、公平性、および安全性の問題は、トレーニングデータから発生します。 AIモデルは、私たちのバイアスを助長する人間性の鏡であるというアナロジーが好きです。クリーンでバイアスのないデータでトレーニングすると、結果は劇的に改善されます。ただし、これらのモデルでも間違いが発生することがあります。
結果の事後処理とフィルタリングは、別の可能な解決策です。たとえば、ヌード画像を含むデータでトレーニングされたStable Diffusionには、潜在的な問題を検出するためのNSFWコンテンツ検出器があります。テキストからテキストへのモデルの出力にも同様のフィルタを適用できます。
出力の品質、関連性、および正確性
生成モデルは、ユーザーの要求を解釈する際に非常に創造的になることがあります。最近の大規模モデルは人間レベルの品質に達していますが、それぞれのユースケースにおいて、そのままではうまく機能しないため、追加の微調整やプロンプトエンジニアリングが必要です。
初期の非常に限定された画像からテキストへのモデルやテキストからテキストへのモデルの品質評価は比較的簡単でした。つまり、ギブリッシュよりも改善された結果は明らかです。高品質の生成モデルは、誤った情報や時代遅れの情報を自信を持って出力するなど、検出が難しい振る舞いを始めます。
拡散モデルは、出力の欠点を他の方法で示します。画像ベースのモデルに起因する一般的な問題は、破損したジオメトリ、変異した解剖学、プロンプトと画像の結果の不一致、肌の色や性別の不一致です。美的感覚とリアリズムの自動評価は遅れており、FIDなどの一般的なメトリックではこれらのバリエーションを捉えることができません。


![左から右に:[1] 抱擁する2人の人物; [2] サムズアップをしている男性; [3] 犬が公園で走っています。著者によって生成されたStable Diffusion 1.5の画像](https://miro.medium.com/v2/resize:fit:640/format:webp/1*tyh1KGXnbEMtGszdyE6WKg.png)
問題のテスト方法: 生成モデルの品質をテストすることは困難です。なぜなら、これらのモデルには基準となる真実がないからです。これらのモデルは新しい出力を提供するために作られているため、品質の側面を信頼できるメトリックで捉えることはできません。最も信頼性の高いメトリックは人間の評価です。
バイアスと公正性の評価と同様に、品質をテストするためには、大量のプロンプトと画像のデータセットを用意するのが最善の方法です。テキスト対テキストモデルは個別のユーザーに合わせてパーソナライズされることが増えており、対話の一貫性だけでなく、正確性と関連性も評価したいと考えるでしょう。また、会話に関する情報をどれだけ記憶できるかも評価したいと思うでしょう。
解決策: 品質の問題の多くはトレーニングデータとモデルのサイズに起因する可能性があります。品質の向上には、トレーニングデータの改善が必要です。テキスト対テキストおよびテキスト対画像のためのプロンプトの増強、およびテキスト対画像モデルのためのネガティブプロンプトなどが問題の解決に役立つでしょう。
テキスト対画像および画像対画像モデルには、品質を向上させるための追加ツールがあります。伝統的な深層学習手法や拡散ベースのリファイナーを使用した画像の強化がその一例です。ControlNetや拡散アーキテクチャに対して直交するような追加モジュールは、生成された結果に対する追加の制御を支援することができます。特定のアプリケーションにモデルを微調整するためのDreambooth技術も結果の向上に役立ちます。スケジューラ、CFG、および拡散ステップ数などの追加パラメータを調整することは、品質に大きな影響を与えることがあります。
要約
生成モデルは、AIレンズやより優れた検索エンジン、共同パイロット、広告など、楽しいアプリケーションと商業用途の新たな可能性を開拓しました。同時に、企業が製品を急いでリリースし、消費者が新しい機能に興奮する一方で、技術の明らかな欠陥が見落とされることがあります。
また、モデルのベンチマークをより透明にするために大規模なオープンソースのデータセット、トレーニングコード、評価結果を公開するという一般的な動きがありますが、大規模なAIモデルの厳格な規制も求められています。理想的な世界では、両者は極端にならずにお互いを補完し、AIの安全性と利便性を向上させることができるでしょう。
著者が気に入りましたか? つながりましょう!
何か見落としましたか? リンクトインまたはTwitterでメモ、コメント、または直接メッセージを残してください!
深層画像品質評価
主観的な画像品質評価から深層目的評価への深堀り
towardsdatascience.com
深層画像修復の知覚損失
平均二乗誤差からGANまで-良い知覚損失関数の特徴
towardsdatascience.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- AIの力による教育:パーソナライズされた成功のための学習の変革
- 一貫性のあるAIビデオエディターが登場しました:TokenFlowは、一貫性のあるビデオ編集のために拡散特徴を使用するAIモデルです
- 「メタに立ち向かい、開発者を強力にサポートするために、アリババがAIモデルをオープンソース化」
- 「CT2Hairに会ってください:ダウンストリームグラフィックスアプリケーションで使用するために適した高精細な3Dヘアモデルを完全自動で作成するフレームワーク」
- 「Jupyter AIに会おう:マジックコマンドとチャットインターフェースでジェネラティブ人工知能をJupyterノートブックにもたらす新しいオープンソースプロジェクト」
- 「OpenAIを任意のLLM(Language Model)と交換し、すべてを1行で行うことを想像してください!Genoss GPTに会ってください:OpenAI SDKと互換性のあるAPIで、GPT4ALLなどのオープンソースモデルをベースにして構築されています」
- メタのラマ2:商業利用のためのオープンソース言語モデルの革命化






