「これらの3つのあまり知られていないPandasの関数を試してみてください」
3つのあまり知られていないPandasの関数を試してみてください
Pandasを使用してデータ処理スキルを向上させる
経験豊富なデータサイエンティストや機械学習エンジニアに尋ねると、彼らの仕事で最も時間がかかるのは何でしょうか?多くの人が答えるでしょう:データの前処理 — データを整理し、順次データ分析のために準備するステップです。その理由はシンプルです — ゴミを入れればゴミを出すことになります。つまり、データを正しく準備しないと、データの「洞察」はほとんど意味を成しません。
データの前処理ステップはかなり手間がかかるかもしれませんが、Pandasは私たちが比較的簡単にデータのクリーンアップ作業を完了させるためのすべての必要な機能を提供しています。ただし、その汎用性のため、すべてのユーザーがpandasライブラリが提供するすべての機能を知っているわけではありません。この記事では、データサイエンスプロジェクトで試すことができる3つのあまり知られていないが非常に便利な関数を共有したいと思います。
それでは、さっそく見てみましょう。
注意:文脈を提供するために、衣料品店のデータ管理と分析を担当していると仮定します。以下に示す例はこの仮定に基づいています。
- 「Pythonコードを使用したダイレクトマーケティングキャンペーンの階層クラスタリングの実装方法」
- 「品質と信頼性のためのPythonコードのユニットテスト」
- PythonとDashを使用してダッシュボードを作成する
1. explode
最初に紹介したい関数はexplodeです。この関数は、リストを含む列のデータを扱う場合に役立ちます。この列にexplodeを使用すると、リストの各要素を別々の行に抽出して複数の行を作成します。
以下は、explode関数の使用方法を示すシンプルなコード例です。注文情報を格納するデータフレームがあると仮定します。このテーブルでは、以下のようにアイテムのリストを含む列(order列)があります:
order_data = { 'customer': ['John', 'Zoe', 'Mike'], 'order': [['Shoes', 'Pants', 'Caps'], ['Jackets', 'Shorts'], ['Ties', 'Hoodies']]}order_df = pd.DataFrame(order_data)order_df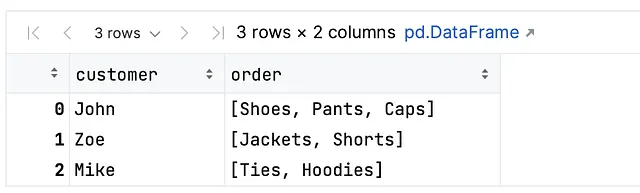
必要な操作は、リストの各アイテムを別々の行に分割してさらなるデータ処理を行うことです。explodeを使用せずに、素朴な解決策は以下の通りです。単純に元の行を反復します…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






